
Blog
Proyecto: Desarrollar un Modelo CNN de n-gramas para el Análisis de Sentimientos
Un modelo de Deep Learning estándar para la clasificación de textos y el análisis de sentimientos utiliza una capa de incrustación de palabras y una red neuronal convolucional unidimensional. El modelo puede ampliarse utilizando múltiples redes neuronales convolucionales paralelas que leen el documento fuente utilizando diferentes tamaños de núcleo. Esto, en efecto, crea una red neural convolucional multicanal, para texto que lee texto con diferentes tamaños de n-gram (grupos de palabras). En esta parte del curso, descubrirás cómo desarrollar una red neuronal convolucional multicanal para la predicción de sentimientos en los datos de revisión de películas de texto. Después de completar este tutorial, tú sabrás:
- Cómo preparar los datos de texto de la revisión de la película para el modelado.
- Cómo desarrollar una red neural convolucional multicanal para texto en Keras.
- Cómo evaluar un modelo de ajuste en datos de revisión de película no vistos.
Vamos a empezar con la lección de hoy.
Resumen del tutorial
Este tutorial está dividido en las siguientes partes:
- Conjunto de datos de revisión de películas.
- Preparación de datos.
- Desarrollo del Modelo Multicanal.
- Evaluación del modelo.
Conjunto de datos de revisión de películas.
En este tutorial, utilizaremos el conjunto de datos de Revisión de películas. Este conjunto de datos diseñado para el análisis de sentimientos se describió anteriormente en la lección Cómo preparar los datos de la revisión de la película para el análisis de los sentimientos de este curso. Puede descargar el conjunto de datos desde aquí:
Conjunto de datos de Polaridad de Revisión de Película (review_polarity.tar.gz, 3MB).
http://www.cs.cornell.edu/people/pabo/movie-review-data/review_polarity.tar.gz
Después de descomprimir el archivo, tendrá un directorio llamado txt_sentoken con dos subdirectorios que contienen el texto neg y pos para comentarios negativos y positivos. Las revisiones se almacenan una por archivo con una convención de nomenclatura cv000 a cv999 para cada uno de los formatos neg y pos.
Preparación de datos
La preparación del conjunto de datos de reseñas de películas se describió por primera vez en la lección Cómo preparar los datos de la revisión de la película para el análisis de los sentimientos de este curso.
En esta sección, veremos tres cosas:
- Separación de datos en equipos de entrenamiento y de prueba.
- Cargar y limpiar los datos para eliminar la puntuación y los números.
- Limpia todas las revisiones y ahorra.
Dividir en entrenamientos y conjuntos de pruebas
Estamos fingiendo que estamos desarrollando un sistema que puede predecir el sentimiento de una crítica cinematográfica textual como positivo o negativo. Esto significa que después de que el modelo sea desarrollado, necesitaremos hacer predicciones sobre nuevas revisiones textuales. Esto requerirá que se realice toda la preparación de datos en esas nuevas revisiones que en los datos de capacitación para el modelo. Nos aseguraremos de que esta restricción se incorpore en la evaluación de nuestros modelos dividiendo los conjuntos de datos de formación y de prueba antes de cualquier preparación de datos. Esto significa que cualquier conocimiento en los datos del conjunto de pruebas que pueda ayudarnos a preparar mejor los datos (por ejemplo, las palabras utilizadas) no está disponible en la preparación de los datos utilizados para la formación del modelo.
Dicho esto, utilizaremos las últimas 100 revisiones positivas y las últimas 100 negativas como conjunto de pruebas (100 revisiones) y las restantes 1.800 revisiones como conjunto de datos de formación. Este es un entrenamiento del 90%, con una división del 10% de los datos. La división puede imponerse fácilmente utilizando los nombres de archivo de las revisiones, donde las revisiones nombradas de 000 a 899 son para datos de formación y las nombradas de 900 en adelante son para pruebas.
Comentarios sobre la carga y la limpieza
Los datos del texto ya están bastante limpios; no se requiere mucha preparación. Sin enfocarnos demasiado en los detalles, prepararemos los datos de la siguiente manera:
- Dividiremos los tokens en espacios en blanco.
- Eliminaremos todos los signos de puntuación de las palabras.
- Eliminaremos todas las palabras que no estén compuestas únicamente de caracteres alfabéticos.
- Eliminaremos todas las palabras que son palabras de parada conocidas.
- Eliminaremos todas las palabras que tengan una longitud menor o igual a un (1) carácter.
Podemos poner todos estos pasos en una función llamada clean_doc() que toma como argumento el texto crudo cargado desde un archivo y devuelve una lista de tokens limpios. También podemos definir una función load_doc() que carga un documento desde un archivo listo para su uso con la función clean_doc(). Un ejemplo de la limpieza de la primera revisión positiva se enumeran a continuación.
from nltk.corpus import stopwords
import string
import re
# cargar doc en la memoria
def load_doc(filename):
# abrir archivo en modo solo lectura
file = open(filename, 'r')
# leer todo el texto
text = file.read()
# cerrar el archivo
file.close()
return text
# Convierte a Doc en tokens limpios
def clean_doc(doc):
# dividido en tokens por el espacio en blanco
tokens = doc.split()
# prepare a regex para el filtrado de caracteres
re_punc = re.compile('[%s]' % re.escape(string.punctuation))
# Elimina la puntuación de cada palabra
tokens = [re_punc.sub('', w) for w in tokens]
# eliminar los tokens restantes que no estén en orden alfabético
tokens = [word for word in tokens if word.isalpha()]
# filtra las palabras de parada
stop_words = set(stopwords.words('english'))
tokens = [w for w in tokens if not w in stop_words]
# filtrar las tokens cortas
tokens = [word for word in tokens if len(word) > 1]
return tokens
# cargar el documento
filename = 'txt_sentoken/pos/cv000_29590.txt'
text = load_doc(filename)
tokens = clean_doc(text)
print(tokens)
Al ejecutar el ejemplo se imprime una larga lista de tokens limpios. Hay muchos más pasos de limpieza que tal vez queramos explorar y los dejo como ejercicios adicionales
... 'creepy', 'place', 'even', 'acting', 'hell', 'solid', 'dreamy', 'depp', 'turning', 'typically', 'strong', 'performance', 'deftly', 'handling', 'british', 'accent', 'ians', 'holm', 'joe', 'goulds', 'secret', 'richardson', 'dalmatians', 'log', 'great', 'supporting', 'roles', 'big', 'surprise', 'graham', 'cringed', 'first', 'time', 'opened', 'mouth', 'imagining', 'attempt', 'irish', 'accent', 'actually', 'wasnt', 'half', 'bad', 'film', 'however', 'good', 'strong', 'violencegore', 'sexuality', 'language', 'drug', 'content']
Limpie todas las revisiones y guarde
Ahora podemos usar la función para limpiar revisiones y aplicarla a todas las revisiones. Para ello, desarrollaremos una nueva función llamada process_docs() que recorrerá todas las revisiones de un directorio, las limpiará y las devolverá en forma de lista. También añadiremos un argumento a la función para indicar si la función es procesar revisiones de entrenamiento o de prueba, de esta forma se pueden filtrar los nombres de archivo (como se ha descrito anteriormente) y sólo se limpiarán y devolverán las revisiones de tren o de prueba solicitadas. La función completa se enumera a continuación.
# cargar todos los documentos en un directorio
def process_docs(directory, is_train):
documents = list()
# recorrer todos los archivos de la carpeta
for filename in listdir(directory):
# salta cualquier reseña en el set de prueba
if is_train and filename.startswith('cv9'):
continue
if not is_train and not filename.startswith('cv9'):
continue
# crear la ruta completa del archivo a abrir
path = directory + '/' + filename
# cargue el doc
doc = load_doc(path)
# limpie doc
tokens = clean_doc(doc)
# añadir a la lista
documents.append(tokens)
return documents
Podemos llamar a esta función con revisiones de entrenamiento negativas. También necesitamos etiquetas para el entrenamiento y documentos de prueba. Sabemos que tenemos 900 documentos de formación y 100 documentos de prueba. Podemos utilizar una lista de comprensión de Python para crear las etiquetas para las revisiones negativas (0) y positivas (1) tanto para el entrenamiento como para los equipos de prueba. La función abajo nombrada load_clean_dataset() cargará y limpiará el texto de la revisión de la película y también creará las etiquetas para las revisiones.
# cargar y limpiar un conjunto de datos
def load_clean_dataset(is_train):
# cargar documentos
neg = process_docs('txt_sentoken/neg', is_train)
pos = process_docs('txt_sentoken/pos', is_train)
docs = neg + pos
# preparar etiquetas
labels = [0 for _ in range(len(neg))] + [1 for _ in range(len(pos))]
return docs, labels
Por último, queremos guardar el entrenamiento preparado y los juegos de prueba en un archivo para poder cargarlos más tarde para el modelado y la evaluación del modelo. La siguiente función save_dataset() guardará un determinado conjunto de datos preparado (elementos X e Y) en un archivo utilizando la API de Pickle (esta es la API estándar para guardar objetos en Python).
# guardar un conjunto de datos en un archivo
def save_dataset(dataset, filename):
dump(dataset, open(filename, 'wb'))
print('Guardar: %s' % filename)
Ejemplo Completo
Podemos unir todos estos pasos de preparación de datos. El ejemplo completo se enumera a continuación.
import string
import re
from os import listdir
from nltk.corpus import stopwords
from pickle import dump
# cargar doc en la memoria
def load_doc(filename):
# abrir archivo en modo solo lectura
file = open(filename, 'r')
# leer todo el texto
text = file.read()
# cerrar el archivo
file.close()
return text
# Convierte a Doc en tokens limpios
def clean_doc(doc):
# dividido en tokens por el espacio en blanco
tokens = doc.split()
# prepare a regex para el filtrado de caracteres
re_punc = re.compile('[%s]' % re.escape(string.punctuation))
# Elimina la puntuación de cada palabra
tokens = [re_punc.sub('', w) for w in tokens]
# eliminar los tokens restantes que no estén en orden alfabético
tokens = [word for word in tokens if word.isalpha()]
# filtra las palabras de parada
stop_words = set(stopwords.words('english'))
tokens = [w for w in tokens if not w in stop_words]
# filtrar las tokens cortas
tokens = [word for word in tokens if len(word) > 1]
tokens = ' '.join(tokens)
return tokens
# cargar todos los documentos en un directorio
def process_docs(directory, is_train):
documents = list()
# recorrer todos los archivos de la carpeta
for filename in listdir(directory):
# salta cualquier reseña en el set de prueba
if is_train and filename.startswith('cv9'):
continue
if not is_train and not filename.startswith('cv9'):
continue
# crear la ruta completa del archivo a abrir
path = directory + '/' + filename
# cargar doc
doc = load_doc(path)
# limpiar doc
tokens = clean_doc(doc)
# añadir a la lista
documents.append(tokens)
return documents
# cargar y limpiar un conjunto de datos
def load_clean_dataset(is_train):
# cargar documentos
neg = process_docs('txt_sentoken/neg', is_train)
pos = process_docs('txt_sentoken/pos', is_train)
docs = neg + pos
# preparar etiquetas
labels = [0 for _ in range(len(neg))] + [1 for _ in range(len(pos))]
return docs, labels
# guardar un conjunto de datos en un archivo
def save_dataset(dataset, filename):
dump(dataset, open(filename, 'wb'))
print('Guardar: %s' % filename)
# Cargar y limpiar todas las críticas
train_docs, ytrain = load_clean_dataset(True)
test_docs, ytest = load_clean_dataset(False)
# guardar conjuntos de datos de formación
save_dataset([train_docs, ytrain], 'train.pkl')
save_dataset([test_docs, ytest], 'test.pkl')
Al ejecutar el ejemplo se limpian los documentos de revisión de películas de texto, se crean etiquetas y se guardan los datos preparados tanto para el entrenamiento como para los conjuntos de datos de prueba en train.pkl y test.pkl respectivamente. Ahora estamos listos para desarrollar nuestro modelo.
Desarrollo del modelo multicanal
En esta sección, desarrollaremos una red neural convolucional multicanal para el problema de predicción del análisis de sentimientos. Esta sección está dividida en tres partes:
- Codificar datos
- Definir modelo.
- Ejemplo completo.
Codificar datos
El primer paso es cargar el conjunto de datos de entrenamiento limpio. La función abajo nombrada load_dataset() puede ser llamada para cargar el conjunto de datos del entrenamiento.
# cargar un conjunto de datos limpio
def load_dataset(filename):
return load(open(filename, 'rb'))
trainLines, trainLabels = load_dataset('train.pkl')
A continuación, debemos instalar un Keras Tokenizer en el conjunto de datos de entrenamiento. Usaremos este tokenizador para definir el vocabulario de la capa de incrustación y codificar los documentos de revisión como enteros. La función create_tokenizer() a continuación creará un Tokenizer con una lista de documentos.
# encaja en un tokenizer def create_tokenizer(lines): tokenizer = Tokenizer() tokenizer.fit_on_texts(lines) return tokenizer
También necesitamos saber la longitud máxima de las secuencias de entrada como entrada para el modelo y rellenar todas las secuencias a la longitud fija. La función max_length() a continuación calculará la longitud máxima (número de palabras) para todas las revisiones en el conjunto de datos de entrenamiento.
# calcular la longitud máxima del documento def max_length(lines): return max([len(s.split()) for s in lines])
También necesitamos saber el tamaño del vocabulario para la capa de incrustación. Esto se puede calcular a partir del Tokenizer preparado, como se indica a continuación:
# calcular el tamaño del vocabulario vocab_size = len(tokenizer.word_index) + 1
Finalmente, podemos codificar y rellenar el texto de revisión de la película. La función debajo de nombre encode_text() codificará y rellenará los datos de texto hasta la longitud máxima de revisión.
# codificar una lista de líneas def encode_text(tokenizer, lines, length): # codificación entera encoded = tokenizer.texts_to_sequences(lines) # secuencias codificadas por pads padded = pad_sequences(encoded, maxlen=length, padding='post') return padded
Definir modelo
Un modelo estándar para la clasificación de documentos es utilizar una capa de incrustación como entrada, seguida de una red neuronal convolucional unidimensional, una capa de agrupación y, a continuación, una capa de salida de predicción. El tamaño del núcleo en la capa convolucional define el número de palabras a considerar cuando la convolución se pasa a través del documento de entrada de texto, proporcionando un parámetro de agrupación. Una red neuronal convolucional multicanal para la clasificación de documentos implica el uso de múltiples versiones del modelo estándar con núcleos de diferentes tamaños. Esto permite que el documento sea procesado en diferentes resoluciones o diferentes n-gramas (grupos de palabras) a la vez, mientras que el modelo aprende a integrar mejor estas interpretaciones.
Este enfoque fue descrito por primera vez por Yoon Kim en su artículo de 2014 titulado Convolutional Neural Networks for Sentence Classification. En el artículo, Kim experimentó con capas de incrustación estáticas y dinámicas (actualizadas), podemos simplificar el enfoque y en su lugar centrarnos sólo en el uso de diferentes tamaños de núcleo. Este enfoque se entiende mejor con un diagrama tomado del documento de Kim.
En Keras, se puede definir un modelo de entrada múltiple usando la API funcional. Definiremos un modelo con tres canales de entrada para procesar 4-gramos, 6-gramos, y 8-gramos de texto de revisión de películas. Cada canal se compone de los siguientes elementos:
- Capa de entrada que define la longitud de las secuencias de entrada.
- Capa de incrustación ajustada al tamaño del vocabulario y representaciones 100-dimensionales de valor real.
- Capa de Conv1D con 32 filtros y un tamaño de núcleo configurado para el número de palabras a leer a la vez.
- MaxPooling1D para consolidar la salida de la capa convolucional.
- Aplanar la capa para reducir la salida tridimensional a dos dimensiones para la concatenación.
La salida de los tres canales se concatena en un solo vector y se procesa mediante una capa densa y una capa de salida. La siguiente función define y devuelve el modelo. Como parte de la definición del modelo, se imprime un resumen del modelo definido y se crea un gráfico del modelo que se guarda en un archivo.
# definir el modelo def define_model(length, vocab_size): # canal 1 inputs1 = Input(shape=(length,)) embedding1 = Embedding(vocab_size, 100)(inputs1) conv1 = Conv1D(filters=32, kernel_size=4, activation='relu')(embedding1) drop1 = Dropout(0.5)(conv1) pool1 = MaxPooling1D(pool_size=2)(drop1) flat1 = Flatten()(pool1) # canal 2 inputs2 = Input(shape=(length,)) embedding2 = Embedding(vocab_size, 100)(inputs2) conv2 = Conv1D(filters=32, kernel_size=6, activation='relu')(embedding2) drop2 = Dropout(0.5)(conv2) pool2 = MaxPooling1D(pool_size=2)(drop2) flat2 = Flatten()(pool2) # canal 3 inputs3 = Input(shape=(length,)) embedding3 = Embedding(vocab_size, 100)(inputs3) conv3 = Conv1D(filters=32, kernel_size=8, activation='relu')(embedding3) drop3 = Dropout(0.5)(conv3) pool3 = MaxPooling1D(pool_size=2)(drop3) flat3 = Flatten()(pool3) # union merged = concatenate([flat1, flat2, flat3]) # interpretacion dense1 = Dense(10, activation='relu')(merged) outputs = Dense(1, activation='sigmoid')(dense1) model = Model(inputs=[inputs1, inputs2, inputs3], outputs=outputs) # compilacion model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) # resumen model.summary() plot_model(model, show_shapes=True, to_file='multichannel.png') return model
Ejemplo completo
Juntando todo esto, el ejemplo completo se muestra a continuación.
from pickle import load
from numpy import array
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
from keras.utils.vis_utils import plot_model
from keras.models import Model
from keras.layers import Input
from keras.layers import Dense
from keras.layers import Flatten
from keras.layers import Dropout
from keras.layers import Embedding
from keras.layers.convolutional import Conv1D
from keras.layers.convolutional import MaxPooling1D
from keras.layers.merge import concatenate
# cargar un conjunto de datos limpio
def load_dataset(filename):
return load(open(filename, 'rb'))
# caben en un tokenizador
def create_tokenizer(lines):
tokenizer = Tokenizer()
tokenizer.fit_on_texts(lines)
return tokenizer
# calcular la longitud máxima del documento
def max_length(lines):
return max([len(s.split()) for s in lines])
# codificar una lista de líneas
def encode_text(tokenizer, lines, length):
# entero codificar
encoded = tokenizer.texts_to_sequences(lines)
# Secuencias codificadas por pads
padded = pad_sequences(encoded, maxlen=length, padding='post')
return padded
# definir el modelo
def define_model(length, vocab_size):
# canal 1
inputs1 = Input(shape=(length,))
embedding1 = Embedding(vocab_size, 100)(inputs1)
conv1 = Conv1D(filters=32, kernel_size=4, activation='relu')(embedding1)
drop1 = Dropout(0.5)(conv1)
pool1 = MaxPooling1D(pool_size=2)(drop1)
flat1 = Flatten()(pool1)
# canal 2
inputs2 = Input(shape=(length,))
embedding2 = Embedding(vocab_size, 100)(inputs2)
conv2 = Conv1D(filters=32, kernel_size=6, activation='relu')(embedding2)
drop2 = Dropout(0.5)(conv2)
pool2 = MaxPooling1D(pool_size=2)(drop2)
flat2 = Flatten()(pool2)
# canal 3
inputs3 = Input(shape=(length,))
embedding3 = Embedding(vocab_size, 100)(inputs3)
conv3 = Conv1D(filters=32, kernel_size=8, activation='relu')(embedding3)
drop3 = Dropout(0.5)(conv3)
pool3 = MaxPooling1D(pool_size=2)(drop3)
flat3 = Flatten()(pool3)
# unión
merged = concatenate([flat1, flat2, flat3])
# interpretacion
dense1 = Dense(10, activation='relu')(merged)
outputs = Dense(1, activation='sigmoid')(dense1)
model = Model(inputs=[inputs1, inputs2, inputs3], outputs=outputs)
# compilar
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
# resumen
model.summary()
plot_model(model, show_shapes=True, to_file='model.png')
return model
# cargar conjunto de datos de entrenamiento
trainLines, trainLabels = load_dataset('train.pkl')
# crear tokenizador
tokenizer = create_tokenizer(trainLines)
# calcular la longitud máxima del documento
length = max_length(trainLines)
print('Longitud máxima del documento: %d' % length)
# calcular el tamaño del vocabulario
vocab_size = len(tokenizer.word_index) + 1
print('Tamaño del vocabulario: %d' % vocab_size)
# codificar datos
trainX = encode_text(tokenizer, trainLines, length)
# definir modelo
model = define_model(length, vocab_size)
# modelo adecuado
model.fit([trainX,trainX,trainX], array(trainLabels), epochs=7, batch_size=16)
# guardar el modelo
model.save('model.h5')
Al ejecutar el ejemplo, se imprime primero un resumen del conjunto de datos de formación preparado.
Longitud maxima del documento: 1380 Tamaño del vocabulario: 44277
El modelo se ajusta con relativa rapidez y parece mostrar una buena habilidad en el conjunto de datos de entrenamiento.
... Epoch 3/7 1800/1800 [==============================] - 29s - loss: 0.0460 - acc: 0.9894 Epoch 4/7 1800/1800 [==============================] - 30s - loss: 0.0041 - acc: 1.0000 Epoch 5/7 1800/1800 [==============================] - 31s - loss: 0.0010 - acc: 1.0000 Epoch 6/7 1800/1800 [==============================] - 30s - loss: 3.0271e-04 - acc: 1.0000 Epoch 7/7 1800/1800 [==============================] - 28s - loss: 1.3875e-04 - acc: 1.0000
Un gráfico del modelo definido se guarda en un archivo, mostrando claramente los tres canales de entrada para el modelo.
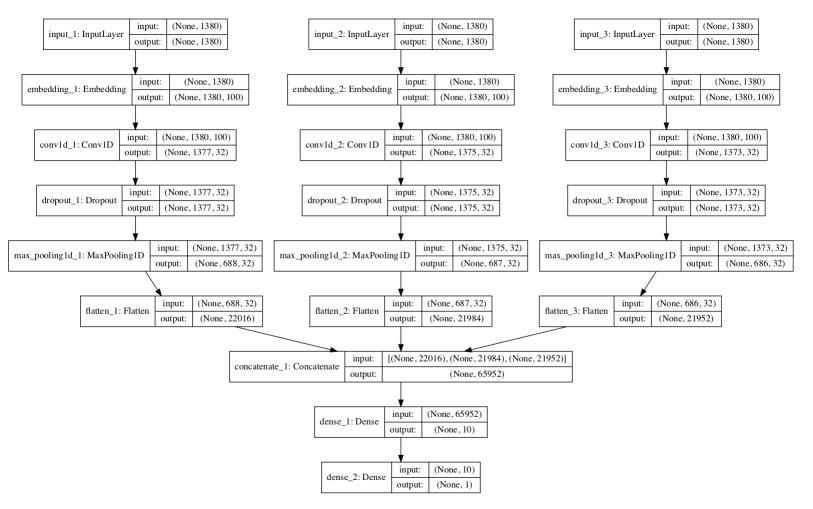
El modelo es apto para varias épocas y se guarda en el archivo model.h5 para su posterior evaluación.
Evaluar modelo
En esta sección, podemos evaluar el modelo de ajuste prediciendo el sentimiento en todas las revisiones del conjunto de datos de prueba no visto. Utilizando las funciones de carga de datos desarrolladas en la sección anterior, podemos cargar y codificar tanto los conjuntos de datos de formación como los de prueba.
# conjuntos de datos de carga
trainLines, trainLabels = load_dataset('train.pkl')
testLines, testLabels = load_dataset('test.pkl')
# crear tokenizer
tokenizer = create_tokenizer(trainLines)
# calculate max document length
length = max_length(trainLines)
# calcular tamaño del vocabulario
vocab_size = len(tokenizer.word_index) + 1
print('Longitud máxima del documento: %d' % length)
print('Tamaño del vocabulario: %d' % vocab_size)
# codificador de datos
trainX = encode_text(tokenizer, trainLines, length)
testX = encode_text(tokenizer, testLines, length)
print(trainX.shape, testX.shape)
Podemos cargar el modelo guardado y evaluarlo tanto en el conjunto de datos de entrenamiento como en el de pruebas. El ejemplo completo se enumera a continuación.
from pickle import load
from numpy import array
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
from keras.models import load_model
# cargar un conjunto de datos limpio
def load_dataset(filename):
return load(open(filename, 'rb'))
# caben en un tokenizador
def create_tokenizer(lines):
tokenizer = Tokenizer()
tokenizer.fit_on_texts(lines)
return tokenizer
# calcular la longitud máxima del documento
def max_length(lines):
return max([len(s.split()) for s in lines])
# codificar una lista de líneas
def encode_text(tokenizer, lines, length):
# entero codificar
encoded = tokenizer.texts_to_sequences(lines)
# Secuencias codificadas por pads
padded = pad_sequences(encoded, maxlen=length, padding='post')
return padded
# cargar conjuntos de datos
trainLines, trainLabels = load_dataset('train.pkl')
testLines, testLabels = load_dataset('test.pkl')
# crear tokenizador
tokenizer = create_tokenizer(trainLines)
# calcular la longitud máxima del documento
length = max_length(trainLines)
print('Longitud máxima del documento: %d' % length)
# calcular tamaño del vocabulario
vocab_size = len(tokenizer.word_index) + 1
print('Tamaño del vocabulario: %d' % vocab_size)
# codificar datos
trainX = encode_text(tokenizer, trainLines, length)
testX = encode_text(tokenizer, testLines, length)
# cargar el modelo
model = load_model('model.h5')
# evaluar el modelo sobre el conjunto de datos de la formación
_, acc = model.evaluate([trainX,trainX,trainX], array(trainLabels), verbose=0)
print('Exactitud del entrenamiento: %.2f' % (acc*100))
# evaluar modelo en conjunto de datos de prueba
_, acc = model.evaluate([testX,testX,testX], array(testLabels), verbose=0)
print('Exactitud de la prueba: %.2f' % (acc*100))
Al ejecutar el ejemplo se imprime la habilidad del modelo tanto en los conjuntos de datos de entrenamiento como en los de prueba. Podemos ver que, como era de esperar, la habilidad en el conjunto de datos de entrenamiento es excelente, aquí con una precisión del 100%. También podemos ver que la habilidad del modelo en el conjunto de datos de prueba no visto es también muy impresionante, alcanzando el 88,5%, que está por encima de la habilidad del modelo reportado en el documento de 2014 (aunque no es una comparación directa de manzanas con manzanas).
Dada la naturaleza estocástica de las redes neuronales, sus resultados específicos pueden variar. Considere la posibilidad de ejecutar el ejemplo varias veces.
Exactitud del entrenamiento: 100.00 Exactitud de la prueba: 88.50
Extensiones
En esta sección se enumeran algunas ideas para ampliar el tutorial que tal vez desee explorar.
- Diferentes n-gramas: Explora el modelo cambiando el tamaño del núcleo (número de n-gramos) utilizado por los canales en el modelo para ver cómo afecta a la habilidad del modelo.
- Más o menos canales: Explora el uso de más o menos canales en el modelo y vea cómo afecta a la habilidad del modelo.
- Incrustación compartida: Explora las configuraciones en las que cada canal comparte la misma incrustación de palabras e informe sobre el impacto en la habilidad del modelo.
- Red másprofunda: Las redes neuronales convolucionales funcionan mejor en visión por computador cuando son más profundas. Explore el uso de modelos más profundos aquí y vea cómo afecta la habilidad del modelo.
- Secuencias Truncadas: Rellenar todas las secuencias a la longitud de la secuencia más larga podría ser extremo si la secuencia más larga es muy diferente a todas las otras revisiones. Estudiar la distribución de las duraciones de las revisiones y truncar las revisiones a una duración media.
- Vocabulario truncado: Eliminamos palabras poco frecuentes, pero todavía teníamos un gran vocabulario de más de 25.000 palabras. Explore la posibilidad de reducir aún más el tamaño del vocabulario y el efecto en la habilidad del modelo.
- Épocas y tamaño de lote: El modelo parece ajustarse rápidamente al conjunto de datos de formación. Explore configuraciones alternativas del número de épocas de entrenamiento y tamaño de lote y utilice el conjunto de datos de prueba como un conjunto de validación para elegir un mejor punto de parada para el entrenamiento del modelo.
- Pre-entrenamiento e incrustación: Explora el pre-entrenamiento de una palabra de Word2Vec incrustada en el modelo y el impacto en la habilidad del modelo con y sin ajuste fino durante el entrenamiento.
- Utiliza GloVe Embedding: Explore la carga de la incrustación de GloVe previamente entrenada y el impacto en la habilidad del modelo con y sin ajuste fino durante el entrenamiento.
- Modelo Final de entrenamiento: Entrenar un modelo final en todos los datos disponibles y utilizarlo para hacer predicciones sobre las críticas de películas reales ad hoc de Internet.
Si exploras alguna de estas extensiones, me encantaría saberlo.
➡ Continúa aprendiendo con nosotros en nuestro curso: