
Blog
El modelo Embeddings (Incrustaciones) de Palabras
Las embeddings de palabras, o incrustaciones de palabras son un tipo de representación de palabras, que permite que ciertas palabras con significado similar tengan una representación similar. Son una representación distribuida de texto, que es quizás uno de los avances clave para el impresionante rendimiento de los métodos de Deep Learning en el desafío de los problemas de procesamiento del lenguaje natural. En este capítulo, verás el enfoque de incrustación de palabras para representar datos de texto. Después de completar esta parte del curso sabrás:
- Cuál es el enfoque de incrustación embeddings de palabras para representar texto, y en qué se diferencia de otros métodos de extracción de características.
- Sabrás que hay tres algoritmos principales para aprender una palabra incrustada embeddings a partir de datos de texto.
- Que puedes entrenar una nueva incrustación o usar una incrustación embeddings pre-entrenada en su tarea de procesamiento del lenguaje natural.
Descripción general
Este tutorial de modelo Embeddings de Palabras está dividido en las siguientes partes:
- ¿Qué son las embeddings de palabras?
- Algoritmos de inserción de palabras
- Uso de incrustaciones de palabras
¿Qué son las embeddings de palabras?
Una embedding de palabras es una representación aprendida de un texto, donde las palabras que tienen el mismo significado tienen una representación similar. Este enfoque de la representación de palabras y documentos puede ser considerado como uno de los principales avances del Deep Learning en los problemas de procesamiento del lenguaje natural.
Las embeddings de palabras son, de hecho, una clase de técnicas en las que las palabras individuales se representan como vectores de valor real en un espacio vectorial predefinido. Cada palabra se mapea a un vector y los valores vectoriales se aprenden de una manera que se asemejan a los de un vector.
La clave del enfoque es la idea de usar una representación distribuida densa para cada palabra. Cada palabra está representada por un vector de valor real, a menudo decenas o cientos de dimensiones. Esto contrasta con las miles o millones de dimensiones requeridas para representaciones de palabras escasas, tales como una codificación en caliente.
La representación distribuida se aprende a partir del uso de las palabras. Esto permite que palabras que son usadas de maneras similares resulten en representaciones similares, capturando naturalmente su significado. Esto puede contrastarse con la representación nítida pero frágil de un modelo de bolsa de palabras en el que, a menos que se maneje explícitamente, las diferentes palabras tienen diferentes representaciones, independientemente de cómo se utilicen.
Hay una teoría lingüística más profunda detrás del enfoque como la hipótesis distribucional de Zellig Harris que podría resumirse como: las palabras que tienen un contexto similar, tendrán significados similares.
Algoritmos de inserción de palabras
Los métodos de embedding de palabras aprenden una representación vectorial de valor real para un vocabulario predefinido de tamaño fijo a partir de un corpus de texto. El proceso de aprendizaje está unido con el modelo de red neuronal en alguna tarea, como la clasificación de documentos, o es un proceso no supervisado que utiliza estadísticas de documentos. En esta sección se repasan tres técnicas que se pueden utilizar para aprender a incrustar una palabra a partir de datos de texto.
Capa de inserción
Una capa de incrustación, a falta de un nombre mejor, es una incrustación de palabras que se aprende conjuntamente con un modelo de red neuronal en una tarea específica de procesamiento del lenguaje natural, como el modelado del lenguaje o la clasificación de documentos. Requiere que el texto del documento se limpie y prepare de tal manera que cada palabra esté codificada en caliente. El tamaño del espacio vectorial se especifica como parte del modelo, como 50, 100 ó 300 dimensiones. Los vectores se inicializan con números aleatorios pequeños. La capa de embeddings se utiliza en el extremo frontal de una red neuronal y se ajusta de forma supervisada mediante el algoritmo de retropropagación.
Las palabras codificadas en caliente son mapeadas a los vectores de palabras. Si se utiliza un modelo Perceptron multicapa, los vectores de palabras se concatenan antes de ser introducidos en el modelo. Si se utiliza una red neuronal recurrente, entonces cada palabra puede ser tomada como una entrada en una secuencia. Este enfoque de aprendizaje de una capa de embedding requiere muchos datos de formación y puede ser lento, pero aprenderá una embedding dirigida tanto a los datos de texto específicos como a la tarea de PNL.
Word2Vec
Word2Vec es un método estadístico para aprender eficientemente una palabra independiente incrustada de un corpus de texto. Fue desarrollado por Tomas Mikolov en Google en 2013 para hacer más eficiente el entrenamiento basado en redes neuronales de la embedding y desde entonces se ha convertido en el estándar de facto para el desarrollo de la embedding de palabras pre-entrenadas.
Además, el trabajo incluyó el análisis de los vectores aprendidos y la exploración de la matemática de vectores en las representaciones de palabras. Por ejemplo, que restar la hombría de Rey y sumar la feminidad resulta en la palabra Reina, capturando la analogía rey es a reina como el hombre es a mujer.
Se introdujeron dos modelos de aprendizaje diferentes que pueden ser utilizados como parte del enfoque de Word2Vec para aprender las palabras embedding, son:
- Bolsa de Palabras Continua, o modelo CBOW.
- Modelo Continuo Skip-Gram.
El modelo CBOW aprende la embedding prediciendo la palabra actual basándose en su contexto.
El modelo de programa continuo de salto aprende prediciendo las palabras circundantes a las que se les ha dado una palabra actual.
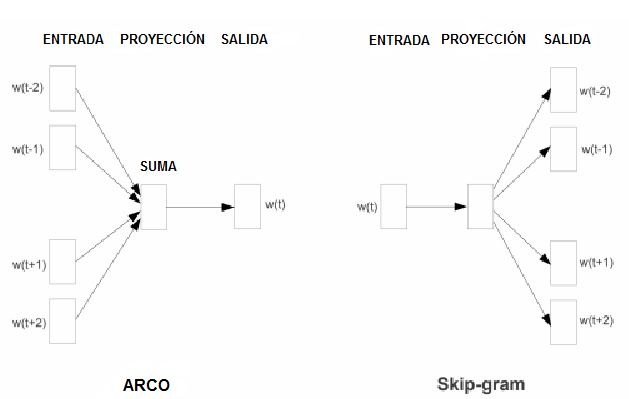
Ambos modelos están enfocados en el aprendizaje de palabras dado su contexto de uso local, donde el contexto está definido por una ventana de palabras vecinas. Esta ventana es un parámetro configurable del modelo.
La ventaja clave del enfoque es que las embeddings de palabras de alta calidad pueden aprenderse de forma eficiente (gracias a una baja complejidad de espacio y tiempo), lo que permite aprender embeddings más grandes (más dimensiones) a partir de corpus de texto mucho más grandes (miles de millones de palabras).
GloVe
El algoritmo Vectores Globales para la Representación de Palabras, o GloVe, es una extensión del método Word2Vec para el aprendizaje eficiente de vectores de palabras, desarrollado por Pennington, en Stanford. Las representaciones clásicas de modelos vectoriales espaciales de palabras fueron desarrolladas usando técnicas de factorización matricial tales como el Análisis Semántico Latente (LSA, por sus siglas en inglés) que hacen un buen trabajo en el uso de estadísticas globales de texto pero que no son tan buenas como los métodos aprendidos como Word2Vec para capturar el significado y demostrarlo en tareas como el cálculo de analogías (por ejemplo. el ejemplo de Rey y Reina arriba).
GloVe es un enfoque que combina las estadísticas globales de técnicas de factorización matricial como LSA con el aprendizaje local basado en el contexto en Word2Vec. En lugar de usar una ventana para definir el contexto local, GloVe construye una matriz explícita de palabra-contexto o co-ocurrencia de palabras usando estadísticas a través de todo el corpus del texto. El resultado es un modelo de aprendizaje que puede dar como resultado mejores incrustaciones de palabras.
Uso de incrustaciones de palabras
Tiene algunas opciones a la hora de utilizar embeddings de texto en su proyecto de procesamiento de lenguaje natural. Esta sección describe esas opciones.
Aprende a embeddings inscrustar
Esto requerirá una gran cantidad de datos de texto para asegurar que se aprendan incrustaciones útiles, como millones o miles de millones de palabras. Tiene dos opciones principales cuando entrena su incrustación embeddings de palabras:
- Aprender a utilizarlo de forma autónoma, donde un modelo es entrenado para aprender la incrustación, que se guarda y se utiliza como parte de otro modelo para su tarea más tarde. Este es un buen enfoque si desea utilizar la misma incrustación embeddings en varios modelos.
- Aprender en conjunto, donde la integración se aprende como parte de un gran modelo de tareas específicas. Este es un buen enfoque si sólo tiene la intención de utilizar la incrustación en una tarea.
Reutilizar una incrustación embeddings
Es común que los investigadores pongan a su disposición de forma gratuita incrustaciones de palabras previamente formadas, a menudo bajo una licencia permisiva, para que pueda utilizarlas en sus propios proyectos académicos o comerciales. Por ejemplo, tanto Word2Vec como GloVe word embeddings están disponibles para su descarga gratuita. Estos pueden ser utilizados en su proyecto en lugar de entrenar sus propias incrustaciones desde cero. Tienes dos opciones principales cuando se trata de usar embeddings pre-entrenados:
- Estática, donde la embedding se mantiene estática y se utiliza como componente de su modelo. Este es un enfoque adecuado si la embedding se adapta bien a su problema y da buenos resultados.
- Actualizado, donde el embedding pre-entrenado se utiliza para sembrar el modelo, pero el embedding se actualiza conjuntamente durante el entrenamiento del modelo. Esta puede ser una buena opción si desea sacar el máximo provecho del modelo e integrarlo en su tarea.
¿Qué opción debería utilizar?
Explore las diferentes opciones y realice unos test de prueba para ver cuál da los mejores resultados en su problema. Tal vez comience con métodos rápidos, como usar una embedding previamente entrenada, y sólo use una nueva embedding si necesitas un gran rendimiento en su problema.
➡ Aprende mucho mas de Procesamiento de Lenguaje Natural con nuestro curso:
[…] usar la incrustación/embedding de palabras en Keras para problemas de lenguaje […]
[…] usar la incrustación/embedding de palabras en Keras para problemas de lenguaje […]