
Blog
Machine Learning Nearest Neighbors Regression
-Aprender cuando se puede emplear el Neighbors-based regression.
-Código de ejemplo del Neighbors-based regression.
Neighbors-based regression se puede utilizar en casos donde las etiquetas de datos son continuas en lugar de variables discretas. La etiqueta asignada a un punto de consulta se calcula en base a la media de las etiquetas de sus vecinos más cercanos.
scikit-learn implementa dos regresores diferentes: KNeighborsRegressor implementa el aprendizaje basado en los k vecinos más cercanos de cada punto de consulta, donde k es un valor entero especificado por el usuario. RadiusNeighborsRegressor implementa el aprendizaje basado en los vecinos dentro de un radio fijo r del punto de consulta, donde r es un valor de punto flotante especificado por el usuario.
La regresión básica de los vecinos más cercanos utiliza pesos uniformes: es decir, cada punto del vecindario local contribuye uniformemente a la clasificación de un punto de consulta. En algunas circunstancias, puede ser ventajoso para los puntos de ponderación de tal manera que los puntos cercanos contribuyan más a la regresión que los puntos lejanos. Esto se puede lograr a través de la palabra clave pesas. El valor por defecto, weights =’ uniforme’, asigna pesos iguales a todos los puntos. weights =’ distancia’ asigna pesos proporcionales a la distancia inversa del punto de consulta. Alternativamente, se puede suministrar una función de la distancia definida por el usuario, que se utilizará para calcular los pesos.
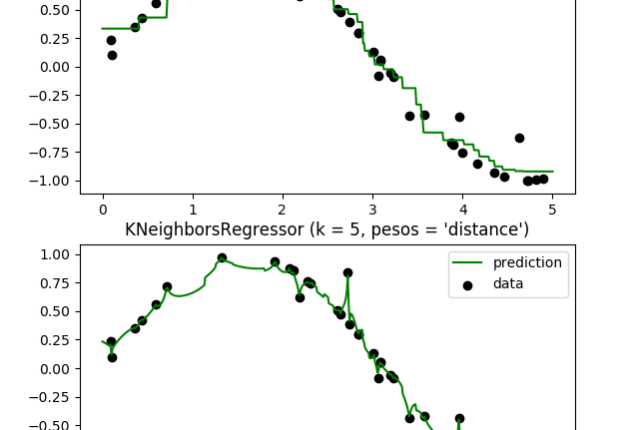
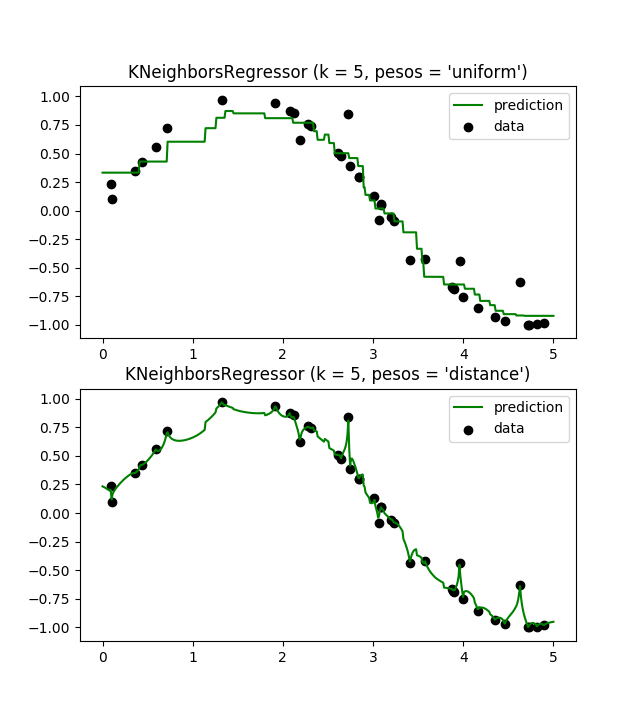
En este ejemplo se demuestra la resolución de un problema de regresión utilizando k-Nearest Neighbor y la interpolación del objetivo usando tanto el baricentro como los pesos constantes.
import numpy as np
import matplotlib.pyplot as plt
from sklearn import neighbors
# Generando los datos
np.random.seed(0)
X = np.sort(5 * np.random.rand(40, 1), axis=0)
T = np.linspace(0, 5, 500)[:, np.newaxis]
y = np.sin(X).ravel()
# añade ruido
y[::5] += 1 * (0.5 - np.random.rand(8))
# ajuste del 1º modelo de regresion
n_neighbors = 5
for i, weights in enumerate(['uniform', 'distance']):
knn = neighbors.KNeighborsRegressor(n_neighbors, weights=weights)
y_ = knn.fit(X, y).predict(T)
plt.subplot(2, 1, i + 1)
plt.scatter(X, y, c='k', label='data')
plt.plot(T, y_, c='g', label='prediction')
plt.axis('tight')
plt.legend()
plt.title("KNeighborsRegressor (k = %i, pesos = '%s')" % (n_neighbors, weights))
plt.show()
➡ Aprende mucho mas de Machine Learning con nuestro curso: