
Blog
Proyecto: Desarrollar un modelo de generación de subtítulos de imágenes neuronales
La generación de subtítulos es un problema de inteligencia artificial en el que se debe generar una descripción textual para una fotografía determinada. Requiere ambos métodos de visión por ordenador para entender el contenido de la imagen y un modelo de lenguaje del campo del procesamiento del lenguaje natural para convertir la comprensión de la imagen en palabras en el orden correcto. Recientemente, los métodos de Deep Learning han logrado resultados de vanguardia en ejemplos de este problema.
Los métodos de Deep Learning han demostrado resultados de vanguardia en problemas de generación de subtítulos. Lo más impresionante de estos métodos es que se puede definir un único modelo de extremo a extremo para predecir una leyenda con una foto dada, en lugar de requerir una sofisticada preparación de datos o una serie de modelos diseñados específicamente. En este tutorial, descubrirás cómo desarrollar un modelo de Deep Learning de subtitulado de fotos desde cero. Después de completar este tutorial, tú sabrás:
- Cómo preparar fotos y datos de texto para entrenar un modelo de Deep Learning.
- Cómo diseñar y entrenar un modelo de generación de subtítulos de Deep Learning.
- Cómo evaluar un modelo de generación de subtítulos de trenes y utilizarlo para subtitular fotografías completamente nuevas.
Vamos a empezar.
Descripción general del tutorial
Este tutorial se divide en las siguientes partes:
- Conjunto de datos de fotos y pies de foto
- Preparar datos fotográficos
- Preparar datos de texto
- Desarrollar un modelo de aprendizaje profundo
- Evaluar modelo
- Generar nuevos subtítulos
Conjunto de datos de fotos y pies de foto
En el tutorial en el que trabajaremos hoy, utilizaremos el conjunto de datos de Flickr8k. Este conjunto de datos tan útil, se introdujo anteriormente en el capítulo Cómo preparar un conjunto de datos de pies de foto para el modelado. El conjunto de datos está disponible de forma totalmente gratuita. Debes completar un formulario de solicitud y los enlaces al conjunto de datos se te enviarán por correo electrónico. Me encantaría enlazar con ellos por usted, pero la dirección de correo electrónico lo solicita expresamente: Por favor, no redistribuyas el conjunto de datos . Puedes utilizar el siguiente enlace para solicitar el conjunto de datos:
- Formulario de solicitud de conjuntos de datos.
https://illinois.edu/fb/sec/1713398
En poco tiempo, recibirás un correo electrónico que contiene enlaces a dos archivos de suma importancia:
- Flickr8k Dataset.zip (1 Gigabyte) Un archivo con todas las fotografías.
- Flickr8k text.zip (2.2 Megabytes) Un archivo de todas las descripciones de texto para fotografías.
Luego, tendrás que descargar los conjuntos de datos y descomprimirlos en tu directorio de trabajo actual. Con lo cual, tú tendrá dos directorios:
- Flicker8kDataset: Contiene 8092 fotografías en formato JPEG (sí, el nombre del directorio lo escribe ‘Flicker’ no ‘Flickr’).
- Flickr8k text: Contiene una serie de archivos que contienen diferentes fuentes de descripción de las fotografías.
El conjunto de datos que tienes en tus manos, contiene otro conjunto de datos (valga la redundancia) de formación predefinido (con 6.000 imágenes), un conjunto de datos de desarrollo (con 1.000 imágenes) y finalmente viene con un conjunto de datos de prueba con (1.000 imágenes). Una medida que se puede utilizar para evaluar la habilidad del modelo son las puntuaciones BLEU. Como referencia, a continuación se presentan algunas puntuaciones BLEU de los parques de pelota para los modelos hábiles cuando se evalúan en el conjunto de datos de la prueba (tomado del documento de 2017 Dónde poner la imagen en un generador de subtítulos de imagen o Where to put the Image in an Image Caption Generator):
- BLEU-1: 0,401 a 0,578.
- BLEU-2: 0,176 a 0,390.
- BLEU-3: 0,099 a 0,260.
- BLEU-4: 0,059 a 0,170.
Vamos a describir mucho mejor la métrica BLEU más adelante cuando trabajemos en la evaluación de nuestro modelo final. A continuación, veamos cómo cargar las imágenes.
Preparar datos fotográficos
Utilizaremos un modelo previamente entrenado para interpretar el contenido de las fotos. Hay muchos modelos para elegir. En este caso, utilizaremos el modelo del Oxford Visual Geometry Group, o VGG, que ganó el concurso ImageNet en 2014. Keras proporciona directamente este modelo pre-entrenado. Ten en cuenta que la primera vez que utilizas este modelo, Keras descargará los pesos de los modelos de Internet, que son de unos 500 Megabytes. Esto puede tardar unos minutos dependiendo de tu conexión a Internet. Nótese que el uso del modelo VGG pre-entrenado se introdujo en el Capítulo Cómo cargar y utilizar un modelo de reconocimiento de objetos preconfigurado.
Podríamos usar este modelo como parte de un modelo de pie de foto más amplio. El problema es que se trata de un modelo muy grande y cada vez que queremos probar la configuración de un nuevo modelo de lenguaje (downstream) es muy redundante. En su lugar, podemos precalcular las características de la foto utilizando el modelo pre-aprendido y guardarlo en un nuevo archivo. A continuación, podemos cargar estas características más tarde y alimentarlas en nuestro modelo como la interpretación de una foto dada en el conjunto de datos. No es diferente a pasar la foto por el modelo completo de VGG; es sólo que lo habremos hecho una vez de antemano.
Esta es una optimización que hará que el entrenamiento de nuestros modelos sea más rápido y consuma menos memoria. Podemos cargar el modelo VGG en Keras usando la clase VGG. Eliminaremos la última capa del modelo cargado, ya que es el modelo utilizado para predecir la clasificación de una foto. No estamos interesados en clasificar imágenes, pero sí en la representación interna de la foto justo antes de que se haga una clasificación. Estas son las características que el modelo ha extraído de la foto.
Keras también proporciona herramientas para remodelar la foto cargada en el tamaño preferido para el modelo (por ejemplo, imagen de 3 canales de 224 x 224 píxeles). A continuación se muestra una función llamada extract_features() que, con un nombre de directorio, cargará cada foto, la preparará para VGG y recopilará las características predichas del modelo VGG. Las características de la imagen son un vector unidimensional de 4.096 elementos.
La función devuelve un diccionario de identificador de imagen a las características de la imagen.
# extraer características de cada foto del directorio
def extract_features(directory):
# cargar el modelo
model = VGG16()
# reestructurar el modelo
model.layers.pop()
model = Model(inputs=model.inputs, outputs=model.layers[-1].output)
# resumir
model.summary()
# extraer características de cada foto
features = dict()
for name in listdir(directory):
# cargar una imagen desde un archivo
filename = directory +'/'+ nameimage = load_img(filename, target_size=(224, 224))
# convertir los píxeles de la imagen en una matriz NumPy
image = img_to_array(image)
# remodelar los datos para el modelo
image = image.reshape((1, image.shape[0], image.shape[1], image.shape[2]))
# preparar la imagen para el modelo VGG
image = preprocess_input(image)
# obtenga características
feature = model.predict(image, verbose=0)
# obtener identificación de la imagen
image_id = name.split('.')[0]
# función de tienda
features[image_id] = feature
print('>%s'% name)
return features
Podemos llamar a esta función para preparar los datos de las fotos para probar nuestros modelos, y luego guardar el diccionario resultante en un archivo llamado features.pkl. El ejemplo completo se enumera a continuación.
from os import listdir
from os import path
from pickle import dump
from keras.applications.vgg16 import VGG16
from keras.preprocessing.image import load_img
from keras.preprocessing.image import img_to_array
from keras.applications.vgg16 import preprocess_input
from keras.models import Model
# extraer características de cada foto del directorio
def extract_features(directory):
# cargar el modelo
model = VGG16()
# reestructurar el modelo
model.layers.pop()
model = Model(inputs=model.inputs, outputs=model.layers[-1].output)
# resumir
model.summary()
# extraer características de cada foto
features = dict()
for name in listdir(directory):
# cargar una imagen desde un archivo
filename = directory +'/'+ nameimage = load_img(filename, target_size=(224, 224))
# convertir los píxeles de la imagen en una matriz NumPy
image = img_to_array(image)
# remodelar los datos para el modelo
image = image.reshape((1, image.shape[0], image.shape[1], image.shape[2]))
# preparar la imagen para el modelo VGG
image = preprocess_input(image)
# obtenga características
feature = model.predict(image, verbose=0)
# obtener identificación de la imagen
image_id = name.split('.')[0]
# función de tienda
features[image_id] = feature
print('>%s'% name)
return features
# extraer características de todas las imágenes
directory ='Flicker8k_Dataset'features = extract_features(directory)
print('Extracted Features: %d'% len(features))
# guardar archivo
dump(features, open('features.pkl','wb'))
La ejecución de este paso de preparación de datos puede llevar un tiempo dependiendo de su hardware, quizás una hora en la CPU con una estación de trabajo moderna. Al final de la ejecución, tendrá las características extraídas almacenadas en el archivo features.pkl para su uso posterior. Este archivo tendrá un tamaño de unos pocos cientos de Megabytes.
Preparar datos de texto
El conjunto de datos contiene múltiples descripciones para cada fotografía y el texto de las descripciones requiere una limpieza mínima. Nota que en el Capítulo Cómo preparar un conjunto de datos de pies de foto para el modelado, se describe una investigación más completa sobre cómo se pueden preparar estos datos de texto. Primero, cargaremos el archivo que contiene todas las descripciones.
# carga doc en la memoria def load_doc(filename): # abrir el archivo como de sólo lectura file = open(filename,'r') # leer todo el texto text = file.read() # cerrar el archivo file.close() return text filename ='Flickr8k_text/Flickr8k.token.txt' # cargue las descripciones doc = load_doc(filename)
Cada foto tiene un identificador único. Este identificador se utiliza en el nombre de archivo de la foto y en el archivo de texto de las descripciones. A continuación, repasaremos la lista de descripciones de las fotos. A continuación se define una función llamada load_descriptions() que, dado el texto del documento cargado, devolverá un diccionario de identificadores de fotos a las descripciones. Cada identificador de foto se asigna a una lista de una o más descripciones textuales.
# extraer descripciones para las imágenes
def load_descriptions(doc):
mapping = dict()
# líneas de proceso
for line in doc.split('\n'):
# línea dividida por espacio en blanco
tokens = line.split()
if len(line) < 2:
continue
# toma el primer token como la identificación de la imagen, el resto como la descripción
image_id, image_desc = tokens[0], tokens[1:]
# eliminar el nombre de archivo de la identificación de la imagen
image_id = image_id.split('.')[0]
# convertir los tokens de descripción de nuevo a cadena de texto
image_desc =''.join(image_desc)
# crear la lista si es necesario
if image_id not in mapping:
mapping[image_id] = list()
# descripción de la tienda
mapping[image_id].append(image_desc)
return mapping
# analizar descripciones
descriptions = load_descriptions(doc)
print('Loaded: %d'% len(descriptions))
A continuación, tenemos que limpiar el texto de descripción. Las descripciones ya están tokenizadas y es fácil trabajar con ellas. Limpiaremos el texto de las siguientes maneras para reducir el tamaño del vocabulario de las palabras con las que tendremos que trabajar:
- Conviertir todas las palabras a minúsculas.
- Eliminar todos los signos de puntuación.
- Elimina todas las palabras que tengan un carácter o menos de longitud (por ejemplo,’a’).
- Elimina todas las palabras que contengan números.
A continuación se define la función clean_descriptions() que, dado el diccionario de identificadores de imagen a las descripciones, pasa por cada descripción y limpia el texto.
def clean_descriptions(descriptions):
# preparar a regex para el filtrado de caracteres
re_punc = re.compile('[%s]'% re.escape(string.punctuation))
for key, desc_list in descriptions.items():
for i in range(len(desc_list)):
desc = desc_list[i]
# tokenize
desc = desc.split()
# convertir a minúsculas
desc = [word.lower() for word in desc]
# Elimina la puntuación de cada ficha.
desc = [re_punc.sub('', w) for w in desc]
# Quitar la horca
's'and'a'desc = [word for word in desc if len(word)>1]
# Quitar las fichas con números en ellas
desc = [word for word in desc if word.isalpha()]
# store como cadena
desc_list[i] =''.join(desc)
# descripciones limpias
clean_descriptions(descriptions)
Una vez limpio, podemos resumir el tamaño del vocabulario. Idealmente, queremos un vocabulario que sea a la vez expresivo y lo más pequeño posible. Un vocabulario más pequeño resultará en un modelo más pequeño que entrenará más rápido. Como referencia, podemos transformar las descripciones limpias en un conjunto e imprimir su tamaño para tener una idea del tamaño de nuestro vocabulario del conjunto de datos.
# convertir las descripciones cargadas en un vocabulario de palabras
def to_vocabulary(descriptions):
# construir una lista de todas las cadenas de descripción
all_desc = set()
for key in descriptions.keys():
[all_desc.update(d.split()) for d in descriptions[key]]
return all_desc
# resumir el vocabulario
vocabulary = to_vocabulary(descriptions)
print('Vocabulary Size: %d'% len(vocabulary))
Finalmente, podemos guardar el diccionario de identificadores de imagen y descripciones en un nuevo archivo llamado descriptions.txt , con un identificador de imagen y una descripción por línea. A continuación se define la función save_doc() que, dado un diccionario que contiene el mapeo de identificadores a descripciones y un nombre de archivo, guarda el mapeo a archivo.
# guardar las descripciones en un archivo, una por línea def save_descriptions(descriptions, filename): lines = list() for key, desc_list in descriptions.items(): for desc in desc_list: lines.append(key +''+ desc) data ='\n'.join(lines) file = open(filename,'w') file.write(data) file.close() # guardar descripciones save_doc(descriptions,'descriptions.txt')
Poniendo todo esto junto, la lista completa se proporciona a continuación.
import string
import re
# carga doc en la memoria
def load_doc(filename):
# abrir el archivo como de sólo lectura
file = open(filename,'r')
# leer todo el texto
text = file.read()
# cerrar el archivo
file.close()
return text
# extraer descripciones para las imágenes
def load_descriptions(doc):
mapping = dict()
# líneas de proceso
for line in doc.split('\n'):
# línea dividida por espacio en blanco
tokens = line.split()
if len(line) < 2: continue # toma el primer token como la identificación de la imagen, el resto como la descripción image_id, image_desc = tokens[0], tokens[1:] # eliminar el nombre de archivo de la identificación de la imagen image_id = image_id.split('.')[0] # convertir los tokens de descripción de nuevo a cadena de texto image_desc =''.join(image_desc) # crear la lista si es necesario if image_id not in mapping: mapping[image_id] = list() # descripción de la tienda mapping[image_id].append(image_desc) return mapping def clean_descriptions(descriptions): # preparar a regex para el filtrado de caracteres re_punc = re.compile('[%s]'% re.escape(string.punctuation)) for key, desc_list in descriptions.items(): for i in range(len(desc_list)): desc = desc_list[i] # tokenize desc = desc.split() # convertir a minúsculas desc = [word.lower() for word in desc] # Elimina la puntuación de cada ficha. desc = [re_punc.sub('', w) for w in desc] # Quitar la horca 's'and'a'desc = [word for word in desc if len(word)>1]
# Quitar las fichas con números en ellas
desc = [word for word in desc if word.isalpha()]
# store como cadena
desc_list[i] =''.join(desc)
# convertir las descripciones cargadas en un vocabulario de palabras
def to_vocabulary(descriptions):
# crear una lista de todas las cadenas de descripción
all_desc = set()
for key in descriptions.keys():
[all_desc.update(d.split()) for d in descriptions[key]]
return all_desc
# guardar descripciones en un archivo, una por línea
def save_descriptions(descriptions, filename):
lines = list()
for key, desc_list in descriptions.items():
for desc in desc_list:
lines.append(key +''+ desc)
data ='\n'.join(lines)
file = open(filename,'w')
file.write(data)
file.close()
filename ='Flickr8k_text/Flickr8k.token.txt'
# cargar descripciones
doc = load_doc(filename)
# descripciones de análisis
descriptions = load_descriptions(doc)
print('Loaded: %d'% len(descriptions))
# limpiar descriptiones
clean_descriptions(descriptions)
# resumir vocabulario
vocabulary = to_vocabulary(descriptions)
print('Vocabulary Size: %d'% len(vocabulary))
# guardar archivo
save_descriptions(descriptions,'descriptions.txt')
Al ejecutar el ejemplo, primero se imprime el número de descripciones de fotos cargadas (8.092) y el tamaño del vocabulario limpio (8.763 palabras).
Loaded: 8,092 Vocabulary Size: 8,763
Finalmente, las descripciones limpias se escriben en descriptions.txt. Echando un vistazo al archivo, podemos ver que las descripciones están listas para el modelado. El orden de las descripciones en su archivo puede variar.
2252123185_487f21e336 bunch on people are seated in stadium 2252123185_487f21e336 crowded stadium is full of people watching an event 2252123185_487f21e336 crowd of people fill up packed stadium 2252123185_487f21e336 crowd sitting in an indoor stadium 2252123185_487f21e336 stadium full of people watch game ...
Desarrollar un modelo de Deep Learning
En esta sección, definiremos el modelo de Deep Learning y lo adaptaremos al conjunto de datos de la formación. Esta sección se divide en las siguientes partes:
- Carga de datos.
- Definición del modelo.
- Adaptación del modelo.
- Ejemplo completo.
Carga de datos
Primero, debemos cargar la foto y los datos de texto preparados para que podamos usarlos para adaptarlos al modelo. Vamos a entrenar los datos de todas las fotos y pies de foto en el conjunto de datos de entrenamiento. Durante la formación, vamos a supervisar el rendimiento del modelo en el conjunto de datos de desarrollo y utilizar ese rendimiento para decidir cuándo guardar los modelos en un archivo.
El conjunto de datos de entrenamiento y desarrollo han sido predefinidos en los archivos Flickr8k.trainImages.txt y Flickr8k.devImages.txt respectivamente, que contienen listas de nombres de archivos de fotos. A partir de estos nombres de archivo, podemos extraer los identificadores de fotos y utilizarlos para filtrar fotos y descripciones de cada conjunto. La función load_set() que se muestra a continuación cargará un conjunto predefinido de identificadores dado el nombre de archivo del tren o de los conjuntos de desarrollo.
# carga doc en la memoria
def load_doc(filename):
# abrir el archivo como de sólo lectura
file = open(filename,'r')
# leer todo el texto
text = file.read()
# cerrar el archivo
file.close()
return text
# cargar una lista predefinida de identificadores de fotos
def load_set(filename):
doc = load_doc(filename)
dataset = list()
# proceso línea por línea
for line in doc.split('\n'):
# saltar líneas vacías
if len(line) < 1:
continue
# obtener el identificador de la imagen
identifier = line.split('.')[0]
dataset.append(identifier)
return set(dataset)
Ahora, podemos cargar las fotos y descripciones usando el conjunto predefinido de identificadores de entrenamiento o desarrollo. A continuación se muestra la función load_clean_descriptions() que carga las descripciones de texto limpias de descriptions.txt para un conjunto dado de identificadores, y devuelve un diccionario de identificadores a las listas de descripciones de texto.
El modelo que desarrollaremos generará una leyenda con una foto, y la leyenda se generará palabra por palabra. La secuencia de palabras generadas previamente se proporcionará como entrada. Por lo tanto, necesitaremos una primera palabra para iniciar el proceso de generación y una última palabra para señalar el final de la leyenda. Usaremos las cadenas starteq y endseq para este propósito. Estos tokens se añaden a las descripciones cargadas a medida que se cargan. Es importante hacer esto ahora antes de codificar el texto para que los tokens también se codifiquen correctamente.
# cargar descripciones limpias en la memoria
def load_clean_descriptions(filename, dataset):
# cargar documento
doc = load_doc(filename)
descriptions = dict()
for line in doc.split('\n'):
# línea dividida por espacio en blanco
tokens = line.split()
# Separar la identificación de la descripción
image_id, image_desc = tokens[0], tokens[1:]
# saltar imágenes que no están en el set
if image_id in dataset:
# crear lista
if image_id not in descriptions:
descriptions[image_id] = list()
# envolver la descripción en tokens
desc ='startseq'+''.join(image_desc) +'endseq'
# tienda
descriptions[image_id].append(desc)
return descriptions
A continuación, podemos cargar las características de la foto para un conjunto de datos determinado. Abajo se define una función llamada load_photo_features() que carga el conjunto completo de descripciones de foto, y luego devuelve el subconjunto de interés para un conjunto dado de identificadores de foto. Esto no es muy eficiente; sin embargo, esto nos pondrá en marcha rápidamente.
# cargar características de la foto
def load_photo_features(filename, dataset):
# cargar todas las características
all_features = load(open(filename,'rb'))
# características del filtro
features = {k: all_features[k] for k in dataset}
return features
Podemos hacer una pausa aquí y probar todo lo que se ha desarrollado hasta ahora. El ejemplo de código completo se muestra a continuación.
from pickle import load
# cargar doc en la memoria
def load_doc(filename):
#abrir el archivo en modo sólo lectura
file = open(filename,'r')
# leer todo el texto
text = file.read()
# cerrar el archivo
file.close()
return text
# cargar una lista predefinida de identificadores de fotos
def load_set(filename):
doc = load_doc(filename)
dataset = list()
# proceso línea por línea
for line in doc.split('\n'):
# esquivar líneas vacías
if len(line) < 1:
continue
# obtener el identificador de la imagen
identifier = line.split('.')[0]
dataset.append(identifier)
return set(dataset)
# cargar descripciones limpias en la memoria
def load_clean_descriptions(filename, dataset):
# documento de carga
doc = load_doc(filename)
descriptions = dict()
for line in doc.split('\n'):
# línea divisoria por espacio en blanco
tokens = line.split()
# separar id de descripción
image_id, image_desc = tokens[0], tokens[1:]
# saltar imágenes que no están en el set
if image_id in dataset:
# crear lista
if image_id not in descriptions:
descriptions[image_id] = list()
# descripción de la envoltura en fichas
desc ='startseq'+''.join(image_desc) +'endseq'
# tienda
descriptions[image_id].append(desc)
return descriptions
# cargar características de la foto
def load_photo_features(filename, dataset):
# load all features
all_features = load(open(filename,'rb'))
# filtrar características
features = {k: all_features[k] for k in dataset}
return features
# conjunto de datos de entrenamiento de carga (6K)
filename ='Flickr8k_text/Flickr_8k.trainImages.txt'
train = load_set(filename)
print('Dataset: %d'% len(train))
# descripciones
train_descriptions = load_clean_descriptions('descriptions.txt', train)
print('Descriptions: train=%d'% len(train_descriptions))
# características de la imagen
train_features = load_photo_features('features.pkl', train)
print('Photos: train=%d'% len(train_features))
Al ejecutar este ejemplo, primero se cargan los 6.000 identificadores de fotos en el conjunto de datos de prueba. Estas funciones se utilizan para filtrar y cargar el texto de descripción limpio y las funciones de foto precalculadas. Ya casi terminamos.
Dataset: 6,000 Descriptions: train=6,000 Photos: train=6,000
El texto de la descripción deberá ser codificado en números antes de que pueda ser presentado al modelo como entrada o comparado con las predicciones del modelo. El primer paso para codificar los datos es crear un mapeo consistente de palabras a valores enteros únicos. Keras proporciona la clase Tokenizer que puede aprender este mapeo a partir de los datos de descripción cargados. Abajo se define la función to_lines() para convertir el diccionario de descripciones en una lista de cadenas y la función create_tokenizer() que se ajustará a un Tokenizer dado el texto de descripción de la foto cargada.
# convertir un diccionario de descripciones limpias en una lista de descripciones
def to_lines(descriptions):
all_desc = list()
for key in descriptions.keys():
[all_desc.append(d) for d in descriptions[key]]
return all_desc
# caben en un tokenizador con descripciones de subtítulos
def create_tokenizer(descriptions):
lines = to_lines(descriptions)
tokenizer = Tokenizer()
tokenizer.fit_on_texts(lines)
return tokenizer
# prepara el tokenizer
tokenizer = create_tokenizer(train_descriptions)
vocab_size = len(tokenizer.word_index) + 1
print('Vocabulary Size: %d'% vocab_size)
Ahora podemos codificar el texto. Cada descripción se dividirá en palabras. El modelo recibirá una palabra y la foto y generará la siguiente palabra. Entonces las dos primeras palabras de la descripción serán proporcionadas al modelo como entrada con la imagen para generar la siguiente palabra. Así es como el modelo será entrenado. Por ejemplo, la secuencia de entrada “little girl running in field” se dividiría en 6 pares entrada-salida para entrenar al modelo:
X1, X2 (text sequence), y (word) photo startseq, little photo startseq, little, girl photo startseq, little, girl, running photo startseq, little, girl, running, in photo startseq, little, girl, running, in, field photo startseq, little, girl, running, in, field, endseq
Más tarde, cuando el modelo se utiliza para generar descripciones, las palabras generadas se concatenan y se proporcionan recursivamente como entrada para generar un título para una imagen. La siguiente función llamada create_sequences() , dada la longitud máxima de la secuencia del tokenizer, y el diccionario de todas las descripciones y fotos, transformará los datos en pares de datos de entrada y salida para el entrenamiento del modelo. Hay dos matrices de entrada para el modelo: una para las características de la foto y otra para el texto codificado. Hay una salida para el modelo que es la siguiente palabra codificada en la secuencia de texto.
El texto de entrada se codifica como números enteros, que serán alimentados a una capa de incrustación de palabras. Las características de la foto serán alimentadas directamente a otra parte del modelo. El modelo producirá una predicción, que será una distribución de probabilidad sobre todas las palabras del vocabulario. Por lo tanto, los datos de salida serán una versión codificada en caliente de cada palabra, representando una distribución de probabilidad idealizada con valores 0 en todas las posiciones de la palabra, excepto en la posición real de la palabra, que tiene un valor de 1.
# crear secuencias de imágenes, secuencias de entrada y palabras de salida para una imagen
def create_sequences(tokenizer, max_length, descriptions, photos):
X1, X2, y = list(), list(), list()
# camina a través de cada identificador de imagen
for key, desc_list in descriptions.items():
# camina a través de cada descripción de la imagen
for desc in desc_list:
# codificar la secuencia
seq = tokenizer.texts_to_sequences([desc])[0]
# Dividir una secuencia en múltiples pares X,Y
for i in range(1, len(seq)):
# dividido en par de entrada y salida
in_seq, out_seq = seq[:i], seq[i]
# secuencia de entrada del pad
in_seq = pad_sequences([in_seq], maxlen=max_length)[0]
# codificar secuencia de salida
out_seq = to_categorical([out_seq], num_classes=vocab_size)[0]
# tienda
X1.append(photos[key][0])
X2.append(in_seq)
y.append(out_seq)
return array(X1), array(X2), array(y)
Necesitaremos calcular el número máximo de palabras en la descripción más larga. A continuación se define una breve función de ayuda denominada max_length().
# calcular la longitud de la descripción con el mayor número de palabras def max_length(descriptions): lines = to_lines(descriptions) return max(len(d.split()) for d in lines)
Ahora tenemos suficiente para cargar los datos para los conjuntos de datos de formación y desarrollo y transformar los datos cargados en pares de entrada y salida para ajustar un modelo de Deep Learning.
Definición del modelo
Definiremos un Deep Learning basado en el modelo de fusión descrito por Marc Tanti, en sus trabajos de 2017.
El modelo de fusión para el subtitulado de imágenes se introdujo en el Capítulo Modelos de redes neuronales para la generación de subtítulos
Describiremos el modelo en tres partes:
- Extractor de características de las fotos: Se trata de un modelo VGG de 16 capas preentrenado en el conjunto de datos de ImageNet. Hemos preprocesado las fotos con el modelo VGG (sin la capa de salida) y utilizaremos las características extraídas que predice este modelo como entrada.
- Procesador de secuencias:. Esta es una capa de incrustación de palabras para manejar la entrada de texto, seguida de una capa de red neuronal recurrente de Memoria a Corto Plazo Larga (LSTM).
- Decodificador (a falta de un nombre mejor): Tanto el extractor de características como el procesador de secuencias emiten un vector de longitud fija. Estos son fusionados y procesados por una capa densa para hacer una predicción final.
El modelo Photo Feature Extractor espera que las funciones de entrada de fotos sean un vector de 4.096 elementos. Estos son procesados por una capa densa para producir una representación de 256 elementos de la foto. El modelo de procesador de secuencia espera secuencias de entrada con una longitud predefinida (34 palabras) que se introducen en una capa de incrustación que utiliza una máscara para ignorar los valores acolchados. A esto le sigue una capa de LSTM con 256 unidades de memoria.
Ambos modelos de entrada producen un vector de 256 elementos. Además, ambos modelos de entrada utilizan la regularización en forma de un 50% de deserción escolar. Esto es para reducir el sobreequipamiento del conjunto de datos de entrenamiento, ya que esta configuración del modelo aprende muy rápido. El modelo Decoder fusiona los vectores de ambos modelos de entrada mediante una operación de adición. Esto es entonces alimentado a una capa de 256 neuronas densas y luego a una capa densa de salida final que hace una predicción softmax sobre todo el vocabulario de salida para la siguiente palabra en la secuencia. La siguiente función denominada define_model() define y devuelve el modelo listo para ser ajustado.
# define el modelo de subtitulado def define_model(vocab_size, max_length): # modelo de extractor de características inputs1 = Input(shape=(4096,)) fe1 = Dropout(0.5)(inputs1) fe2 = Dense(256, activation='relu')(fe1) # modelo de secuencia inputs2 = Input(shape=(max_length,)) se1 = Embedding(vocab_size, 256, mask_zero=True)(inputs2) se2 = Dropout(0.5)(se1) se3 = LSTM(256)(se2) # modelo del decodificador decoder1 = add([fe2, se3]) decoder2 = Dense(256, activation='relu')(decoder1) outputs = Dense(vocab_size, activation='softmax')(decoder2) # Átalos juntos[imagen, seq][palabra] model = Model(inputs=[inputs1, inputs2], outputs=outputs) # compilar modelo model.compile(loss='categorical_crossentropy', optimizer='adam') # resumir modelo model.summary() plot_model(model, to_file='model.png', show_shapes=True) return model
Se crea un gráfico del modelo que ayuda a comprender mejor la estructura de la red y las dos corrientes de entrada.
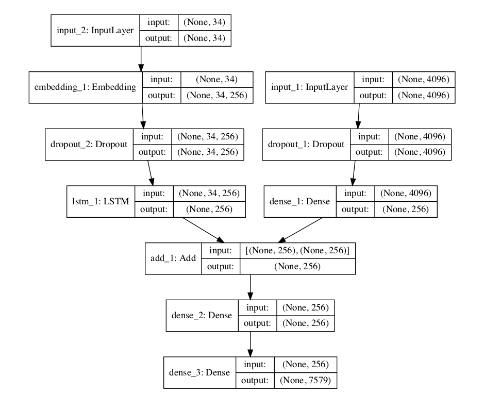
Ajuste del modelo
Ahora que sabemos cómo definir el modelo, podemos incluirlo en el conjunto de datos de formación. El modelo aprende rápido y se adapta rápidamente al conjunto de datos de formación. Por esta razón, monitorearemos la habilidad del modelo entrenado en el conjunto de datos de desarrollo de holdout. Cuando la habilidad del modelo en el conjunto de datos de desarrollo mejora al final de una época, guardaremos todo el modelo en un archivo.
Al final de la carrera, podemos usar el modelo guardado con la mejor habilidad en el conjunto de datos de entrenamiento como nuestro modelo final. Podemos hacer esto definiendo un ModelCheckpoint en Keras y especificándolo para monitorear la pérdida mínima en el conjunto de datos de validación y guardar el modelo en un archivo que tenga tanto la pérdida de entrenamiento como de validación en el nombre del archivo.
# define el punto de control callback
checkpoint = ModelCheckpoint('model.h5', monitor='val_loss', verbose=1,save_best_only=True, mode='min')
Luego podemos especificar el punto de control en la llamada a fit() mediante el argumento callbacks. También debemos especificar el conjunto de datos de desarrollo en fit() mediante el argumento de datos de validación. Sólo cabrán en el modelo 20 épocas, pero dada la cantidad de datos de entrenamiento, cada época puede durar 30 minutos en hardware moderno.
# modelo de ajuste model.fit([X1train, X2train], ytrain, epochs=20, verbose=2, callbacks=[checkpoint], validation_data=([X1test, X2test], ytest))
Ejemplo completo
El ejemplo completo para ajustar el modelo a los datos de entrenamiento se detalla a continuación. Ten en cuenta que para ejecutar este ejemplo puede ser necesario un equipo con 8 o más Gigabytes de RAM.
from numpy import array
from pickle import load
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
from keras.utils import to_categorical
from keras.utils import plot_model
from keras.models import Model
from keras.layers import Input
from keras.layers import Dense
from keras.layers import LSTM
from keras.layers import Embedding
from keras.layers import Dropout
from keras.layers.merge import add
from keras.callbacks import ModelCheckpoint
# cargar doc en la memoria
def load_doc(filename):
# abrir en modo solo lectura
file = open(filename,'r')
# leer todo el texto
text = file.read()
# cerrar el archivo
file.close()
return text
# cargar descripciones limpias en la memoria
def load_clean_descriptions(filename, dataset):
# documento de carga
doc = load_doc(filename)
descriptions = dict()
for line in doc.split('\n'):
# línea divisoria por espacio en blanco
tokens = line.split()
# separar id de descripción
image_id, image_desc = tokens[0], tokens[1:]
# saltar imágenes que no están en el set
if image_id in dataset:
# crear lista
if image_id not in descriptions:
descriptions[image_id] = list()
# descripción de la envoltura en fichas
desc ='startseq'+''.join(image_desc) +'endseq'
# tienda
descriptions[image_id].append(desc)
return descriptions
# convertir un diccionario de descripciones limpias en una lista de descripciones
def to_lines(descriptions):
all_desc = list()
for key in descriptions.keys():
[all_desc.append(d) for d in descriptions[key]]
return all_desc
# caben en un tokenizador con descripciones de subtítulos
def create_tokenizer(descriptions):
lines = to_lines(descriptions)
tokenizer = Tokenizer()
tokenizer.fit_on_texts(lines)
return tokenizer
# prepara el tokenizer
tokenizer = create_tokenizer(train_descriptions)
vocab_size = len(tokenizer.word_index) + 1
print('Vocabulary Size: %d'% vocab_size)
# crear secuencias de imágenes, secuencias de entrada y palabras de salida para una imagen
def create_sequences(tokenizer, max_length, descriptions, photos):
X1, X2, y = list(), list(), list()
# camina a través de cada identificador de imagen
for key, desc_list in descriptions.items():
# camina a través de cada descripción de la imagen
for desc in desc_list:
# codificar la secuencia
seq = tokenizer.texts_to_sequences([desc])[0]
# Dividir una secuencia en múltiples pares X,Y
for i in range(1, len(seq)):
# dividido en par de entrada y salida
in_seq, out_seq = seq[:i], seq[i]
# secuencia de entrada del pad
in_seq = pad_sequences([in_seq], maxlen=max_length)[0]
# codificar secuencia de salida
out_seq = to_categorical([out_seq], num_classes=vocab_size)[0]
# tienda
X1.append(photos[key][0])
X2.append(in_seq)
y.append(out_seq)
return array(X1), array(X2), array(y)
# define el modelo de subtitulado
def define_model(vocab_size, max_length):
# modelo de extractor de características
inputs1 = Input(shape=(4096,))
fe1 = Dropout(0.5)(inputs1)
fe2 = Dense(256, activation='relu')(fe1)
# modelo de secuencia
inputs2 = Input(shape=(max_length,))
se1 = Embedding(vocab_size, 256, mask_zero=True)(inputs2)
se2 = Dropout(0.5)(se1)
se3 = LSTM(256)(se2)
# modelo del decodificador
decoder1 = add([fe2, se3])
decoder2 = Dense(256, activation='relu')(decoder1)
outputs = Dense(vocab_size, activation='softmax')(decoder2)
# Átalos juntos[imagen, seq][palabra]
model = Model(inputs=[inputs1, inputs2], outputs=outputs)
# compilar modelo
model.compile(loss='categorical_crossentropy', optimizer='adam')
# resumir modelo
model.summary()
plot_model(model, to_file='model.png', show_shapes=True)
return model
# conjunto de datos de entrenamiento de carga (6K)
filename ='Flickr8k_text/Flickr_8k.trainImages.txt'train = load_set(filename)
print('Dataset: %d'% len(train))
# descripciones
train_descriptions = load_clean_descriptions('descriptions.txt', train)
print('Descriptions: train=%d'% len(train_descriptions))
# características fotográficas
train_features = load_photo_features('features.pkl', train)
print('Photos: train=%d'% len(train_features))
# preparar el tokenizer
tokenizer = create_tokenizer(train_descriptions)
vocab_size = len(tokenizer.word_index) + 1
print('Vocabulary Size: %d'% vocab_size)
# determinar la longitud máxima de la secuencia
max_length = max_length(train_descriptions)
print('Description Length: %d'% max_length)
# preparar secuencias
X1train, X2train, ytrain = create_sequences(tokenizer, max_length, train_descriptions,
train_features)
# equipo de prueba de carga
filename ='Flickr8k_text/Flickr_8k.devImages.txt'
test = load_set(filename)
print('Dataset: %d'% len(test))
# descripciones
test_descriptions = load_clean_descriptions('descriptions.txt', test)
print('Descriptions: test=%d'% len(test_descriptions))
# características de las imágenes
test_features = load_photo_features('features.pkl', test)
print('Photos: test=%d'% len(test_features))
# preparar secuencias
X1test, X2test, ytest = create_sequences(tokenizer, max_length, test_descriptions,
test_features)
# definir el modelo
model = define_model(vocab_size, max_length)
# definir la llamada de retorno al puesto de control
checkpoint = ModelCheckpoint('model.h5', monitor='val_loss', verbose=1,save_best_only=True, mode='min')
# el modelo mas adecuado
model.fit([X1train, X2train], ytrain, epochs=20, verbose=2, callbacks=[checkpoint], validation_data=([X1test, X2test], ytest))
Al ejecutar el ejemplo, se imprime primero un resumen de los conjuntos de datos de formación y desarrollo cargados.
