
Blog
-En este tutorial aprenderemos todo acerca de la Linear Regression o regresión lineal.
-También, vamos a mostrar un ejemplo de ajuste por mínimos cuadrados.
LinearRegression se ajusta a un modelo lineal con coeficientes w = (w_1,…, w_p) para minimizar la suma residual de cuadrados entre las respuestas observadas en el conjunto de datos, y las respuestas pronosticadas por la aproximación lineal. Matemáticamente resuelve un problema de la forma:
![]()
LinearRegression tomará en su método de ajuste las matrices X, y y guardará los coeficientes w del modelo lineal en su miembro coef_:
Sin embargo, las estimaciones de coeficientes para los Mínimos Cuadrados se basan en la independencia de los términos del modelo. Cuando los términos se correlacionan y las columnas de la matriz de diseño X tienen una dependencia lineal aproximada, la matriz de diseño se acerca al singular y como resultado, la estimación de mínimos cuadrados se vuelve altamente sensible a errores aleatorios en la respuesta observada, produciendo una gran varianza. Esta situación de multicolinealidad puede surgir, por ejemplo, cuando los datos se recogen sin un diseño experimental.
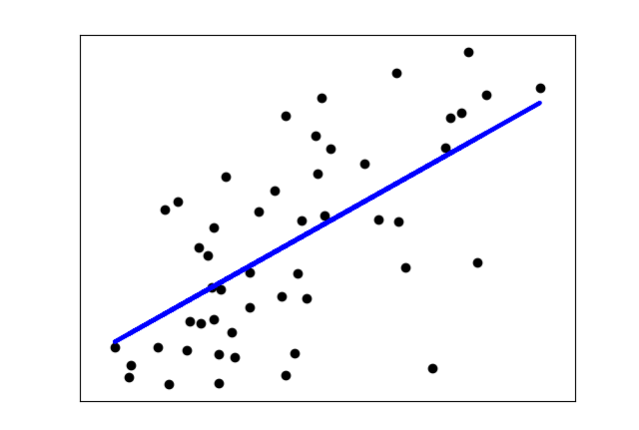
ejemplo de Ajuste por mínimos cuadrados:
import numpy as np
import pylab as pl
from sklearn import linear_model
# este es nuestro conjunto de prueba, es solo una línea recta con algun ruido gaussiano
xmin, xmax = -5, 5
n_samples = 100
X = [[i] for i in np.linspace(xmin, xmax, n_samples)]
Y = 2 + 0.5 * np.linspace(xmin, xmax, n_samples) \
+ np.random.randn(n_samples, 1).ravel()
# ejecuta el clasificador
clf = linear_model.LinearRegression()
clf.fit(X, Y)
# plotea los resultados
pl.scatter(X, Y, color='black')
pl.plot(X, clf.predict(X), color='blue', linewidth=3)
pl.xticks(())
pl.yticks(())
pl.show()
➡ Aprende mucho mas de Machine Learning con nuestro curso:
[…] LinearRegression se ajusta a un modelo lineal con coeficientes w … .featured-thumbna… […]
genial curso, solo dos cosas:
1. toca que el que lo lea sepa de las notaciones de numpy en los arrays. la parte del newaxis puede confundir
# diabetes.data es una matriz de 421 filas por 10 columnas
# diabetes.data[:,2] toma la tercera columna de datos y la devuelve
# en un array unidimensional de 421 elementos, np.newaxis crea
# una nueva dimension, transforma el array en una
# matriz de 421 filas por 1 columna
2. librerias usadas con python3:
– cycler==0.10.0
– joblib==0.13.2
– kiwisolver==1.1.0
– matplotlib==3.1.1
– numpy==1.16.4
– pyparsing==2.4.0
– python-dateutil==2.8.0
– scikit-learn==0.21.2
– scipy==1.3.0
– six==1.12.0
¿De dónde sale el conjunto de prueba: diabetes_y_train?
Corregido! no hace falta ningun dataset ahora, gracias por escribir!