
Blog
Proyecto: Predecir el sentimiento desde Reseñas de películas
-En esta lección descubrirás cómo puedes predecir el sentimiento de críticas de películas como positivas o negativas en Python usando la biblioteca de aprendizaje profundo de Keras.
-Analizar sentimientos del conjunto de datos IMDB para el procesamiento del lenguaje natural y cómo cargarlo en Keras.
-Cómo usar la incrustación/embedding de palabras en Keras para problemas de lenguaje natural.
-Cómo desarrollar y evaluar un modelo de Red Neuronal para el problema IMDB.
-Cómo desarrollar un modelo de Red Neural Convolucional unidimensional para el conjunto de datos IMDB.
El análisis de sentimientos es un problema de procesamiento de lenguaje natural en el que el texto se entiende y se predice la intención subyacente del mismo.
Conjunto de datos de Clasificación de Sentimientos de Revisión de Películas
Los datos utilizado en este proyecto es el denominado Conjunto de Datos de Revisión de Películas (Large Movie Review Dataset), al que a menudo se hace referencia como el Conjunto de datos IMDB. El conjunto de datos IMDB contiene 50.000 críticas de películas altamente polares (buenas o malas), de las cuales utilizaremos 50% para el entrenamiento y 50% para las pruebas. El problema es determinar si una crítica o review de una película un tiene un sentimiento positivo o negativo.
Los datos fueron recopilados por investigadores de Stanford y se utilizaron en un artículo de investigacion en 2011 en el que se consiguió una precisión del 88,89%.
Cargar el conjunto de datos IMDB con Keras
Keras proporciona acceso al conjunto de datos IMDB incorporado. La función imdb.load data() le permite cargar el conjunto de datos en un formato que está listo para su uso en redes neuronales y modelos de aprendizaje profundo. Las palabras han sido reemplazadas por números enteros que indican la popularidad absoluta del conjunto de datos. Por lo tanto, las sentencias de cada revisión se componen de una secuencia de números enteros.
Llamando a imdb.load data() la primera vez descargará el conjunto de datos IMDB en su PC guardándolo en su directorio home bajo ~/.keras/datasets/imdb.pkl como un archivo de 32 megabytes.
Útilmente, la función imdb.load data() proporciona argumentos adicionales incluyendo el número de palabras superiores a cargar (donde las palabras con un número entero inferior se marcan como cero en los datos devueltos), el número de palabras principales a omitir y la duración máxima de las revisiones. Vamos a cargar el conjunto de datos y calcular algunas de sus propiedades. Comenzaremos cargando algunas bibliotecas y cargamos todo el conjunto de datos IMDB.
import numpy from keras.datasets import imdb from matplotlib import pyplot # load the dataset (X_train, y_train), (X_test, y_test) = imdb.load_data() X = numpy.concatenate((X_train, X_test), axis=0) y = numpy.concatenate((y_train, y_test), axis=0)
hacemos un print para ver el dataset a entrenar:
# summarize size
print("dataset a entrenar: ")
print(X.shape)
print(y.shape)
podemos imprimir valores único de clase como:
# numero de clases
print("Clases: ")
print(numpy.unique(y))
podemos ver que los valores son binarios ya que se trata de saber si el comentario o review es bueno o malo
Clases: [0 1]
También podemos hacer un print de las palabras únicas del conjunto de datos:
# palabras únicas del conjunto de datos
print("número de palabras: ")
print(len(numpy.unique(numpy.hstack(X))))
Es muy conveniente examinar los conjuntos de datos para realizar un buen análisis.
número de palabras: 88585
Con el siguiente código podemos saber la media de la longitudad de las palabras
# longitud
print("longitud: ")
result = [len(x) for x in X]
print("Media %.2f palabras (%f)" % (numpy.mean(result), numpy.std(result)))
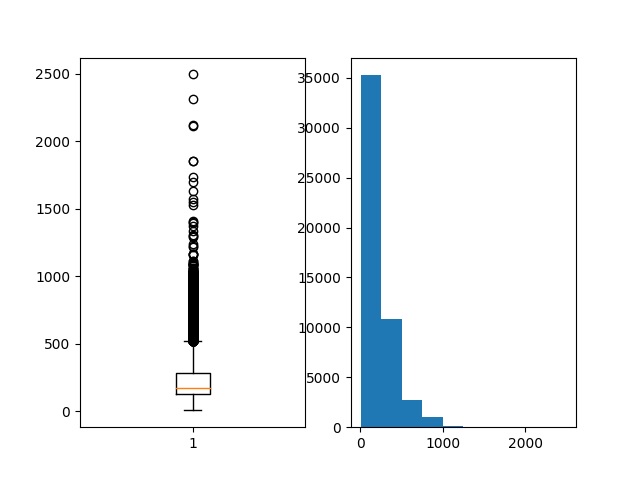
# ploteamos la longitud un boxplot y el histograma
pyplot.subplot(121)
pyplot.boxplot(result)
pyplot.subplot(122)
pyplot.hist(result)
pyplot.show()
Dando como resultado
longitud: Media 234.76 palabras (172.911495)
El código completo es el siguiente:
#cargamos y ploteamos el conjunto de datos IMDB
import numpy
from keras.datasets import imdb
from matplotlib import pyplot
# carga del dataset
(X_train, y_train), (X_test, y_test) = imdb.load_data()
X = numpy.concatenate((X_train, X_test), axis=0)
y = numpy.concatenate((y_train, y_test), axis=0)
# tamaño
print("tamaño de los datos: ")
print(X.shape)
print(y.shape)
# numero de clases
print("Clases: ")
print(numpy.unique(y))
# numero de palabras
print("numero de palabras: ")
print(len(numpy.unique(numpy.hstack(X))))
# longitud
print("longitud: ")
result = [len(x) for x in X]
print("Media %.2f palabras (%f)" % (numpy.mean(result), numpy.std(result)))
# ploteamos la longitud un boxplot y el histograma
pyplot.subplot(121)
pyplot.boxplot(result)
pyplot.subplot(122)
pyplot.hist(result)
pyplot.show()
Si observamos el gráfico de cajas y bigotes y el histograma de las longitudes de revisión en palabras, probablemente podamos ver una distribución exponencial que puede cubrir la masa de la distribución con una longitud recortada de 400 a 500 palabras.
Palabras Embeddings
Un avance reciente en el desarrollo del procesamiento del lenguaje natural se llama Embedding de palabras. Se trata de una técnica en la que las palabras se codifican como vectores de valor real en un espacio de alta dimensión, donde la similitud entre las palabras en términos de significado se traduce en cercanía en el espacio vectorial. Las palabras discretas se asignan a vectores de números continuos. Esto es útil cuando se trabaja con problemas de lenguaje natural en redes neuronales, ya que necesitamos números como valores de entrada. Keras proporciona una forma conveniente de convertir representaciones enteras positivas de palabras en una palabra embedding por una capa embedding. La capa toma argumentos que desvanecen el mapeo, incluyendo el número máximo de palabras esperadas, también llamado tamaño del vocabulario (por ejemplo, el valor entero más grande que se verá como una entrada). La capa también le permite especificar la dimensionalidad para cada vector de palabra, llamada dimensión de salida.
Nos gustaría utilizar una representación de palabras embedding para el conjunto de datos IMDB. Digamos que sólo nos interesan las primeras 5.000 palabras más usadas en el conjunto de datos. Por lo tanto, el tamaño de nuestro vocabulario será de 5.000. Podemos elegir usar un vector de 32 dimensiones para representar a cada una de ellas. Finalmente, podemos optar por limitar la extensión máxima de la revisión a 500 palabras, truncando revisiones más largas que eso y las revisiones de relleno más cortas que eso con valores 0. Cargamos el set de datos IMDB como se indica a continuación:
imdb.load_data(num_words=5000)
Entonces con Keras podemos truncar o rellenar el conjunto de datos a una longitud de 500 para cada observación usando la función sequence.pad_sequences() como:
X_train = sequence.pad_sequences(X_train, maxlen=500) X_test = sequence.pad_sequences(X_test, maxlen=500)
Finalmente, más tarde, la primera capa de nuestro modelo sería una capa de embedding de palabras creada usando la clase embedding de la siguiente manera:
Embedding(5000, 32, input_length=500)
La salida de esta primera capa sería una matriz con el tamaño 32 x 500 para un determinado entrenamiento de revisión de película o patrón de prueba en formato entero. Ahora que sabemos cómo cargar el conjunto de datos IMDB en Keras y cómo usar una representación de incrustación de palabras para ello, vamos a desarrollar y evaluar algunos modelos.
Modelo simple multicapa de Perceptron
Podemos empezar por desarrollar un modelo simple de Perceptron multicapa con una sola capa oculta. La palabra representación de incrustación es una verdadera innovación y demostraremos lo que se habría considerado resultados de clase mundial en 2011 con una red neuronal relativamente simple. Empecemos por importar las clases y funciones necesarias para este modelo e inicializar el generador de números aleatorios a un valor constante para asegurarnos de que podemos reproducir fácilmente los resultados.
# perceptron multica para datos IMDB import numpy from keras.datasets import imdb from keras.models import Sequential from keras.layers import Dense from keras.layers import Flatten from keras.layers.embeddings import Embedding from keras.preprocessing import sequence # semilla aleatoria de reproducibilidad seed = 7 numpy.random.seed(seed)
A continuación cargaremos el conjunto de datos IMDB. Simplificaremos el conjunto de datos tal y como se explica en la sección sobre incrustaciones de palabras. Sólo se cargarán las 5.000 primeras palabras. También utilizaremos una división del 50%/50% del conjunto de datos en formación y pruebas. Esta es una buena metodología de división estándar.
# cargar del conjunto de datos pero sólo mantenemos las n palabras principales, cero el resto top_words = 5000 (X_train, y_train), (X_test, y_test) = imdb.load_data(num_words=top_words)
Limitaremos las reseñas a 500 palabras, truncando las revisiones más largas y las revisiones más cortas.
max_words = 500 X_train = sequence.pad_sequences(X_train, maxlen=max_words) X_test = sequence.pad_sequences(X_test, maxlen=max_words)
Ahora podemos crear nuestro modelo. Usaremos una capa de embedding como capa de entrada, estableciendo el vocabulario en 5.000, el tamaño del vector de palabra con 32 dimensiones y la longitud de entrada (input_legth) de 500. El resultado de esta primera capa será una matriz de tamaño 32500 como se discutió en la sección anterior. Aplanaremos la salida de las capas de embedding a una dimensión, luego usaremos una capa oculta densa de 250 unidades con función de activación de rectier. La capa de salida tiene una neurona y usará una activación sigmoide con valores de salida de 0 y 1 como predicciones. El modelo utiliza la pérdida logarítmica y se optimiza mediante el procedimiento de optimización de ADAM.
# creamos el modelo model = Sequential() model.add(Embedding(top_words, 32, input_length=max_words)) model.add(Flatten()) model.add(Dense(250, activation='relu')) model.add(Dense(1, activation='sigmoid')) model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) print(model.summary())
Podemos utilizar el modelo y el conjunto de pruebas como validación durante el entrenamiento. Este modelo se sobreajusta muy rápidamente por lo que utilizaremos muy pocas épocas de entrenamiento, en este caso sólo 2. Hay muchos datos por lo que utilizaremos un tamaño de lote de 128. Después de que el modelo es entrenado, evaluamos su exactitud en el conjunto de datos de la prueba.
# ajustamos el modelo
model.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=2, batch_size=128,
verbose=1)
# Final evaluacion del modelo
scores = model.evaluate(X_test, y_test, verbose=0)
print("Precisión: %.2f%%" % (scores[1]*100))
El código completo es el siguiente:
# perceptron multica para datos IMDB
import numpy
from keras.datasets import imdb
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import Flatten
from keras.layers.embeddings import Embedding
from keras.preprocessing import sequence
# semilla aleatoria de reproducibilidad
seed = 7
numpy.random.seed(seed)
# cargar del conjunto de datos pero sólo mantenemos las n palabras principales, cero el resto
top_words = 5000
(X_train, y_train), (X_test, y_test) = imdb.load_data(num_words=top_words)
max_words = 500
X_train = sequence.pad_sequences(X_train, maxlen=max_words)
X_test = sequence.pad_sequences(X_test, maxlen=max_words)
# creacion del modelo
model = Sequential()
model.add(Embedding(top_words, 32, input_length=max_words))
model.add(Flatten())
model.add(Dense(250, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
print(model.summary())
# Ajustamos el modelo
model.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=2, batch_size=128,
verbose=2)
# Final evaluacion del modelo
scores = model.evaluate(X_test, y_test, verbose=0)
print("Precision: %.2f%%" % (scores[1]*100))
Al ejecutar este ejemplo, se utiliza el modelo y se resume el rendimiento estimado. Podemos ver que este modelo tan sencillo consigue una puntuación cercana al 86,94% que se encuentra en la vecindad del papel original, con muy poco esfuerzo.
Train on 25000 samples, validate on 25000 samples Epoch 1/2 - 33s - loss: 0.5082 - acc: 0.7114 - val_loss: 0.3372 - val_acc: 0.8513 Epoch 2/2 - 30s - loss: 0.1909 - acc: 0.9276 - val_loss: 0.3007 - val_acc: 0.8728 Precision: 86.94%
Seguramente podemos hacerlo mejor si entrenamos esta red usando un embedding más grande y añadiendo más capas ocultas. Probemos con un tipo de red diferente.
Red Neural Convolucional Unidimensional
Las redes neuronales convolucionales fueron diseñadas para mejorar la estructura espacial en los datos de imagen sin perder robustez a la posición y orientación de los objetos aprendidos en la escena. Este mismo principio se puede utilizar en secuencias, como la secuencia unidimensional de palabras en una crítica cinematográfica.
Las mismas propiedades que hacen que el modelo de CNN o ConvNet (convolutional neural network) sea atractivo para aprender a reconocer objetos en imágenes pueden ayudar a aprender la estructura en párrafos de palabras, es decir, la invariancia de las técnicas a la posición específica de los rasgos.
Keras soporta convoluciones unidimensionales y pooling por las clases Conv1D y MaxPooling1D respectivamente. De nuevo, importamos las clases y funciones necesarias para este ejemplo e inicialicemos nuestro generador de números aleatorios a un valor constante para que podamos reproducir fácilmente resultados.
# CNN para el IMDB import numpy from keras.datasets import imdb from keras.models import Sequential from keras.layers import Dense from keras.layers import Flatten from keras.layers.convolutional import Conv1D from keras.layers.convolutional import MaxPooling1D from keras.layers.embeddings import Embedding from keras.preprocessing import sequence # semilla aleatoria de reproducibilidad seed = 7 numpy.random.seed(seed)
También podemos cargar y preparar nuestro conjunto de datos IMDB como lo hicimos antes.
# cargar del conjunto de datos pero sólo mantenemos las n palabras principales, cero el resto top_words = 5000 (X_train, y_train), (X_test, y_test) = imdb.load_data(num_words=top_words) max_words = 500 X_train = sequence.pad_sequences(X_train, maxlen=max_words) X_test = sequence.pad_sequences(X_test, maxlen=max_words)
Ahora podemos definir nuestro modelo de red neuronal convolucional. Esta vez, después de la capa de entrada de embedding, insertamos una capa de Conv1D. Esta capa convolucional tiene 32 mapas de características y lee representaciones de palabras incrustadas de 3 elementos vectoriales de la palabra embedding a la vez. La capa convolucional es seguida por una capa MaxPooling1D con una longitud y zancada de 2 que reduce a la mitad el tamaño de los mapas de características de la capa convolucional. El resto de la red es la misma que la red neuronal anterior.
# creacion del modelo model = Sequential() model.add(Embedding(top_words, 32, input_length=max_words)) model.add(Conv1D(filters=32, kernel_size=3, padding='same', activation='relu')) model.add(MaxPooling1D(pool_size=2)) model.add(Flatten()) model.add(Dense(250, activation='relu')) model.add(Dense(1, activation='sigmoid')) model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) print(model.summary())
Aquí presentamos el código completo
# CNN para el datset de IMDB
import numpy
from keras.datasets import imdb
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import Flatten
from keras.layers.convolutional import Conv1D
from keras.layers.convolutional import MaxPooling1D
from keras.layers.embeddings import Embedding
from keras.preprocessing import sequence
# semilla aleatoria de reproducibilidad
seed = 7
numpy.random.seed(seed)
# cargar el conjunto de datos pero manteniendo las n palabras principales, cero el resto
top_words = 5000
(X_train, y_train), (X_test, y_test) = imdb.load_data(num_words=top_words)
# conjunto de datos pad a una longitud máxima de revisión en palabras
max_words = 500
X_train = sequence.pad_sequences(X_train, maxlen=max_words)
X_test = sequence.pad_sequences(X_test, maxlen=max_words)
# creacion del modelo
model = Sequential()
model.add(Embedding(top_words, 32, input_length=max_words))
model.add(Conv1D(filters=32, kernel_size=3, padding='same', activation='relu'))
model.add(MaxPooling1D(pool_size=2))
model.add(Flatten())
model.add(Dense(250, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
print(model.summary())
# Ajuste del modelo
model.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=2, batch_size=128,
verbose=2)
# Final evaluacion del modelo
scores = model.evaluate(X_test, y_test, verbose=0)
print("Precision: %.2f%%" % (scores[1]*100))
Al ejecutar el ejemplo, se nos presenta por primera vez un resumen de la estructura de la red (no que se muestra aquí). Podemos ver que nuestra capa convolucional preserva la dimensionalidad de nuestra embedding capa de entrada de 32 entradas dimensionales con un máximo de 500 palabras. La capa de pooling comprime esta representación reduciéndola a la mitad. Al ejecutar el ejemplo podemos apreciar que ofrece una mejora pequeña pero bienvenida sobre el modelo de red neuronal anterior con una precisión del 88.63%.
Train on 25000 samples, validate on 25000 samples Epoch 1/2 - 39s - loss: 0.4768 - acc: 0.7382 - val_loss: 0.2788 - val_acc: 0.8846 Epoch 2/2 - 41s - loss: 0.2212 - acc: 0.9130 - val_loss: 0.2711 - val_acc: 0.8863 Accuracy: 88.63%
Una vez más, hay muchas oportunidades para una mayor optimización, como por ejemplo el uso de sistemas más profundos y/o capas convolucionales más grandes. Una idea interesante es establecer el nivel máximo de pooling para utilizar una entrada longitud de 500. Esto comprimiría cada mapa de características a un solo vector de 32 longitudes y podría aumentar el rendimiento.
➡ Continúa aprendiendo de Deep Learning en nuestro curso:
[…] de clasificación del sentimiento de la crítica o review cinematográfico, introducido en este post del curso de Deep Learning. Podemos rápidamente desarrollar un pequeño LSTM para el problema de […]
[…] de clasificación del sentimiento de la crítica o review cinematográfico, introducido en este post del curso de Deep Learning. Podemos rápidamente desarrollar un pequeño LSTM para el problema de […]