
Blog
Ejemplo Simple Support Vector Machine (SVM) con reconocimiento de caracteres
-En este tutorial mostraremos un ejemplo muy sencillo de cómo funciona Machine Learning. Vamos a predecir un dígito que veremos en una imagen resultante.
Mi meta aquí es mostrarle lo simple que puede ser el Machine Learning, donde la parte realmente difícil es obtener datos, etiquetar datos y organizarlos. Para enfatizar esto, vamos a usar un conjunto de datos preexistentes que todos tienen y que vienen con la instalación de Scikit-Learn.
Uno de los conjuntos de datos son los dígitos, contiene un conjunto de muestras ya estructuradas y etiquetadas que contiene información de píxeles para números de hasta 9 que podemos usar para entrenamiento y pruebas.
Para hacer este tutorial, vas a necesitar:
- numpy
- scipy
- matplotlib
- Scikit-learn
También se puede obtener instalando con pip. Si tienes una versión actualizada de Python 2 o Python 3, tienes pip, y deberías poder correr:
pip install numpy pip install scipy pip install matplotlib pip install scikit-learn
¿Confundido? ¿No sabes lo que es pip? No hay problema, pasate por Aprende a programar en Python desde 0 con este Curso de 10 Clases
Si todavía no puede hacerlo funcionar, póngase en contacto con nosotros a través del enlace de contacto en el pie de página.
Ahora, para empezar:
import matplotlib.pyplot as plt from sklearn import datasets from sklearn import svm digits = datasets.load_digits()
Arriba, hemos importado los módulos necesarios. Pyplot se utiliza para dibujar un gráfico, los conjuntos de datos se utilizan como un conjunto de datos de muestra, que contiene un conjunto que tiene datos de reconocimiento de números. Por último, importamos svm para Sklearn.
A continuación, definimos la variable digits, que es el conjunto de dígitos cargado.
Con esto, puede hacer referencia a las características y etiquetas de los datos:
print(digits.data)
digits. data son los datos reales (características).
print(digits.target)
digits. target es la etiqueta real que hemos asignado a los datos de dígitos.
Ahora que tenemos los datos listos, estamos listos para hacer Machine Learning. Primero, especificamos el clasificador:
Si lo desea, puede dejar los parámetros en blanco y utilizar los valores por defecto, así:
clf = svm.SVC()
Aunque obtendrá mejores resultados con:
clf = svm.SVC(gamma=0.001, C=100)
Esto elige el SVC, y nosotros ponemos gamma y C. Por ahora, no vamos a entrar en el propósito de estos valores.
Es probable que el uso de los valores predeterminados produzca resultados inferiores, aunque todavía debería funcionar bastante bien en este ejemplo.
Con eso hecho, ahora estamos listos para entrenar. Es mejor para mayor claridad seguir adelante y asignar el valor en X (arriba) e y.
Esto carga todos los 10 últimos puntos de datos, así que podemos usarlos todos para entrenar. A continuación, podemos utilizar los últimos 10 puntos de datos para las pruebas. Para aliviar la confusión, este emparejamiento X, y se denota con una X mayúscula, porque no es realmente una coordenada x convencional. La X contiene todas las “coordenadas” y y es simplemente el “objetivo” o la “clasificación” de los datos. Cada bit de datos pertenece a un número. Por lo tanto, X puede contener un montón de datos de píxeles para el número 5, y la “y” sería 5.
Luego entrenamos con:
clf.fit(X,y)
Eso es todo, ahora hemos entrenado la máquina. Probémoslo!
print(clf.predict(digits.data[-28]))
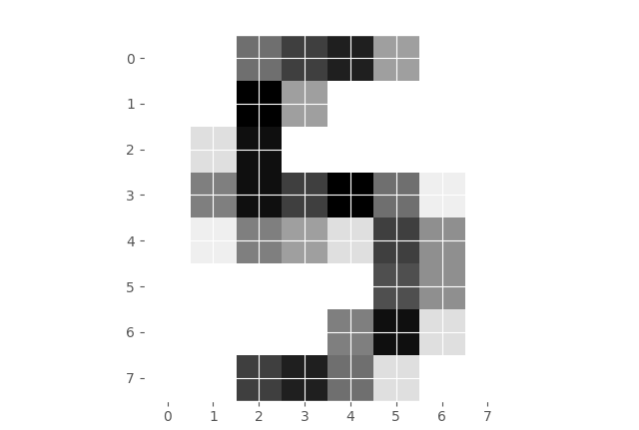
Esto predecirá lo que es el veintiochoavo del último elemento. Para nosotros, sería útil seguir adelante y visualizar esto, así que vamos a hacerlo:
plt.imshow(digits.images[-28], cmap=plt.cm.gray_r, interpolation='nearest') plt.show()
nos muestra una imagen del número en cuestión. No te preocupes si no sigues la función imshow, no es necesario para este tutorial o esta serie.
¿Cómo fueron los resultados? ¿La máquina predijo correctamente?
predicción:[5]
La imagen resultante:

Siéntase libre de jugar con el código y probar más muestras. Ajusta la gama un poco. Usted debe notar que la velocidad sube el gamma más grande, pero la precisión disminuye. Usted debe notar lo contrario si disminuye la gamma (haga esto por factores de 10).
Entonces, algo como:
clf = svm.SVC(gamma=0.01, C=100)
Es probable que esto sea inexacto o menos preciso que antes.
clf = svm.SVC(gamma=0.0001, C=100)
Código completo del ejemplo “Simple Support Vector Machine (SVM) con reconocimiento de caracteres”
import matplotlib.pyplot as plt from sklearn import datasets from sklearn import svm digits = datasets.load_digits() print(digits.data) print(digits.target) clf = svm.SVC() clf = svm.SVC(gamma=0.001, C=100) X,y = digits.data[:-10], digits.target[:-10] clf.fit(X,y) print(clf.predict(digits.data[-28])) plt.imshow(digits.images[-28], cmap=plt.cm.gray_r, interpolation='nearest') plt.show()