
Blog
Proyecto: Desarrollar un modelo de incrustación + CNN para el análisis de sentimientos
Las incrustaciones de palabras son una técnica para representar texto donde diferentes palabras con significado similar tienen una representación vectorial de valor real muy similar. Son un avance clave que ha conducido a un gran rendimiento de los modelos de redes neuronales en una serie de desafiantes problemas de procesamiento del lenguaje natural. En esta parte del curso, descubrirás cómo desarrollar modelos de incrustación de palabras con redes neuronales convolucionales para clasificar las críticas de películas. Después de completar esta lección, tú sabrás:
- Cómo preparar los datos del texto de la revisión de la película para la clasificación con métodos de Deep Learning.
- Cómo desarrollar un modelo de clasificación neural con incrustación de palabras y capas convolucionales.
- Cómo evaluar el modelo de clasificación neuronal desarrollado.
Vamos a empezar con la lección.
Resumen de la lección de hoy.
Esta parte del curso está dividida en las siguientes partes:
- Conjunto de datos de revisión de películas
- Preparación de datos
- Entrenamiento CNN con capa de incrustación
- Evaluación del modelo
Conjunto de datos de revisión de películas
En esta parte del curso, utilizaremos el conjunto de datos de Revisión de películas. Este conjunto de datos diseñado para el análisis de sentimientos se describió anteriormente en la lección Cómo preparar los datos de la revisión de la película para el análisis de los sentimientos de este curso. Puedes descargar el conjunto de datos desde aquí:
Movie Review Polarity Dataset (review_polarity.tar.gz, 3MB).
http://www.cs.cornell.edu/people/pabo/movie-review-data/review_polarity.tar.gz
Después de descomprimir el archivo, tendrás un directorio llamado txt_sentoken con dos subdirectorios que contienen el texto neg y pos para revisiones positivas y negativas. Las revisiones se almacenan una por archivo con una convención de nomenclatura cv000 a cv999 para cada uno de los formatos neg y pos.
Preparación de datos
La preparación del conjunto de datos de reseñas de películas se describió por primera vez en la lección Cómo preparar los datos de la revisión de la película para el análisis de los sentimientos de este curso.
En esta sección, veremos tres cosas nuevas:
- Separación de datos en equipos de entrenamiento y de prueba.
- Cargar y limpiar los datos para eliminar la puntuación y los números.
- Definir un vocabulario de palabras preferidas.
Dividir en entrenamientos y grupos de prueba
Estamos fingiendo que estamos desarrollando un sistema que puede predecir el sentimiento de una crítica cinematográfica textual como positivo o negativo. Esto significa que después de que el modelo se ha desarrollado, necesitaremos hacer predicciones sobre nuevas revisiones textuales. Esto requerirá que se realice toda la preparación de datos en esas nuevas revisiones, que en los datos de capacitación para el modelo. Nos aseguraremos de que esta restricción se incorpore en la evaluación de nuestros modelos, dividiendo los conjuntos de datos de formación y de prueba antes de cualquier preparación de datos. Esto significa que cualquier conocimiento en los datos del conjunto de pruebas que pueda ayudarnos a preparar mejor los datos (por ejemplo, las palabras utilizadas) no está disponible en la preparación de los datos utilizados para la formación del modelo.
Dicho esto, utilizaremos las últimas 100 revisiones positivas y las últimas 100 negativas como conjunto de pruebas (100 revisiones) y las restantes 1.800 revisiones como conjunto de datos de formación. Este es un entrenamiento del 90%, con una división del 10% de los datos. La división puede imponerse fácilmente utilizando los nombres de archivo de las revisiones, donde las revisiones nombradas de 000 a 899 son para datos de formación y las nombradas de 900 en adelante son para pruebas.
Carga y limpieza de revisiones
Los datos del texto ya están bastante limpios; no se requiere mucha preparación. Sin empantanarnos demasiado en los detalles, prepararemos los datos de la siguiente manera:
- Dividiremos los tokens en espacios en blanco.
- Eliminaremos todos los signos de puntuación de las palabras.
- Eliminaremos todas las palabras que no estén compuestas únicamente de caracteres alfabéticos.
- Eliminaremos todas las palabras que son palabras de parada conocidas.
- Eliminaremos todas las palabras que tengan una longitud menor o igual a un (1) carácter.
Podemos poner todos estos pasos en una función llamada clean_doc() que toma como argumento el texto crudo cargado desde un archivo y devuelve una lista de tokens limpios. También podemos definir una función load_doc() que carga un documento desde un archivo listo para su uso con la función clean_doc(). Un ejemplo de la limpieza de la primera revisión positiva se enumeran a continuación.
from nltk.corpus import stopwords
import string
import re
# cargar doc en memoria
def load_doc(filename):
# abrir el archivo como de sólo lectura
file = open(filename, 'r')
# leer todo el texto
text = file.read()
# cerrar el archivo
file.close()
return text
# convertir a doc en tokens limpias
def clean_doc(doc):
# dividido en tokens por espacio en blanco
tokens = doc.split()
# prepare a regex para el filtrado de caracteres
re_punc = re.compile('[%s]' % re.escape(string.punctuation))
# eliminar la puntuación de cada palabra
tokens = [re_punc.sub('', w) for w in tokens]
# eliminar los tokens restantes que no estén en orden alfabético
tokens = [word for word in tokens if word.isalpha()]
# filtrar las palabras de parada
stop_words = set(stopwords.words('english'))
tokens = [w for w in tokens if not w in stop_words]
# filtrar los tokens cortos
tokens = [word for word in tokens if len(word) > 1]
return tokens
# cargar el documento
filename = 'txt_sentoken/pos/cv000_29590.txt'
text = load_doc(filename)
tokens = clean_doc(text)
print(tokens)
Al ejecutar el ejemplo se imprime una larga lista de tokens limpios. Hay muchos más pasos de limpieza que tal vez quieras explorar, y te los dejo como ejercicios adicionales.
... 'creepy', 'place', 'even', 'acting', 'hell', 'solid', 'dreamy', 'depp', 'turning', 'typically', 'strong', 'performance', 'deftly', 'handling', 'british', 'accent', 'ians', 'holm', 'joe', 'goulds', 'secret', 'richardson', 'dalmatians', 'log', 'great', 'supporting', 'roles', 'big', 'surprise', 'graham', 'cringed', 'first', 'time', 'opened', 'mouth', 'imagining', 'attempt', 'irish', 'accent', 'actually', 'wasnt', 'half', 'bad', 'film', 'however', 'good', 'strong', 'violencegore', 'sexuality', 'language', 'drug', 'content']
Definir un vocabulario
Es importante definir un vocabulario de palabras conocidas cuando se utiliza un modelo de texto. Cuantas más palabras, mayor será la representación de los documentos, por lo que es importante limitar las palabras a sólo las que se consideran predictivas. Esto es difícil de saber de antemano y a menudo es importante probar diferentes hipótesis sobre cómo construir un vocabulario útil. Ya hemos visto cómo podemos eliminar la puntuación y los números del vocabulario en la sección anterior. Podemos repetir esto para todos los documentos y construir un conjunto de todas las palabras conocidas.
Podemos desarrollar un vocabulario como contador (Counter), que es un diccionario de mapeo de palabras y su conteo que nos permite actualizar y consultar fácilmente. Cada documento puede ser añadido al contador (una nueva función llamada add_doc_to_vocab()) y podemos pasar por encima de todas las revisiones en el directorio negativo y luego en el positivo (una nueva función llamada process_docs()). El ejemplo completo se enumera a continuación.
import string
import re
from os import listdir
from collections import Counter
from nltk.corpus import stopwords
# cargar doc en memoria
def load_doc(filename):
# abrir el archivo como de sólo lectura
file = open(filename, 'r')
# leer todo el texto
text = file.read()
# cerrar el archivo
file.close()
return text
# convertir a doc en tokens limpias
def clean_doc(doc):
# dividido en tokens por espacio en blanco
tokens = doc.split()
# prepare a regex para el filtrado de caracteres
re_punc = re.compile('[%s]' % re.escape(string.punctuation))
# eliminar la puntuación de cada palabra
tokens = [re_punc.sub('', w) for w in tokens]
# eliminar los tokens restantes que no estén en orden alfabético
tokens = [word for word in tokens if word.isalpha()]
# filtrar las palabras de parada
stop_words = set(stopwords.words('english'))
tokens = [w for w in tokens if not w in stop_words]
# filtrar los tokens cortos
tokens = [word for word in tokens if len(word) > 1]
return tokens
# cargar doc y añadir al vocabulario
def add_doc_to_vocab(filename, vocab):
# cargar doc
doc = load_doc(filename)
# limpiar doc
tokens = clean_doc(doc)
# actualizar contadores
vocab.update(tokens)
# cargar todos los documentos en un directorio
def process_docs(directory, vocab):
# revisar todos los archivos de la carpeta
for filename in listdir(directory):
# omitir cualquier comentario en el juego de pruebas
if filename.startswith('cv9'):
continue
# crear la ruta completa del archivo a abrir
path = directory + '/' + filename
# añadir doc al bocavulario
add_doc_to_vocab(path, vocab)
# definir vocabulario
vocab = Counter()
# añadir todos los documentos al vocabulario
process_docs('txt_sentoken/pos', vocab)
process_docs('txt_sentoken/neg', vocab)
# imprimir el tamaño del vocabulario
print(len(vocab))
# Imprimir las palabras principales en el vocabulario
print(vocab.most_common(50))
El ejemplo muestra que tenemos un vocabulario de 44.276 palabras. También podemos ver una muestra de las 50 palabras más usadas en las reseñas de películas. Ten en cuenta que este vocabulario se construyó basándose sólo en las revisiones del conjunto de datos de la capacitación.
44276
[('film', 7983), ('one', 4946), ('movie', 4826), ('like', 3201), ('even', 2262), ('good',
2080), ('time', 2041), ('story', 1907), ('films', 1873), ('would', 1844), ('much',
1824), ('also', 1757), ('characters', 1735), ('get', 1724), ('character', 1703),
('two', 1643), ('first', 1588), ('see', 1557), ('way', 1515), ('well', 1511), ('make',
1418), ('really', 1407), ('little', 1351), ('life', 1334), ('plot', 1288), ('people',
1269), ('could', 1248), ('bad', 1248), ('scene', 1241), ('movies', 1238), ('never',
1201), ('best', 1179), ('new', 1140), ('scenes', 1135), ('man', 1131), ('many', 1130),
('doesnt', 1118), ('know', 1092), ('dont', 1086), ('hes', 1024), ('great', 1014),
('another', 992), ('action', 985), ('love', 977), ('us', 967), ('go', 952),
('director', 948), ('end', 946), ('something', 945), ('still', 936)]
Podemos repasar el vocabulario y eliminar todas las palabras que tengan una baja ocurrencia, como por ejemplo, que sólo se usen una o dos veces en todas las revisiones. Por ejemplo, el siguiente fragmento recuperará sólo los tokens que aparecen 2 o más veces en todas las revisiones.
# guardar tokens con una ocurrencia mínima min_occurrence = 2 tokens = [k for k,c in vocab.items() if c >= min_occurrence] print(len(tokens))
Finalmente, el vocabulario puede ser guardado en un nuevo archivo llamado vocab.txt que luego podemos cargar y usar para filtrar las reseñas de películas antes de codificarlas para modelarlas. Definimos una nueva función llamada save_list() que guarda el vocabulario en un archivo, con una palabra por línea. Por ejemplo:
# guardar lista en archivo def save_list(lines, filename): # convertir líneas a una sola gota de texto data = '\n'.join(lines) # abrir archivo file = open(filename, 'w') # write text file.write(data) # cerrar archivo file.close() # guardar tokens en un archivo de vocabulario save_list(tokens, 'vocab.txt')
Juntando todo esto, el ejemplo completo se muestra a continuación.
import string
import re
from os import listdir
from collections import Counter
from nltk.corpus import stopwords
# cargar doc en memoria
def load_doc(filename):
# abrir el archivo como de sólo lectura
file = open(filename, 'r')
# leer todo el texto
text = file.read()
# cerrar el archivo
file.close()
return text
# convertir a doc en tokens limpios
def clean_doc(doc):
# dividido en tokens por espacio en blanco
tokens = doc.split()
# prepare a regex para el filtrado de caracteres
re_punc = re.compile('[%s]' % re.escape(string.punctuation))
# eliminar la puntuación de cada palabra
tokens = [re_punc.sub('', w) for w in tokens]
# eliminar los tokens restantes que no estén en orden alfabético
tokens = [word for word in tokens if word.isalpha()]
# filtrar palabras de parada
stop_words = set(stopwords.words('english'))
tokens = [w for w in tokens if not w in stop_words]
# filtrar las tokens cortas
tokens = [word for word in tokens if len(word) > 1]
return tokens
# cargar doc y añadir al documento
def add_doc_to_vocab(filename, vocab):
# cargar doc
doc = load_doc(filename)
# limpiar doc
tokens = clean_doc(doc)
# actualizar contadoras
vocab.update(tokens)
# cargar todos los documentos en el directorio
def process_docs(directory, vocab):
# revisar todos los archivos de la carpeta
for filename in listdir(directory):
# omita cualquier comentario en el conjunto de pruebas
if filename.startswith('cv9'):
continue
# crear la ruta completa del archivo a abrir
path = directory + '/' + filename
# añadir doc al vocabulario
add_doc_to_vocab(path, vocab)
# guardar lista en archivo
def save_list(lines, filename):
# convertir líneas a una sola gota de texto
data = '\n'.join(lines)
# abrir documento
file = open(filename, 'w')
# escribir texto
file.write(data)
# cerrar documento
file.close()
# definir vocabulario
vocab = Counter()
# añadir todos los documentos al vocabulario
process_docs('txt_sentoken/pos', vocab)
process_docs('txt_sentoken/neg', vocab)
# imprimir el tamaño del vocabulario
print(len(vocab))
# guardar tokens con una ocurrencia mínima
min_occurrence = 2
tokens = [k for k,c in vocab.items() if c >= min_occurrence]
print(len(tokens))
# guardar tokens en un archivo de vocabulario
save_list(tokens, 'vocab.txt')
Si se ejecuta el ejemplo anterior con esta adición, se muestra que el tamaño del vocabulario disminuye un poco más de la mitad de su tamaño, de 44.276 a 25.767 palabras.
25767
Ejecutando el filtro de ocurrencia mínima en el vocabulario y guardándolo en un archivo, ahora deberías tener un nuevo archivo llamado vocab.txt con sólo las palabras que nos interesan. El orden de las palabras en su archivo será diferente, pero debe parecerse al siguiente:
aberdeen dupe burt libido hamlet arlene available corners web columbia ...
Ahora estamos listos para analizar la extracción de características de las revisiones listas para el modelado.
Entrenamiento CNN con capa de incrustación
En esta ta parte, veremos una palabra incrustada mientras entrenamos una red neuronal convolucional sobre el problema de clasificación. Una incrustación de palabras es una forma de representar texto donde cada palabra en el vocabulario es representada por un vector de valor real en un espacio de alta dimensión. Los vectores se aprenden de tal manera que las palabras que tienen significados similares tendrán una representación similar en el espacio vectorial (cercano en el espacio vectorial). Esta es una representación más expresiva del texto que los métodos más clásicos como la Bag of Words, donde las relaciones entre palabras o tokens son ignoradas, o forzadas en los enfoques bigram y trigram.
La representación vectorial realmente valorada de las palabras puede verse mientras se entrena la red neuronal. Podemos hacer esto en la biblioteca de Deep Learning de Keras usando la capa de incrustación. El primer paso es cargar el vocabulario. Lo usaremos para filtrar palabras de críticas de películas que no nos interesan. Si has trabajado en la sección anterior, deberías tener un archivo local llamado vocab.txt con una palabra por línea. Podemos cargar ese archivo y construir un vocabulario como un conjunto para comprobar la validez de los tokens.
# cargar doc en la memoria def load_doc(filename): # abrir documento en modo solo lectura file = open(filename, 'r') # leer todo el texto text = file.read() # cerrar el documento file.close() return text # cargar el vocabulario vocab_filename = 'vocab.txt' vocab = load_doc(vocab_filename) vocab = set(vocab.split())
A continuación, necesitamos cargar todas las reseñas de las películas de datos de entrenamiento. Para ello podemos adaptar el process_docs() de la sección anterior para cargar los documentos, limpiarlos y devolverlos como una lista de cadenas, con un documento por cadena. Queremos que cada documento sea una cadena para facilitar la codificación como una secuencia de números enteros más adelante. Limpiar el documento implica dividir cada revisión en función del espacio en blanco, eliminar la puntuación y, a continuación, filtrar todas las tokens que no estén en el vocabulario. La función clean_doc() actualizada se muestra a continuación.
# convertir a un médico en tokens limpias
def clean_doc(doc, vocab):
# dividido en tokens por espacio en blanco
tokens = doc.split()
# prepare a regex para el filtrado de caracteres
re_punc = re.compile('[%s]' % re.escape(string.punctuation))
# eliminar la puntuación de cada palabra
tokens = [re_punc.sub('', w) for w in tokens]
# filtrar los tokens que no están en el vocabulario
tokens = [w for w in tokens if w in vocab]
tokens = ' '.join(tokens)
return tokens
El proceso actualizado docs() puede entonces llamar a clean_doc() para cada documento en un directorio dado.
# cargar todos los documentos en el directorio
def process_docs(directory, vocab, is_train):
documents = list()
# revisar todos los archivos de la carpeta
for filename in listdir(directory):
# omita cualquier comentario en el juego de pruebas
if is_train and filename.startswith('cv9'):
continue
if not is_train and not filename.startswith('cv9'):
continue
# crear la ruta completa del archivo a abrir
path = directory + '/' + filename
# cargar doc
doc = load_doc(path)
# limpiar doc
tokens = clean_doc(doc, vocab)
# añadir a la lista
documents.append(tokens)
return documents
Podemos llamar a la función process _docs() para los directorios neg y pos y combinar las revisiones en un solo entrenamiento o conjunto de datos de prueba. También podemos definir las etiquetas de clase para el conjunto de datos. La función load_clean_dataset() a continuación cargará todas las revisiones y preparará etiquetas de clase para el conjunto de datos de formación o prueba.
# cargar y limpiar dataset
def load_clean_dataset(vocab, is_train):
# cargar documentos
neg = process_docs('txt_sentoken/neg', vocab, is_train)
pos = process_docs('txt_sentoken/pos', vocab, is_train)
docs = neg + pos
# preparar las etiquetas
labels = array([0 for _ in range(len(neg))] + [1 for _ in range(len(pos))])
return docs, labels
El siguiente paso es codificar cada documento como una secuencia de números enteros. La capa de incrustación de Keras requiere entradas enteras donde cada entero se mapea a un único token que tiene una representación vectorial específica de valor real dentro de la incrustación. Estos vectores son aleatorios al principio del entrenamiento, pero durante el entrenamiento se vuelven significativos para la red. Podemos codificar los documentos de entrenamiento como secuencias de enteros usando la clase Tokenizer en la API de Keras. Primero, debemos construir una instancia de la clase y luego entrenarla en todos los documentos del conjunto de datos de entrenamiento. En este caso, desarrolla un vocabulario de todos los tokens en el conjunto de datos de entrenamiento y desarrolla un mapeo consistente de palabras en el vocabulario a números enteros únicos. Podríamos desarrollar fácilmente este mapeo nosotros mismos usando nuestro archivo de vocabulario. La función create_tokenizer() a continuación preparará un Tokenizer a partir de los datos de entrenamiento.
#instalar un tokenizador def create_tokenizer(lines): tokenizer = Tokenizer() tokenizer.fit_on_texts(lines) return tokenizer
Ahora que se ha preparado el mapeo de palabras a números enteros, podemos utilizarlo para codificar las revisiones en el conjunto de datos de formación. Podemos hacerlo llamando a la función texts_to_sequences() en el Tokenizer. También tenemos que asegurarnos de que todos los documentos tengan la misma longitud. Este es un requisito de Keras para una computación eficiente. Podríamos truncar las revisiones al tamaño más pequeño o las revisiones del zero-pad (pad con el valor 0) a la longitud máxima, o algún híbrido. En este caso, rellenaremos todas las revisiones hasta la duración de la revisión más larga del conjunto de datos de formación. Primero, podemos encontrar la revisión más larga usando la función max() en el conjunto de datos de entrenamiento y tomar su duración. Podemos entonces llamar a la función de Keras pad_sequences() para rellenar las secuencias hasta la longitud máxima añadiendo 0 valores al final.
max_length = max([len(s.split()) for s in train_docs])
print('Longitud Maxima: %d' % max_length)
Podemos entonces utilizar la longitud máxima como parámetro de una función para codificar y rellenar las secuencias.
# codificar y rellenar documentos enteros def encode_docs(tokenizer, max_length, docs): # codificación entera encoded = tokenizer.texts_to_sequences(docs) # secuencias de pads padded = pad_sequences(encoded, maxlen=max_length, padding='post') return padded
Ahora estamos listos para definir nuestro modelo de red neuronal. El modelo utilizará una capa de incrustación como primera capa oculta. La capa de incrustación requiere la especificación del tamaño del vocabulario, el tamaño del espacio vectorial de valor real, y la longitud máxima de los documentos de entrada. El tamaño del vocabulario es el número total de palabras de nuestro vocabulario, más uno para palabras desconocidas. Puede ser la longitud del conjunto de vocabulario o el tamaño del vocabulario dentro del tokenizer utilizado para codificar los documentos en números enteros, por ejemplo:
# definir el tamaño del vocaulario
vocab_size = len(tokenizer.word_index) + 1
print('Tamaño del vocabulario: %d' % vocab_size)
Usaremos un espacio vectorial de 100 dimensiones, pero podrías probar otros valores, como 50 o 150. Finalmente, la longitud máxima del documento fue calculada arriba en la variable de longitud máxima usada durante el relleno. La definición completa del modelo se enumera a continuación, incluyendo la capa de incrustación. Utilizamos una Red Neural Convolucional (CNN) ya que han demostrado tener éxito en la clasificación de documentos. Se utiliza una configuración conservadora de CNN con 32 filtros (campos paralelos para procesar palabras) y un tamaño de núcleo de 8 con una función de activación lineal rectificada (relu). Esto es seguido por una capa de agrupamiento que reduce la salida de la capa convolucional a la mitad.
A continuación, la salida 2D de la parte CNN del modelo se aplana a un vector 2D largo para representar las características extraídas por la CNN. El back-end del modelo es una capa estándar de Perceptron multicapa para interpretar las características de CNN. La capa de salida utiliza una función de activación sigmoide para emitir un valor entre 0 y 1 para el sentimiento negativo y positivo en la revisión.
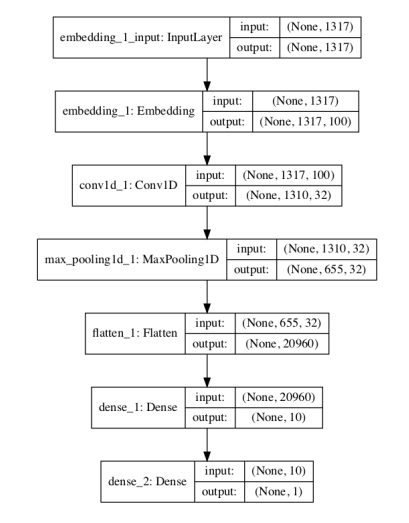
# definir el modelo def define_model(vocab_size, max_length): model = Sequential() model.add(Embedding(vocab_size, 100, input_length=max_length)) model.add(Conv1D(filters=32, kernel_size=8, activation='relu')) model.add(MaxPooling1D(pool_size=2)) model.add(Flatten()) model.add(Dense(10, activation='relu')) model.add(Dense(1, activation='sigmoid')) # compilar la red model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) # resumir el modelo definido model.summary() plot_model(model, to_file='model.png', show_shapes=True) return model
_________________________________________________________________ Layer (type) Output Shape Param # ================================================================= embedding_1 (Embedding) (None, 1317, 100) 2576800 _________________________________________________________________ conv1d_1 (Conv1D) (None, 1310, 32) 25632 _________________________________________________________________ max_pooling1d_1 (MaxPooling1 (None, 655, 32) 0 _________________________________________________________________ flatten_1 (Flatten) (None, 20960) 0 _________________________________________________________________ dense_1 (Dense) (None, 10) 209610 _________________________________________________________________ dense_2 (Dense) (None, 1) 11 ================================================================= Parametros totales: 2,812,053 Parametros entrenables: 2,812,053 Parametros no entrenables: 0 _________________________________________________________________
Un gráfico del modelo definido se guarda en un archivo con el nombre model.png.
A continuación, adaptamos la red a los datos de formación. Utilizamos una función de pérdida de entropía cruzada binaria porque el problema que estamos aprendiendo es un problema de clasificación binaria. Se utiliza la eficiente implementación de Adam de descenso por gradiente estocástico y mantenemos un seguimiento de la precisión además de las pérdidas durante el entrenamiento. El modelo se entrena durante 10 épocas, o 10 pasos a través de los datos de entrenamiento. La configuración de la red y el programa de entrenamiento fueron encontrados con un pequeño ensayo y error, pero de ninguna manera son óptimos para este problema. Si puedes obtener mejores resultados con una configuración diferente, puedes hacérmelo saber.
# cred adecuada model.fit(Xtrain, ytrain, epochs=10, verbose=2)
Después de ajustar el modelo, se guarda en un archivo llamado model.h5 para su posterior evaluación.
# guardando el modelo
model.save('model.h5')
Podemos unir todo esto. La lista completa de códigos se proporciona a continuación.
import string
import re
from os import listdir
from numpy import array
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
from keras.utils.vis_utils import plot_model
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import Flatten
from keras.layers import Embedding
from keras.layers.convolutional import Conv1D
from keras.layers.convolutional import MaxPooling1D
# cargar doc en memoria
def load_doc(filename):
# abrir el archivo como de sólo lectura
file = open(filename, 'r')
# leer todo el texto
text = file.read()
# cerrar el archivo
file.close()
return text
# convertir doc en tokens limpios
def clean_doc(doc, vocab):
# dividido en tokens por espacio en blanco
tokens = doc.split()
# prepare a regex para el filtrado de caracteres
re_punc = re.compile('[%s]' % re.escape(string.punctuation))
# eliminar la puntuación de cada palabra
tokens = [re_punc.sub('', w) for w in tokens]
# filtrar las tokens que no están en el vocabulario
tokens = [w for w in tokens if w in vocab]
tokens = ' '.join(tokens)
return tokens
# cargar todos los documentos en un directorio
def process_docs(directory, vocab, is_train):
documents = list()
# revisar todos los archivos de la carpeta
for filename in listdir(directory):
# omita cualquier comentario en el juego de pruebas
if is_train and filename.startswith('cv9'):
continue
if not is_train and not filename.startswith('cv9'):
continue
# crear la ruta completa del archivo a abrir
path = directory + '/' + filename
# cargar el documento
doc = load_doc(path)
# expediente limpio
tokens = clean_doc(doc, vocab)
# añadir a la lista
documents.append(tokens)
return documents
# cargar y limpiar un conjunto de datos
def load_clean_dataset(vocab, is_train):
# cargar documentos
neg = process_docs('txt_sentoken/neg', vocab, is_train)
pos = process_docs('txt_sentoken/pos', vocab, is_train)
docs = neg + pos
# preparar las etiquetas
labels = array([0 for _ in range(len(neg))] + [1 for _ in range(len(pos))])
return docs, labels
# instalar un tokenizador
def create_tokenizer(lines):
tokenizer = Tokenizer()
tokenizer.fit_on_texts(lines)
return tokenizer
# codificar y rellenar documentos enteros
def encode_docs(tokenizer, max_length, docs):
# codificación entera
encoded = tokenizer.texts_to_sequences(docs)
# secuencias de pads
padded = pad_sequences(encoded, maxlen=max_length, padding='post')
return padded
# definir el modelo
def define_model(vocab_size, max_length):
model = Sequential()
model.add(Embedding(vocab_size, 100, input_length=max_length))
model.add(Conv1D(filters=32, kernel_size=8, activation='relu'))
model.add(MaxPooling1D(pool_size=2))
model.add(Flatten())
model.add(Dense(10, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
# compilar red
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
# resumir el modelo definido
model.summary()
plot_model(model, to_file='model.png', show_shapes=True)
return model
# cargar el vocabulario
vocab_filename = 'vocab.txt'
vocab = load_doc(vocab_filename)
vocab = set(vocab.split())
# cargar datos de entrenamiento
train_docs, ytrain = load_clean_dataset(vocab, True)
# crear el tokenizador
tokenizer = create_tokenizer(train_docs)
# definir el tamaño del vocabulario
vocab_size = len(tokenizer.word_index) + 1
print('Tamaño del vocabulario: %d' % vocab_size)
# calcular la longitud máxima de la secuencia
max_length = max([len(s.split()) for s in train_docs])
print('Longitud Maxima: %d' % max_length)
# datos codificados
Xtrain = encode_docs(tokenizer, max_length, train_docs)
# definir modelo
model = define_model(vocab_size, max_length)
# red adecuada
model.fit(Xtrain, ytrain, epochs=10, verbose=2)
# guardar el modelo
model.save('model.h5')
Al ejecutar el ejemplo se obtendrá primero un resumen del vocabulario del conjunto de datos de la capacitación (25.768) y la longitud máxima de la secuencia de entrada en palabras (1.317). El ejemplo debería ejecutarse en unos minutos y el modelo ajustado se guardará en un archivo.
... Tamaño del vocabulario: 25768 Longitud Maxima: 1317 Epoch 1/10 8s - loss: 0.6927 - acc: 0.4800 Epoch 2/10 7s - loss: 0.6610 - acc: 0.5922 Epoch 3/10 7s - loss: 0.3461 - acc: 0.8844 Epoch 4/10 7s - loss: 0.0441 - acc: 0.9889 Epoch 5/10 7s - loss: 0.0058 - acc: 1.0000 Epoch 6/10 7s - loss: 0.0024 - acc: 1.0000 Epoch 7/10 7s - loss: 0.0015 - acc: 1.0000 Epoch 8/10 7s - loss: 0.0011 - acc: 1.0000 Epoch 9/10 7s - loss: 8.0111e-04 - acc: 1.0000 Epoch 10/10 7s - loss: 5.4109e-04 - acc: 1.0000
Evaluar modelo
En esta sección, evaluaremos el modelo entrenado y lo usaremos para hacer predicciones sobre nuevos datos. Primero, podemos usar la función evaluate() incorporada para estimar la habilidad del modelo tanto en el conjunto de datos de entrenamiento como en el de pruebas. Esto requiere que carguemos y codifiquemos tanto los conjuntos de datos de formación como los de prueba.
# cargar todos los comentarios
train_docs, ytrain = load_clean_dataset(vocab, True)
test_docs, ytest = load_clean_dataset(vocab, False)
# crear el tokenizador
tokenizer = create_tokenizer(train_docs)
# definir el tamaño del vocabulario
vocab_size = len(tokenizer.word_index) + 1
print('Tamaño del Vocabulario: %d' % vocab_size)
# calcular la longitud máxima de la secuencia
max_length = max([len(s.split()) for s in train_docs])
print('Longitud Maxima: %d' % max_length)
# datos codificados
Xtrain = encode_docs(tokenizer, max_length, train_docs)
Xtest = encode_docs(tokenizer, max_length, test_docs)
Podemos entonces cargar el modelo y evaluarlo en ambos conjuntos de datos e imprimir la precisión
# cargar el modelo
model = load_model('model.h5')
# evaluar el modelo sobre el conjunto de datos de la capacitación
_, acc = model.evaluate(Xtrain, ytrain, verbose=0)
print('Exactitud de la prueba: %f' % (acc*100))
# evaluar modelo en conjunto de datos de prueba
_, acc = model.evaluate(Xtest, ytest, verbose=0)
print('Precisión de la prueba: %f' % (acc*100))
Los nuevos datos deben prepararse utilizando los mismos esquemas de codificación y codificación de texto que se utilizaron en el conjunto de datos de formación. Una vez preparado, se puede hacer una predicción llamando a la función predict() en el modelo. La función debajo llamada predict_sentiment() codificará y rellenará un texto de revisión de película dado, y devolverá una predicción tanto en términos de porcentaje como de etiqueta.
# clasificar una crítica como negativa o positiva def predict_sentiment(review, vocab, tokenizer, max_length, model): # revisión sin reservas line = clean_doc(review, vocab) # codificación y revisión de pads padded = encode_docs(tokenizer, max_length, [line]) # predecir el sentimiento yhat = model.predict(padded, verbose=0) # recuperar el porcentaje previsto y etiquetar percent_pos = yhat[0,0] if round(percent_pos) == 0: return (1-percent_pos), 'NEGATIVE' return percent_pos, 'POSITIVE'
Podemos probar este modelo con dos críticas de películas ad hoc. El ejemplo completo se enumera a continuación.
import string
import re
from os import listdir
from numpy import array
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
from keras.models import load_model
# cargar doc en memoria
def load_doc(filename):
# abrir el archivo como de sólo lectura
file = open(filename, 'r')
# leer todo el texto
text = file.read()
# cerrar el archivo
file.close()
return text
# convertir el doc en tokens limpios
def clean_doc(doc, vocab):
# dividido en tokens por espacio en blanco
tokens = doc.split()
# prepare a regex para el filtrado de caracteres
re_punc = re.compile('[%s]' % re.escape(string.punctuation))
# eliminar la puntuación de cada palabra
tokens = [re_punc.sub('', w) for w in tokens]
# filtrar los tokens que no están en el vocabulario
tokens = [w for w in tokens if w in vocab]
tokens = ' '.join(tokens)
return tokens
# cargar todos los documentos en un directorio
def process_docs(directory, vocab, is_train):
documents = list()
# revisar todos los archivos de la carpeta
for filename in listdir(directory):
# omita cualquier comentario en el conjunto de pruebas
if is_train and filename.startswith('cv9'):
continue
if not is_train and not filename.startswith('cv9'):
continue
# crear la ruta completa del archivo a abrir
path = directory + '/' + filename
# cargar el documento
doc = load_doc(path)
# expediente limpio
tokens = clean_doc(doc, vocab)
# añadir a la lista
documents.append(tokens)
return documents
# cargar y limpiar un conjunto de datos
def load_clean_dataset(vocab, is_train):
# cargar documentos
neg = process_docs('txt_sentoken/neg', vocab, is_train)
pos = process_docs('txt_sentoken/pos', vocab, is_train)
docs = neg + pos
# preparar las etiquetas
labels = array([0 for _ in range(len(neg))] + [1 for _ in range(len(pos))])
return docs, labels
# instalar un tokenizador
def create_tokenizer(lines):
tokenizer = Tokenizer()
tokenizer.fit_on_texts(lines)
return tokenizer
# codificar y rellenar documentos enteros
def encode_docs(tokenizer, max_length, docs):
# codificación entera
encoded = tokenizer.texts_to_sequences(docs)
# secuencias de pads
padded = pad_sequences(encoded, maxlen=max_length, padding='post')
return padded
# clasificar una crítica como negativa o positiva
def predict_sentiment(review, vocab, tokenizer, max_length, model):
# revisión sin reservas
line = clean_doc(review, vocab)
# codificación y revisión de pads
padded = encode_docs(tokenizer, max_length, [line])
#predecir el sentimiento
yhat = model.predict(padded, verbose=0)
#recuperar el porcentaje previsto y etiquetar
percent_pos = yhat[0,0]
if round(percent_pos) == 0:
return (1-percent_pos), 'NEGATIVE'
return percent_pos, 'POSITIVE'
#cargar el vocabulario
vocab_filename = 'vocab.txt'
vocab = load_doc(vocab_filename)
vocab = set(vocab.split())
#cargar todos los comentarios
train_docs, ytrain = load_clean_dataset(vocab, True)
test_docs, ytest = load_clean_dataset(vocab, False)
# crear el tokenizador
tokenizer = create_tokenizer(train_docs)
# definir el tamaño del vocabulario
vocab_size = len(tokenizer.word_index) + 1
print('Tamaño del vocabulario: %d' % vocab_size)
# calcular la longitud máxima de la secuencia
max_length = max([len(s.split()) for s in train_docs])
print('Longitud Maxima: %d' % max_length)
# codificar datos
Xtrain = encode_docs(tokenizer, max_length, train_docs)
Xtest = encode_docs(tokenizer, max_length, test_docs)
# cargar el modelo
model = load_model('model.h5')
# evaluar el modelo sobre el conjunto de datos de la formación
_, acc = model.evaluate(Xtrain, ytrain, verbose=0)
print('Precision del entrenamiento: %.2f' % (acc*100))
# evaluar el modelo en el conjunto de datos de prueba
_, acc = model.evaluate(Xtest, ytest, verbose=0)
print('Precision de la prueba: %.2f' % (acc*100))
# texto positivo de la prueba
text = 'Todos disfrutaran de esta pelicula. Me encanta, recomendado!'
percent, sentiment = predict_sentiment(text, vocab, tokenizer, max_length, model)
print('Revision: [%s]\nSentiment: %s (%.3f%%)' % (text, sentiment, percent*100))
# test de texto negativo
text = 'Esta es una mala pelicula. No la mires. Es una perdida.'
percent, sentiment = predict_sentiment(text, vocab, tokenizer, max_length, model)
print('Revision: [%s]\nSentimiento: %s (%.3f%%)' % (text, sentiment, percent*100))
Al ejecutar el ejemplo, primero se imprime la habilidad del modelo en el conjunto de datos de entrenamiento y prueba. Podemos ver que el modelo alcanza una precisión del 100% en el conjunto de datos de entrenamiento y del 87,5% en el conjunto de datos de prueba, una puntuación impresionante.
A continuación, podemos ver que el modelo hace la predicción correcta en dos críticas de películas artificiales. Podemos ver que el porcentaje o confianza de la predicción es cercano al 50% para ambos, esto puede deberse a que las dos revisiones artificiales son muy cortas y el modelo espera secuencias de 1.000 o más palabras.
Dada la naturaleza estocástica de las redes neuronales, sus resultados específicos pueden variar. Considera la posibilidad de ejecutar el ejemplo varias veces.
Precision del entrenamiento: 100.00 Precision de la prueba: 87.50 Revision: [Todos disfrutaran de esta pelicula. Me encanta, recomendado!] Sentimiento: POSITIVE (55.431%) Revision: [Esta es una mala pelicula. No la mires. Es una perdida.] Sentimiento: NEGATIVE (54.746%)
Extensiones
En esta sección se enumeran algunas ideas para ampliar el tutorial que puede que desees explorar:
- Limpieza de datos: Explora una mejor limpieza de datos, tal vez dejando algo de puntuación en el tacto o normalizando las contracciones.
- Secuencias Truncadas: Rellenar todas las secuencias a la longitud de la secuencia más larga podría ser extremo si la secuencia más larga es muy diferente a todas las otras revisiones. Estudiar la distribución de las duraciones de las revisiones y truncar las revisiones a una duración media.
- Vocabulario truncado: Eliminamos palabras poco frecuentes, pero todavía teníamos un gran vocabulario de más de 25.000 palabras. Explora la posibilidad de reducir aún más el tamaño del vocabulario y el efecto en la habilidad del modelo.
- Filtros y tamaño del núcleo: El número de filtros y el tamaño del núcleo son importantes para modelar la habilidad y no fueron afinados. Explora la sintonización de estos dos parámetros de CNN.
- Épocas y tamaño de lote: El modelo parece ajustarse rápidamente al conjunto de datos de formación. Explora configuraciones alternativas del número de épocas de entrenamiento y tamaño de lote y utiliza el conjunto de datos de prueba como un conjunto de validación para elegir un mejor punto de parada para el entrenamiento del modelo.
- Red más profunda: Explora si una red más profunda resulta en una mejor habilidad, ya sea en términos de capas de CNN, capas de MLP y ambas.
Pre-entrenamiento e incrustación. Explora el pre-entrenamiento de una palabra de Word2Vec incrustada en el modelo y el impacto en la habilidad del modelo con y sin ajuste fino durante el entrenamiento. - Utiliza GloVe Embedding: Explora la carga de la incrustación de GloVe previamente entrenada y el impacto en la habilidad del modelo con y sin ajuste fino durante el entrenamiento.
- Revisiones de pruebas más largas: Explora si la habilidad de las predicciones del modelo depende de la duración de las reseñas de películas, como se sospecha en la sección final sobre la evaluación del modelo.
- Modelo Final de Entrenamiento: Entrenar un modelo final sobre todos los datos disponibles y utilizarlo para hacer predicciones en críticas de películas ad hoc reales de Internet.
Si exploras alguna de estas extensiones, me encantaría saberlo. Saludos.
➡ Continúa aprendiendo con nosotros en nuestro curso:
Curso de Natural Language Processing con Deep Learning
Muchas gracias por tu serie de artículos. He probado este mismo código para una clasificación binaria de emails con etiquetas Spam y No spam con una precisión del 97%. Aquí os dejo el repositorio con el jupyter notebook y el dataset que usé: https://github.com/GGP00/NLP-and-CNN-binary-classification
Perfecto GGP00 gracias!