
Blog

Aprender lo básico sobre la librería BeautifulSoup
Realizar un ejemplo práctico con BeautifulSoup
Antes de comenzar:
Este tutorial asume conocimientos básicos de HTML, CSS y el Modelo de Objeto de Documento. También asume cierto conocimiento de Python. Para una introducción más básica a Python le recomendamos el Curso de Python – Nivel Principiante
La mayor parte del trabajo será realizada en python anaconda en su IDE spyder. Si aún no lo tienes instala para seguir el tutorial.
¿Qué es Beautiful Soup?
“Si sólo tratas de sacar datos de una web. Beautiful Soup está aquí para ayudar “.
Beautiful Soup es una librería Python para obtener datos de HTML, XML y otros lenguajes de marcado. Digamos que has encontrado algunas páginas web que muestran datos relevantes para ti, como información de fechas, contenido, dirección, valores… pero esa web no proporciona ninguna forma de descargar los datos directamente. Beautiful Soup te ayuda a extraer contenido particular de una página web, elimina el marcado HTML, guardar la información e incluso te lo exporta en un archivo excel.
La documentación de Beautiful Soup le dará una idea de la variedad de cosas que la biblioteca Beautiful Soup le ayudará, desde aislar títulos y enlaces, extraer todo el texto de las etiquetas html, hasta alterar el HTML dentro del documento con el que está trabajando.
Instalando Beautiful Soup
Instalar Beautiful Soup es más fácil si ya tiene instalador de pip u otro Python instalado. Si no tiene pip, ejecute un tutorial rápido sobre la instalación de los módulos python para que funcione. Una vez que haya instalado la pip, ejecute el siguiente comando en el terminal para instalar Beautiful Soup:
pip install beautifulsoup4
Es posible que necesite esta línea con si tienes linux “sudo”, que le da permiso a su computadora para escribir en sus directorios de root y requiere que vuelva a ingresar su contraseña. Esta es la misma lógica detrás de la que se le pedirá que introduzca su contraseña cuando instale un nuevo programa.
Con sudo, el comando es:
sudo pip install beautifulsoup4
Aplicación: Extracción de nombres y URLs de una página HTML
Porque me gusta ver dónde está la línea de meta antes de empezar, empezaré con una visión de lo que estamos intentando crear. Asi que vamos a usar esta pagina web para hacer nuestros test y vamos a scrapearla:
https://brexitukue.wordpress.com/
usando un codigo de Python como este:
from bs4 import BeautifulSoup
import csv
import urllib3
http = urllib3.PoolManager()
web = http.request('GET', 'https://brexitukue.wordpress.com/')
soup = BeautifulSoup(web.data) # Nota que usamos la propiedad .data
titulo=soup.title.text
Una vez ejecutado este código podemos ver los facil que es extrar el título de la web. Tambien hemos creado el objeto soup donde esta toda la web en HTML. (Prueba a escribir en el terminar “titulo” y “soup”)
Selecciona una página web para escrapear
El primer paso es obtener una copia de la página o páginas HTML que desea escrapear. Puede combinar BeautifulSoup con urllib3 para trabajar directamente con las páginas de la web.