Dataset: 6,000 Descriptions: train=6,000 Photos: train=6,000 Vocabulary Size: 7,579 Description Length: 34 Dataset: 1,000 Descriptions: test=1,000 Photos: test=1,000 Train on 306,404 samples, validate on 50,903 samples
Después del resumen del modelo, podemos hacernos una idea del número total de pares input-output de formación y validación (desarrollo). El modelo entonces se ejecuta, guardando el mejor modelo en archivos.h5 a lo largo del camino. Ten en cuenta que incluso en una CPU moderna, cada época puede durar 20 minutos. Puede que desees considerar la posibilidad de ejecutar el ejemplo en una GPU, como en AWS. Cuando ejecuté el ejemplo, el mejor modelo se guardó al final de la época 2 con una pérdida de 3.245 en el conjunto de datos de entrenamiento y una pérdida de 3.612 en el conjunto de datos de desarrollo.
Evaluar modelo
Una vez que el modelo se ajuste, podemos evaluar la habilidad de sus predicciones en el conjunto de datos de la prueba de retención. Evaluaremos un modelo generando descripciones para todas las fotos en el conjunto de datos de la prueba y evaluando esas predicciones con una función de costo estándar. Primero, necesitamos ser capaces de generar una descripción para una foto usando un modelo entrenado.
Esto implica pasar en el token de descripción de inicio startseq, generar una palabra, luego llamar al modelo recursivamente con palabras generadas como entrada hasta que el token de fin de secuencia sea alcanzado endseq o la longitud máxima de la descripción sea alcanzada. La siguiente función llamada generate_desc() implementa este comportamiento y genera una descripción textual con un modelo entrenado y una foto preparada como entrada. Llama a la función word_for_id() para mapear una predicción entera de vuelta a una palabra.
# asignar un número entero a una palabra def word_for_id(integer, tokenizer): for word, index in tokenizer.word_index.items(): if index == integer: return word return None # generar una descripción para una imagen def generate_desc(model, tokenizer, photo, max_length): # sembrar el proceso de generación in_text ='startseq' # iterar a lo largo de toda la secuencia for i in range(max_length): # secuencia de entrada de codificación de números enteros sequence = tokenizer.texts_to_sequences([in_text])[0] # entrada del panel sequence = pad_sequences([sequence], maxlen=max_length) # predecir la siguiente palabra yhat = model.predict([photo,sequence], verbose=0) # convertir la probabilidad en un número entero yhat = argmax(yhat) # asignar un número entero a una palabra word = word_for_id(yhat, tokenizer) # detenerse si no podemos mapear la palabra if word is None: break # append como entrada para generar la siguiente palabra in_text +=''+ word # se detiene si predecimos el final de la secuencia if word =='endseq': break return in_text
Al generar y comparar descripciones de fotos, tendremos que quitar el comienzo y el final de las palabras de la secuencia. La siguiente función llamada cleanup_summary() realizará esta operación.
# eliminar tokens de inicio/fin de secuencia de un resumen
def cleanup_summary(summary):
# remover el inicio de la secuencia del token
index = summary.find('startseq')
if index > -1:
summary = summary[len('startseq'):]
# remover el token de fin de secuencia
index = summary.find('endseq')
if index > -1:
summary = summary[:index]
return summary
Generaremos predicciones para todas las fotos del conjunto de datos de prueba. La función de abajo llamada evaluate_model() evaluará un modelo entrenado contra un conjunto de datos dado de descripciones de fotos y características de las fotos. Las descripciones reales y previstas se recopilan y evalúan colectivamente utilizando la puntuación BLEU del corpus que resume lo cerca que está el texto generado del texto esperado.
# evaluar la habilidad del modelo
def evaluate_model(model, descriptions, photos, tokenizer, max_length):
actual, predicted = list(), list()
# pasar por encima de todo el conjunto
for key, desc_list in descriptions.items():
# Generar descripción
yhat = generate_desc(model, tokenizer, photos[key], max_length)
# predicción de limpieza
yhat = cleanup_summary(yhat)
# almacenar los datos reales y los pronosticados
references = [cleanup_summary(d).split() for d in desc_list]
actual.append(references)
predicted.append(yhat.split())
# calcular la puntuación BLEU
print('BLEU-1: %f'% corpus_bleu(actual, predicted, weights=(1.0, 0, 0, 0)))
print('BLEU-2: %f'% corpus_bleu(actual, predicted, weights=(0.5, 0.5, 0, 0)))
print('BLEU-3: %f'% corpus_bleu(actual, predicted, weights=(0.3, 0.3, 0.3, 0)))
print('BLEU-4: %f'% corpus_bleu(actual, predicted, weights=(0.25, 0.25, 0.25, 0.25)))
Las puntuaciones BLEU se utilizan en la traducción de textos para evaluar el texto traducido frente a una o más traducciones de referencia. Aquí, comparamos cada descripción generada con todas las descripciones de referencia para la fotografía.
Luego calculamos las puntuaciones BLEU para 1, 2, 3 y 4 n-grams acumulativos. La biblioteca NLTK Python implementa el cálculo de la puntuación BLEU en la función corpus_bleu(). Un puntaje más alto cerca de 1.0 es mejor, un puntaje más cercano a cero es peor. Ten en cuenta que la puntuación BLEU y la API NLTK se introdujeron en el Capítulo Cómo evaluar el texto generado con la puntuación BLEU.
Podemos poner todo esto junto con las funciones de la sección anterior para cargar los datos. Primero necesitamos cargar el conjunto de datos de entrenamiento para preparar un Tokenizer que nos permita codificar las palabras generadas como secuencias de entrada para el modelo. Es crítico que codifiquemos las palabras generadas usando exactamente el mismo esquema de codificación que se usó cuando se entrenó el modelo. A continuación, utilizamos estas funciones para cargar el conjunto de datos de prueba. El ejemplo completo se enumera a continuación
from numpy import argmax
from pickle import load
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
from keras.models import load_model
from nltk.translate.bleu_score import corpus_bleu
# cargar doc en la memoria
def load_doc(filename):
# abrir archivo en modo solo lectura
file = open(filename,'r')
# leer todo el texto
text = file.read()
# cerrar el archivo
file.close()
return text
# cargar una lista predefinida de identificadores de fotos
def load_set(filename):
doc = load_doc(filename)
dataset = list()
# proceso línea por línea
for line in doc.split('\n'):
# saltar líneas vacías
if len(line) < 1: continue # obtener el identificador de la imagen identifier = line.split('.')[0] dataset.append(identifier) return set(dataset) # cargar descripciones limpias en la memoria def load_clean_descriptions(filename, dataset): # cargar documento doc = load_doc(filename) descriptions = dict() for line in doc.split('\n'): # línea divisoria por espacio en blanco tokens = line.split() # separar id de descripción image_id, image_desc = tokens[0], tokens[1:] # saltar imágenes que no están en el set if image_id in dataset: # crear lista if image_id not in descriptions: descriptions[image_id] = list() # descripción de la envoltura en fichas desc ='startseq'+''.join(image_desc) +'endseq' # tienda descriptions[image_id].append(desc) return descriptions # convertir un diccionario de descripciones limpias en una lista de descripciones def to_lines(descriptions): all_desc = list() for key in descriptions.keys(): [all_desc.append(d) for d in descriptions[key]] return all_desc # caben en un tokenizador con descripciones de subtítulos def create_tokenizer(descriptions): lines = to_lines(descriptions) tokenizer = Tokenizer() tokenizer.fit_on_texts(lines) return tokenizer # prepara el tokenizer tokenizer = create_tokenizer(train_descriptions) vocab_size = len(tokenizer.word_index) + 1 print('Vocabulary Size: %d'% vocab_size) # calcular la longitud de la descripción con el mayor número de palabras def max_length(descriptions): lines = to_lines(descriptions) return max(len(d.split()) for d in lines) # asignar un número entero a una palabra def word_for_id(integer, tokenizer): for word, index in tokenizer.word_index.items(): if index == integer: return word return None # generar una descripción para una imagen def generate_desc(model, tokenizer, photo, max_length): # sembrar el proceso de generación in_text ='startseq' # iterar a lo largo de toda la secuencia for _ in range(max_length): # secuencia de entrada de codificación de números enteros sequence = tokenizer.texts_to_sequences([in_text])[0] # entrada del panel sequence = pad_sequences([sequence], maxlen=max_length) # predecir la siguiente palabra yhat = model.predict([photo,sequence], verbose=0) # convertir la probabilidad en un número entero yhat = argmax(yhat) # asignar un número entero a una palabra word = word_for_id(yhat, tokenizer) # detenerse si no podemos mapear la palabra if word is None: break # append como entrada para generar la siguiente palabra in_text +=''+ word # se detiene si predecimos el final de la secuencia if word =='endseq': break return in_text # eliminar tokens de inicio/fin de secuencia de un resumen def cleanup_summary(summary): # eliminar el token de inicio de secuencia index = summary.find('startseq') if index > -1:
summary = summary[len('startseq'):]
# eliminar el token de fin de secuencia
index = summary.find('endseq')
if index > -1:
summary = summary[:index]
return summary
# evaluar la habilidad del modelo
def evaluate_model(model, descriptions, photos, tokenizer, max_length):
actual, predicted = list(), list()
# pasar por encima de todo el conjunto
for key, desc_list in descriptions.items():
# Generar descripción
yhat = generate_desc(model, tokenizer, photos[key], max_length)
# predicción de limpieza
yhat = cleanup_summary(yhat)
# almacenar los datos reales y los pronosticados
references = [cleanup_summary(d).split() for d in desc_list]
actual.append(references)
predicted.append(yhat.split())
# calcular la puntuación BLEU
print('BLEU-1: %f'% corpus_bleu(actual, predicted, weights=(1.0, 0, 0, 0)))
print('BLEU-2: %f'% corpus_bleu(actual, predicted, weights=(0.5, 0.5, 0, 0)))
print('BLEU-3: %f'% corpus_bleu(actual, predicted, weights=(0.3, 0.3, 0.3, 0)))
print('BLEU-4: %f'% corpus_bleu(actual, predicted, weights=(0.25, 0.25, 0.25, 0.25)))
# conjunto de datos de entrenamiento de carga (6K)
filename ='Flickr8k_text/Flickr_8k.trainImages.txt'train = load_set(filename)
print('Dataset: %d'% len(train))
# descripciones
train_descriptions = load_clean_descriptions('descriptions.txt', train)
print('Descriptions: train=%d'% len(train_descriptions))
# características fotográficas
train_features = load_photo_features('features.pkl', train)
print('Photos: train=%d'% len(train_features))
# preparar el tokenizer
tokenizer = create_tokenizer(train_descriptions)
vocab_size = len(tokenizer.word_index) + 1
print('Vocabulary Size: %d'% vocab_size)
# determinar la longitud máxima de la secuencia
max_length = max_length(train_descriptions)
print('Description Length: %d'% max_length)
# equipo de prueba de carga
filename ='Flickr8k_text/Flickr_8k.testImages.txt'
test = load_set(filename)
print('Dataset: %d'% len(test))
# descripciones
test_descriptions = load_clean_descriptions('descriptions.txt', test)
print('Descriptions: test=%d'% len(test_descriptions))
# características fotográficas
test_features = load_photo_features('features.pkl', test)
print('Photos: test=%d'% len(test_features))
# cargar el modelo
filename ='model.h5'
model = load_model(filename)
# evaluar el modelo
evaluate_model(model, test_descriptions, test_features, tokenizer, max_length)
Al ejecutar el ejemplo se imprimen las puntuaciones BLEU. Podemos ver que las puntuaciones encajan dentro del rango esperado de un modelo hábil sobre el problema. La configuración del modelo elegido no está en absoluto optimizada.
BLEU-1: 0.438805 BLEU-2: 0.230646 BLEU-3: 0.150245 BLEU-4: 0.062847
Generar nuevos subtítulos
Ahora que sabemos cómo desarrollar y evaluar un modelo de generación de subtítulos, ¿Cómo podemos usarlo? Casi todo lo que necesitamos para generar subtítulos para fotografías completamente nuevas está en el archivo de modelo. También necesitamos el Tokenizer para codificar las palabras generadas para el modelo mientras se genera una secuencia, y la longitud máxima de las secuencias de entrada, utilizadas cuando definimos el modelo (por ejemplo, 34).
Podemos codificar la longitud máxima de la secuencia. Con la codificación de texto, podemos crear el tokenizer y guardarlo en un archivo para poder cargarlo rápidamente cuando lo necesitemos sin necesidad de todo el conjunto de datos de Flickr8K. Una alternativa sería usar nuestro propio archivo de vocabulario y mapeo para que los números enteros funcionen durante el entrenamiento. Podemos crear el Tokenizer como antes y guardarlo como un archivo tokenizer.pkl. El ejemplo completo se enumera a continuación.
from keras.preprocessing.text import Tokenizer
from pickle import dump
# cargar doc en la memoria
def load_doc(filename):
# abrir archivo en modo solo lectura
file = open(filename,'r')
# leer todo el texto
text = file.read()
# cerrar el archivo
file.close()
return text
# cargar una lista predefinida de identificadores de fotos
def load_set(filename):
doc = load_doc(filename)
dataset = list()
# proceso línea por línea
for line in doc.split('\n'):
# esquivar líneas vacías
if len(line) < 1:
continue
# obtener el identificador de la imagen
identifier = line.split('.')[0]
dataset.append(identifier)
return set(dataset)
# cargar descripciones limpias en la memoria
def load_clean_descriptions(filename, dataset):
# cargar documento
doc = load_doc(filename)
descriptions = dict()
for line in doc.split('\n'):
# línea divisoria por espacio en blanco
tokens = line.split()
# separar id de descripción
image_id, image_desc = tokens[0], tokens[1:]
# saltar imágenes que no están en el set
if image_id in dataset:
# crear lista
if image_id not in descriptions:
descriptions[image_id] = list()
# descripción de la envoltura en tokens
desc ='startseq'+''.join(image_desc) +'endseq'
# tienda
descriptions[image_id].append(desc)
return descriptions
# un diccionario encubierto de descripciones limpias a una lista de descripciones
def to_lines(descriptions):
all_desc = list()
for key in descriptions.keys():
[all_desc.append(d) for d in descriptions[key]]
return all_desc
# ajustar las descripciones de los subtítulos de un tokenizador
def create_tokenizer(descriptions):
lines = to_lines(descriptions)
tokenizer = Tokenizer()
tokenizer.fit_on_texts(lines)
return tokenizer
# conjunto de datos de entrenamiento de carga
filename ='Flickr8k_text/Flickr_8k.trainImages.txt'
train = load_set(filename)
print('Dataset: %d'% len(train))
# descripciones
train_descriptions = load_clean_descriptions('descriptions.txt', train)
print('Descriptions: train=%d'% len(train_descriptions))
# preparar tokenizer
tokenizer = create_tokenizer(train_descriptions)
# guardar el tokenizer
dump(tokenizer, open('tokenizer.pkl','wb'))
Ahora podemos cargar el tokenizer siempre que lo necesitemos sin tener que cargar todo el conjunto de datos de formación de anotaciones. Ahora, vamos a generar una descripción para una nueva fotografía. Abajo hay una nueva fotografía que elegí al azar en Flickr (disponible bajo una licencia permisiva).

Vamos a generar una descripción de la misma utilizando nuestro modelo. Descarga la fotografía y guárdala en tu directorio local con el nombre de archivo example.jpg. Primero, debemos cargar el Tokenizer desde tokenizer.pkl y definir la longitud máxima de la secuencia a generar, necesaria para rellenar las entradas.
# cargar el tokenizer
tokenizer = load(open('tokenizer.pkl','rb'))
# predefinir la longitud máxima de la secuencia (de la formación)
max_length = 34
Entonces debemos cargar el modelo, como antes.
# cargar el modelo
model = load_model('model.h5')
A continuación, debemos cargar la foto que deseamos describir y extraer las características. Podríamos hacer esto redefiniendo el modelo y añadiéndole el modelo VGG-16, o podemos usar el modelo VGG para predecir las características y utilizarlas como entradas a nuestro modelo existente. Haremos esto último y utilizaremos una versión modificada de la función extract_features() utilizada durante la preparación de los datos, pero adaptada para trabajar en una sola foto.
# extraer características de cada foto del directorio
def extract_features(filename):
# cargar el modelo
model = VGG16()
# reestructurar el modelo
model.layers.pop()
model = Model(inputs=model.inputs, outputs=model.layers[-1].output)
# cargar la foto
image = load_img(filename, target_size=(224, 224))
# convertir los píxeles de la imagen en una matriz NumPy
image = img_to_array(image)
# remodelar los datos para el modelo
image = image.reshape((1, image.shape[0], image.shape[1], image.shape[2]))
# preparar la imagen para el modelo VGG
image = preprocess_input(image)
# obtenga características
feature = model.predict(image, verbose=0)
return feature
# cargar y preparar la fotografía
photo = extract_features('example.jpg')
Luego podemos generar una descripción usando la función generate_desc() definida al evaluar el modelo. El ejemplo completo para generar una descripción para una fotografía independiente completamente nueva se muestra a continuación
from pickle import load
from numpy import argmax
from keras.preprocessing.sequence import pad_sequences
from keras.applications.vgg16 import VGG16
from keras.preprocessing.image import load_img
from keras.preprocessing.image import img_to_array
from keras.applications.vgg16 import preprocess_input
from keras.models import Model
from keras.models import load_model
# extraer características de cada foto del directorio
def extract_features(filename):
# cargar modelo
model = VGG16()
# re-estructurar el modelo
model.layers.pop()
model = Model(inputs=model.inputs, outputs=model.layers[-1].output)
# cargar la foto
image = load_img(filename, target_size=(224, 224))
# convert the image pixels to a numpy array
image = img_to_array(image)
# remodelar los datos para el modelo
image = image.reshape((1, image.shape[0], image.shape[1], image.shape[2]))
# preparar la imagen para el modelo VGG
image = preprocess_input(image)
# obtenga características
feature = model.predict(image, verbose=0)
return feature
# asignar un número entero a una palabra
def word_for_id(integer, tokenizer):
for word, index in tokenizer.word_index.items():
if index == integer:
return word
return None
# eliminar tokens de inicio/fin de secuencia de un resumen
def cleanup_summary(summary):
# eliminar el token de inicio de secuencia
index = summary.find('startseq')
if index > -1:
summary = summary[len('startseq'):]
# eliminar el token de fin de secuencia
index = summary.find('endseq')
if index > -1:
summary = summary[:index]
return summary
# generar una descripción para una imagen
def generate_desc(model, tokenizer, photo, max_length):
# sembrar el proceso de generación
in_text ='startseq'
# iterar a lo largo de toda la secuencia
for _ in range(max_length):
# secuencia de entrada de codificación de números enteros
sequence = tokenizer.texts_to_sequences([in_text])[0]
# entrada del panel
sequence = pad_sequences([sequence], maxlen=max_length)
# predecir la siguiente palabra
yhat = model.predict([photo,sequence], verbose=0)
# convertir la probabilidad en un número entero
yhat = argmax(yhat)
# asignar un número entero a una palabra
word = word_for_id(yhat, tokenizer)
# detenerse si no podemos mapear la palabra
if word is None:
break
# append como entrada para generar la siguiente palabra
in_text +=''+ word
# se detiene si predecimos el final de la secuencia
if word =='endseq':
break
return in_text
# cargar el tokenizer
tokenizer = load(open('tokenizer.pkl','rb'))
# predefinir la longitud máxima de la secuencia (de la formación)
max_length = 34
# cargar el modelo
model = load_model('model.h5')
# cargar y preparar la fotografía
photo = extract_features('example.jpg')
# generar descripción
description = generate_desc(model, tokenizer, photo, max_length)
description = cleanup_summary(description)
print(description)
En este caso, la descripción generada fue la siguiente:
dog is running across the beach
Extensiones
En esta sección se enumeran algunas ideas para ampliar el tutorial que tal vez desee explorar.
- Modelos alternativos de imágenes preentrenadas: Para la extracción de características se utilizó un pequeño modelo VGG de 16 capas. Considere la posibilidad de explorar modelos más grandes que ofrezcan un mejor rendimiento en el conjunto de datos de ImageNet, como Inception.
- Vocabulario más pequeño: Un vocabulario más amplio de casi ocho mil palabras fue utilizado en el desarrollo del modelo. Muchas de las palabras soportadas pueden ser errores ortográficos o sólo se utilizan una vez en todo el conjunto de datos. Refine el vocabulario y reduzca el tamaño, quizás a la mitad.
- Vectores de palabras pre-entrenados: El modelo aprendió la palabra vectores como parte del ajuste del modelo. Se puede lograr un mejor rendimiento mediante el uso de vectores de palabras ya sea preentrenados en el conjunto de datos de formación o entrenados en un corpus de texto mucho más amplio, como artículos de noticias o Wikipedia.
- Entrenar vectores de Word2Vec: Preentrene vectores de palabras usando Word2Vec en los datos de descripción y explore modelos que permiten y no permiten la sintonía fina de los vectores durante el entrenamiento, luego compare las habilidades.
- Modelo Tune: La configuración del modelo no se ajustaba al problema. Explore configuraciones alternativas y vea si puede lograr un mejor rendimiento.
- Inyectar Arquitectura: Explora la arquitectura de inyección para la generación de subtítulos y compare el rendimiento con la arquitectura de fusión utilizada en este tutorial.
- Enmarques Alternos: Explora marcos alternativos de los problemas, como la generación de la secuencia completa a partir de la foto sola.
- Modelo de lenguaje previo al entrenamiento: Capacitar previamente un modelo de lenguaje para generar texto de descripción, luego usarlo en el modelo de generación de subtítulos y evaluar el impacto en el tiempo y la habilidad del modelo de capacitación.
- Descripciones truncadas: Sólo entrena el modelo en la descripción en o por debajo de un número específico de palabras y explorar truncar largas descripciones a una longitud preferida. Evaluar el impacto en el tiempo de capacitación y modelar la habilidad.
- Medida alternativa: Explora medidas de rendimiento alternativas junto a BLEU como ROGUE. Compare las puntuaciones de las mismas descripciones para desarrollar una intuición de cómo difieren las medidas en la práctica.
Si exploras alguna de estas extensiones, me encantaría saberlo.
➡ Aprende mucho mas en nuestro curso: