
scikit-learn
El Descenso de Gradientes Estocástico (SGD) es un enfoque simple pero muy eficiente para el aprendizaje discriminatorio de clasificadores lineales bajo funciones de pérdida convexa tales como Máquinas Vectoriales de Soporte (lineal) y Regresión Logística. A pesar de que SGD ha estado presente en la comunidad de aprendizaje automático durante mucho tiempo, ha recibido una […]
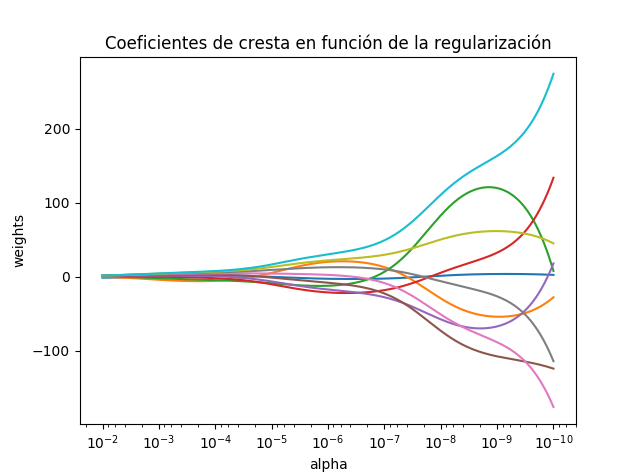
La regresión de la cresta aborda algunos de los problemas de los mínimos cuadrados imponiendo una penalización sobre el tamaño de los coeficientes. Los coeficientes de cresta minimizan una suma residual penalizada de cuadrados, Aquí, alpha >0 es un parámetro de complejidad que controla la cantidad de encogimiento: cuanto mayor es el valor de alfa, […]
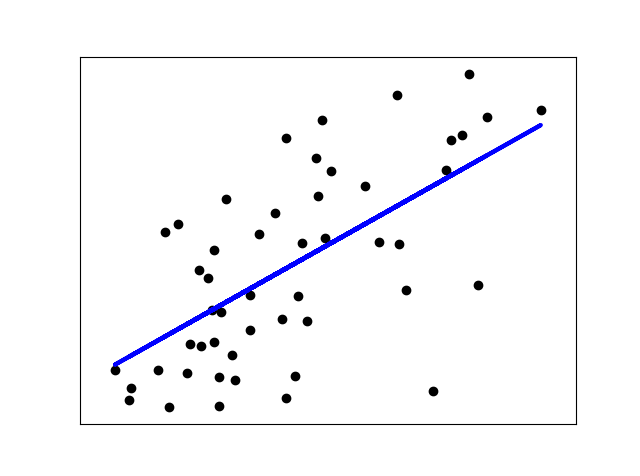
LinearRegression se ajusta a un modelo lineal con coeficientes w = (w_1,…, w_p) para minimizar la suma residual de cuadrados entre las respuestas observadas en el conjunto de datos, y las respuestas pronosticadas por la aproximación lineal. Matemáticamente resuelve un problema de la forma: LinearRegression tomará en su método de ajuste las matrices X, y […]
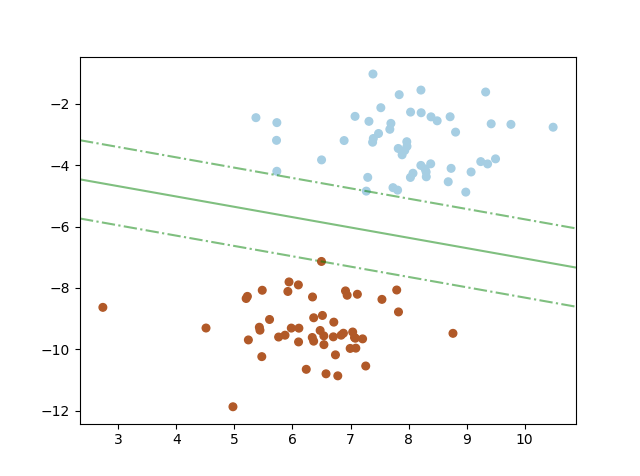
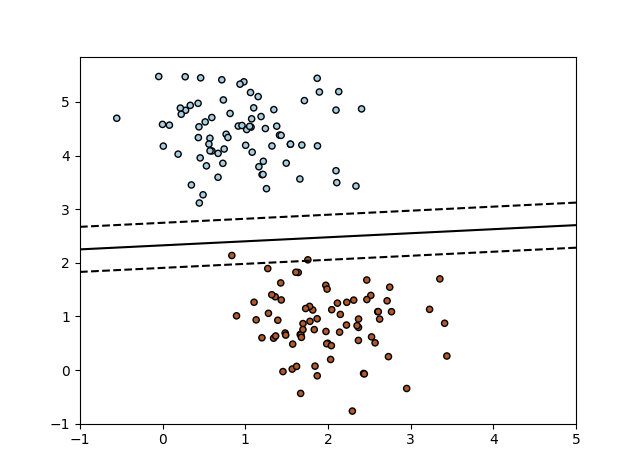