Para instalar urllib3 en conda ejecuta en el cmd de window:
conda install -c ulmo urllib3
Identificar el contenido
Una de las primeras cosas que Beautiful Soup puede ayudarnos es localizar el contenido que está enterrado dentro de la estructura HTML. Beautiful Soup te permite seleccionar el contenido en base a las etiquetas (ejemplo: soup.title.text encuentra el título de la web). Para obtener una buena visión de cómo se anidan las etiquetas en el documento, podemos utilizar el método “prettify” en nuestro objeto soup. O hacer click en el navegador para ver el codigo HTML de la web. Por ejemplo con el navegaodr mozilla sería:
abrir menu > desarrollador web > código fuente de la página y veremos un HTML como este:
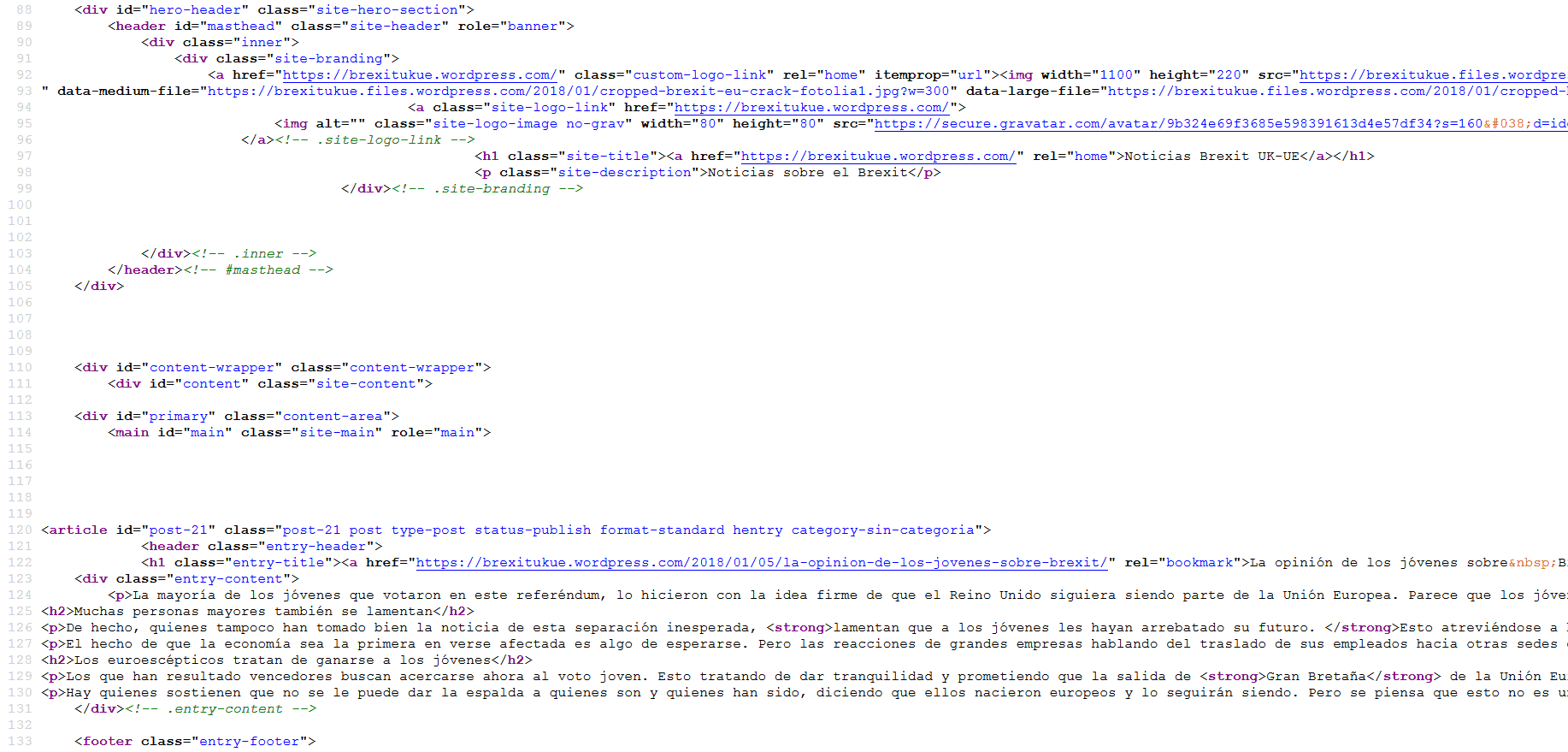
Este archivo nos será fundamental para escrapear la web.
