
Machine Learning
El módulo sklearn.multiclass implementa meta-estimuladores para resolver problemas de clasificación multiclase y multilabel descomponiendo dichos problemas en problemas de clasificación binaria. También se admite la regresión multiobjetivo. Clasificación multiclase significa una tarea de clasificación con más de dos clases; por ejemplo, clasificar un conjunto de imágenes de frutas que pueden ser naranjas, manzanas o peras. […]
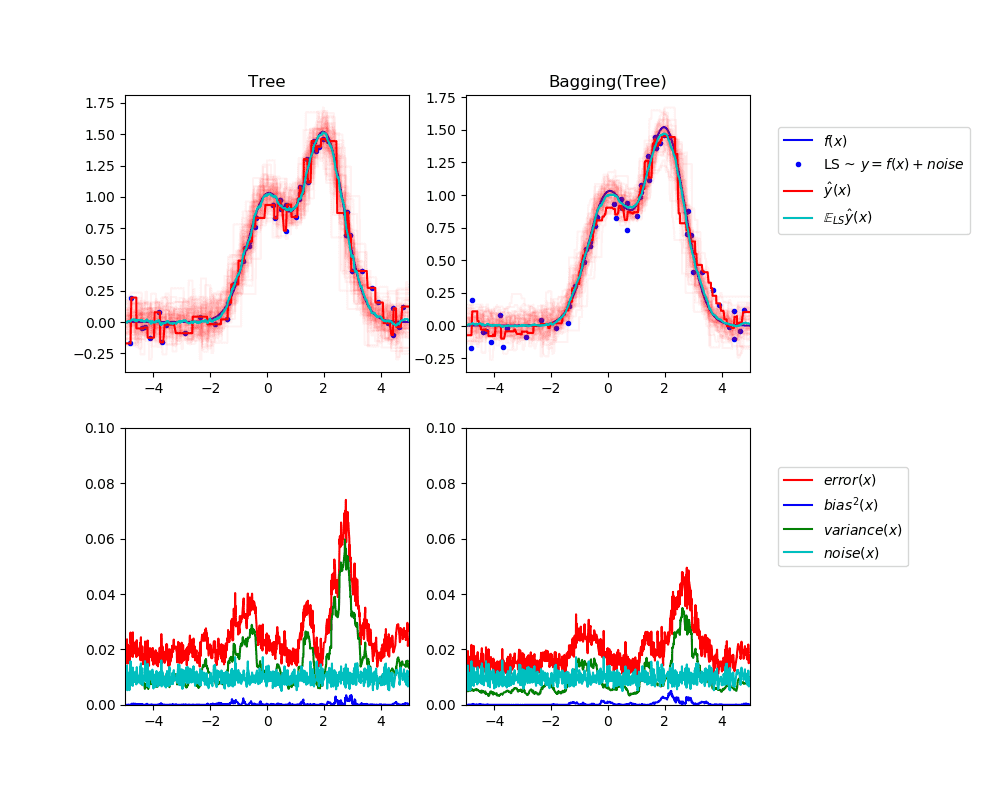
El objetivo de los métodos de conjunto es combinar las predicciones de varios estimadores de base construidos con un algoritmo de aprendizaje dado para mejorar la generalizabilidad/robustez sobre un solo estimador. Por lo general, se distinguen dos familias de métodos de ensamblaje: En los métodos de promediación, el principio rector es construir varios estimadores independientemente […]
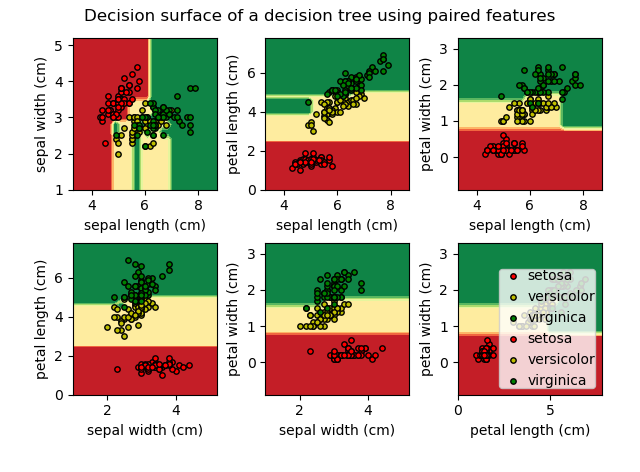
Los Árboles de Decisión (DTs) son un método de aprendizaje supervisado no paramétrico utilizado para la clasificación y regresión. El objetivo es crear un modelo que prediga el valor de una variable objetivo mediante el aprendizaje de reglas de decisión simples inferidas a partir de las características de los datos. Por ejemplo, en el ejemplo […]
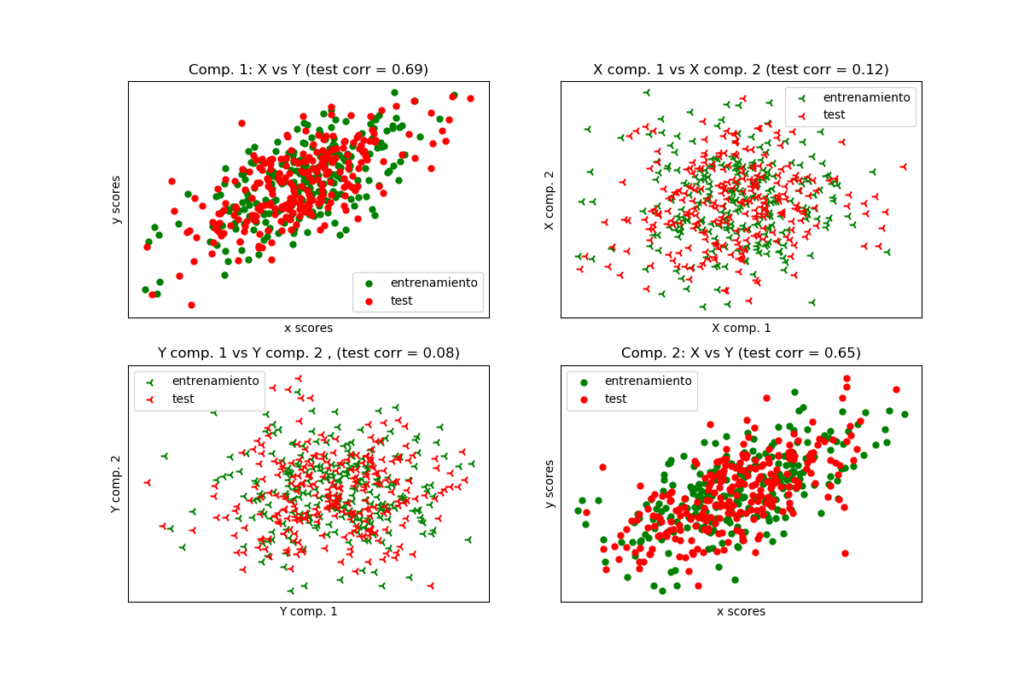
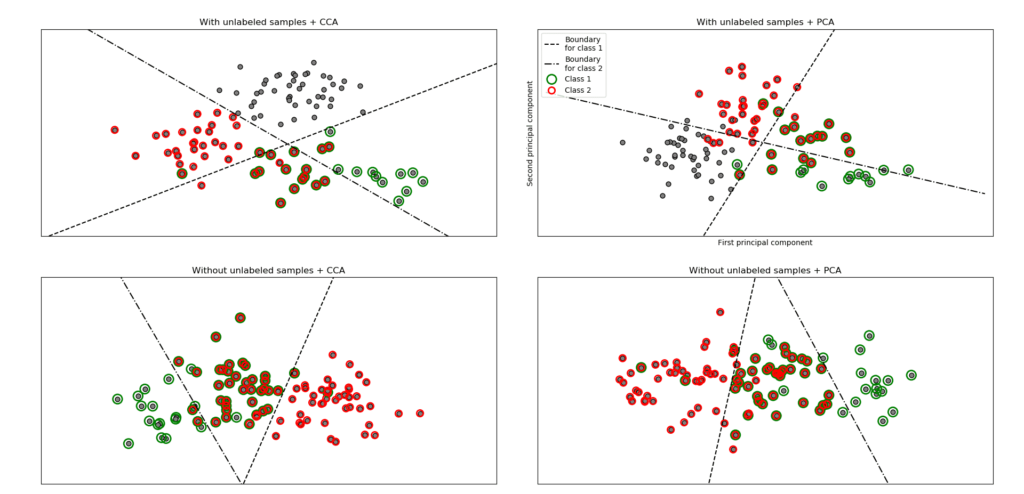
El módulo de descomposición cruzada contiene dos familias principales de algoritmos: los mínimos cuadrados parciales (PLS) y el análisis de correlación canónica (CCA). Estas familias de algoritmos son útiles para encontrar relaciones lineales entre dos conjuntos de datos multivariados: los argumentos X e Y del método fit son matrices 2D. Los algoritmos de descomposición cruzada […]
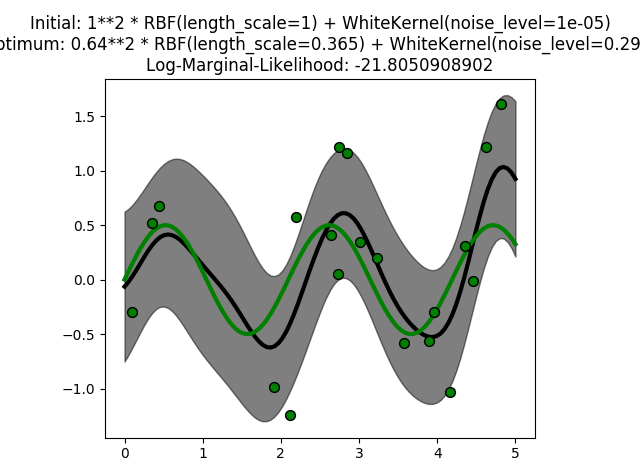
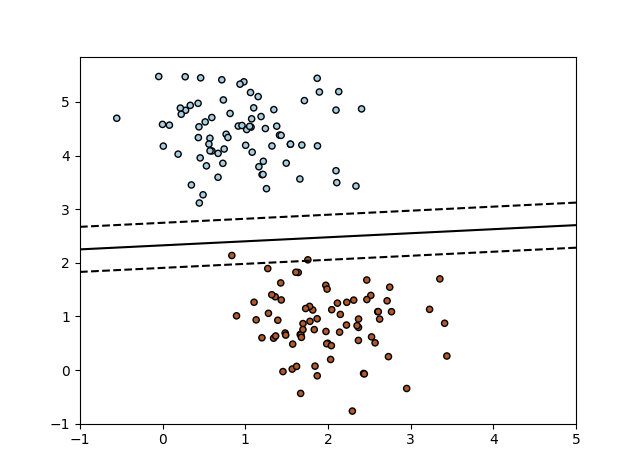
El Descenso de Gradientes Estocástico (SGD) es un enfoque simple pero muy eficiente para el aprendizaje discriminatorio de clasificadores lineales bajo funciones de pérdida convexa tales como Máquinas Vectoriales de Soporte (lineal) y Regresión Logística. A pesar de que SGD ha estado presente en la comunidad de aprendizaje automático durante mucho tiempo, ha recibido una […]
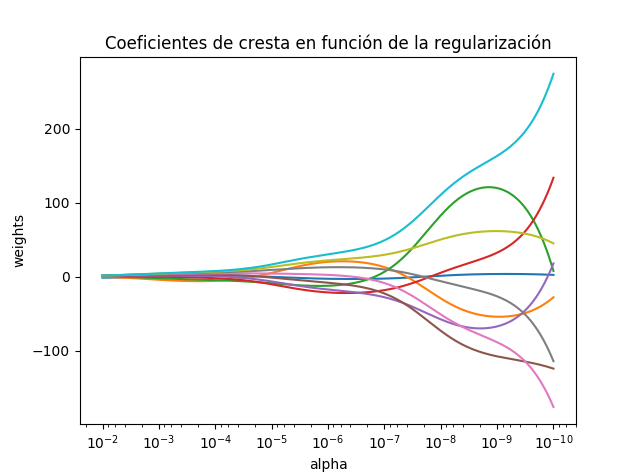
La regresión de la cresta aborda algunos de los problemas de los mínimos cuadrados imponiendo una penalización sobre el tamaño de los coeficientes. Los coeficientes de cresta minimizan una suma residual penalizada de cuadrados, Aquí, alpha >0 es un parámetro de complejidad que controla la cantidad de encogimiento: cuanto mayor es el valor de alfa, […]
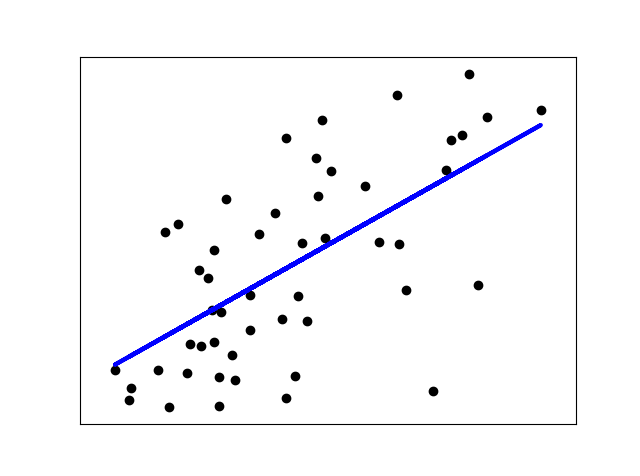
LinearRegression se ajusta a un modelo lineal con coeficientes w = (w_1,…, w_p) para minimizar la suma residual de cuadrados entre las respuestas observadas en el conjunto de datos, y las respuestas pronosticadas por la aproximación lineal. Matemáticamente resuelve un problema de la forma: LinearRegression tomará en su método de ajuste las matrices X, y […]
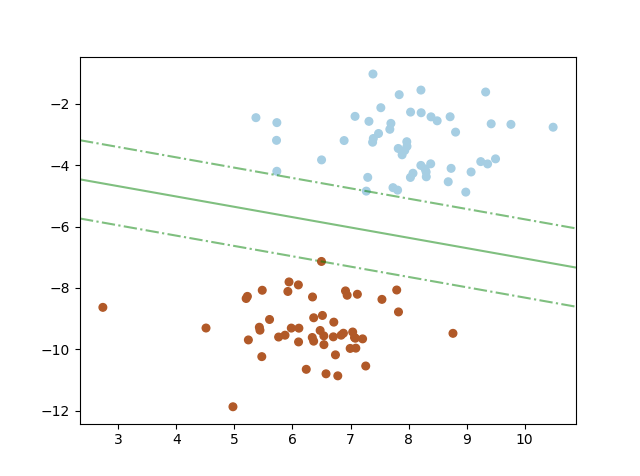
Las máquinas vectoriales de apoyo en ingles “Support Vector Machines” (SVMs) son un conjunto de métodos de aprendizaje supervisados utilizados para la clasificación, regresión y detección de valores atípicos. Las ventajas del Support Vector Machines son: Eficaz en espacios de grandes dimensiones. Todavía eficaz en casos donde el número de dimensiones es mayor que el […]