Las máquinas vectoriales de apoyo en ingles “Support Vector Machines” (SVMs) son un conjunto de métodos de aprendizaje supervisados utilizados para la clasificación, regresión y detección de valores atípicos. Las ventajas del Support Vector Machines son: Eficaz en espacios de grandes dimensiones. Todavía eficaz en casos donde el número de dimensiones es mayor que el […]

El clasificador NearestCentroid es un algoritmo simple que representa cada clase por el centroide de sus miembros. En efecto, esto lo hace similar a la fase de actualización de etiquetas del algoritmo sklearn.KMeans. Tampoco tiene parámetros a elegir, por lo que es un buen clasificador de línea de base. Sin embargo, sí sufre en las […]
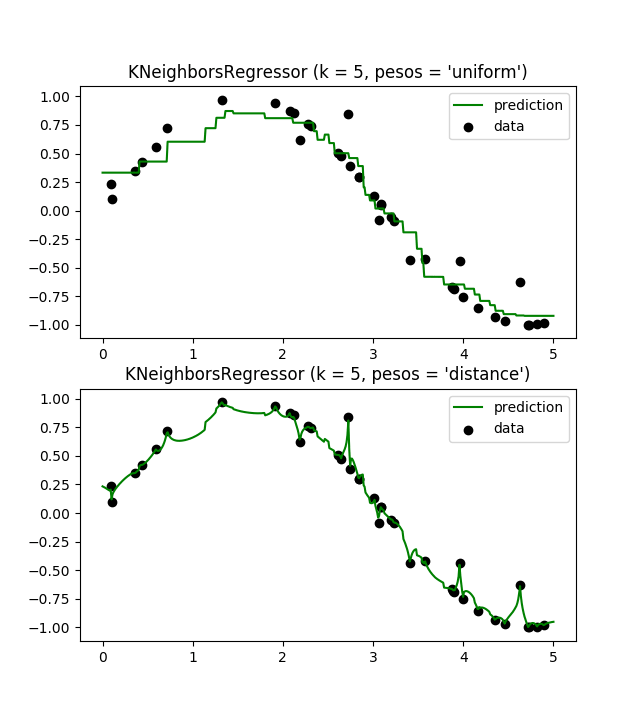
Neighbors-based regression se puede utilizar en casos donde las etiquetas de datos son continuas en lugar de variables discretas. La etiqueta asignada a un punto de consulta se calcula en base a la media de las etiquetas de sus vecinos más cercanos. scikit-learn implementa dos regresores diferentes: KNeighborsRegressor implementa el aprendizaje basado en los k […]
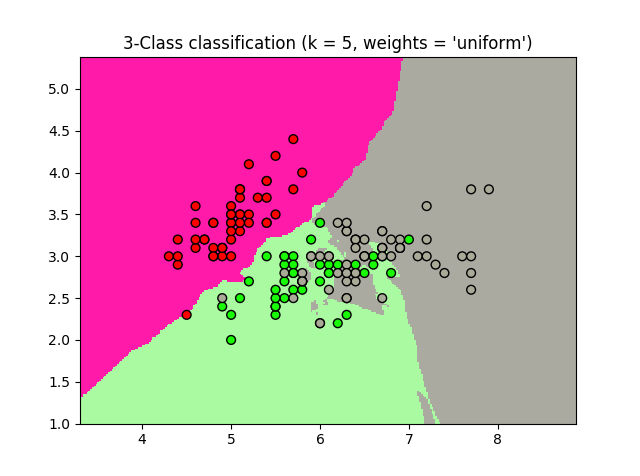
sklearn.neighbors proporciona funcionalidad para métodos de aprendizaje basados en vecinos no supervisados y supervisados . Los vecinos más cercanos no supervisados son la base de muchos otros métodos de aprendizaje, especialmente el aprendizaje múltiple y la agrupación espectral. El aprendizaje supervisado basado en vecinos viene en dos formas: clasificación de datos con etiquetas discretas y regresión […]