Para los que no se acuerden muy bien de HTML dejo este esquema aqui el cual es una estructura de una web normal:

Sacando todas las url de la web
Para sacar todas las url primero leeremos con soup.find_all(‘a’) y despues haremos un for para que las veamos en el terminal. Hemos puesto la “a”porque si te fijas en el código HTML hay una etiqueta “a” antes de la url asi que la usamos de filtro.
from bs4 import BeautifulSoup
import csv
import urllib3
http = urllib3.PoolManager()
web = http.request('GET', 'https://brexitukue.wordpress.com/')
soup = BeautifulSoup(web.data) # Note the use of the .data property
links = soup.find_all('a')
titulo=soup.title.text
for link in links:
print(link.get('href'))
Cómo quitar etiquetas y escribir contenido en un archivo CSV
Necesitamos guardar los datos en un archivo para utilizarlos en otros proyectos.
Para poder limpiar las etiquetas HTML y dividir las URLs de los nombres, necesitamos aislar la información de las etiquetas ancla. Para ello, utilizaremos un poderoso y común método de Beautiful Soup: get.
Donde hicimos que imprimiera cada enlace, ahora queremos que el programa separe el enlace en sus partes y las imprima por separado. Para los nombres, podemos utilizar el método get_text() y para extraer las url el método get(‘href’) . Hacemos uso de la libreria csv por lo que añadimos algunas líneas mas de código y obtenemos el objetivo:
from bs4 import BeautifulSoup
import csv
import urllib3
f = csv.writer(open("datos1.csv", "w"))
f.writerow(["Names" , "LinkT"])
http = urllib3.PoolManager()
web = http.request('GET', 'https://brexitukue.wordpress.com/')
soup = BeautifulSoup(web.data, "lxml")
links = soup.find_all('a')
titulo=soup.title.text
for link in links:
link2 = link.get('href')
textos = link.get_text()
f.writerow([textos, link2])

⚠ Para poder abrir el archivo excel ejecuta el programa al menos 2 veces cambiando el nombre del archivo
➡ ¡Excelente! BeautifulSoup es una de las librerías más usadas en el web scraping. Inicia con nuestro curso de Web Scraping con Python para seguir aprendiendo sobre esta librería y su aplicación:
Curso de Web Scraping con Python
[…] Muchos análisis de datos, big data y proyectos de machine learning requieren técnicas de web scraping para que recojan los datos con los que usted trabajará. El lenguaje de programación Python es ampliamente utilizado en la comunidad científica de datos, y por lo tanto tiene un ecosistema de módulos y herramientas que usted puede utilizar en sus propios proyectos. En este tutorial nos enfocaremos en el módulo Beautiful Soup con un enfoque mas complejo que el ejemplo de Web scraping con Beautiful Soup I. […]
[…] ins.adsbygoogle { background: transparent !important; } Intro al Web Scraping5 (100%) 1 vote Share Tweet Google+ Email Next Article […]
hola , no me funciona con urllib3, cambie a requests, y el archivo csv me sale sin saltos de linea, será porque uso windows con python 3.7? saludos excelente página
Hola Julio, gracias por escribir! Pues no lo sé con certeza pero claro que puede ser. Muy buena idea cambiar a request ya que si una cosa no te funciona pues hay que probar con otra hasta dar con la solucion. Yo lo acabo de probar con python 3.6 y me sale tal como escribí en el post.
se puede descargar en pdf , aunque sea de pago?
No requieres pagar. Solo debes ir a la esquina superior derecha de tu navegar; y a través de la opción de Imprimir; extraerlo en PDF. Si no te lo permite, solo mira en Google como extraer una web en PDF.
¡Suerte!
funciona con spider y con python 3 ,magnífico
[…] Muchos análisis de datos, big data y proyectos de machine learning requieren técnicas de web scraping para que recojan los datos con los que usted trabajará. El lenguaje de programación Python es ampliamente utilizado en la comunidad científica de datos, y por lo tanto tiene un ecosistema de módulos y herramientas que usted puede utilizar en sus propios proyectos. En este tutorial nos enfocaremos en el módulo Beautiful Soup con un enfoque mas complejo que el ejemplo de Web scraping con Beautiful Soup I. […]