
Blog
Modelos de redes neuronales para la generación de subtítulos
La generación de subtítulos es un problema desafiante de inteligencia artificial que se basa tanto en la visión por ordenador como en el procesamiento del lenguaje natural. La arquitectura de red neuronal recurrente codificador-decodificador ha demostrado ser eficaz en este problema. La implementación de esta arquitectura puede destilarse en modelos basados en la inyección y la fusión, y ambos hacen diferentes suposiciones sobre el papel de la red neuronal recurrente para abordar el problema. En este capítulo, tú descubrirás las arquitecturas de inyección y fusión para los modelos de redes neuronales recurrentes de codificador-decodificador en la generación de subtítulos. Después de leer este capítulo, tú sabrás:
- El reto de la generación de subtítulos y el uso de la arquitectura codificador-decodificador.
- El modelo de inyección que combina la imagen codificada con cada palabra para generar la siguiente palabra en el título.
- El modelo de fusión que codifica por separado la imagen y la descripción que se decodifican para generar la siguiente palabra en la leyenda.
Vamos a empezar.
Generación de pies de foto
El problema de la generación de subtítulos de imágenes consiste en generar una descripción legible y concisa del contenido de una fotografía. Se trata de un difícil problema de inteligencia artificial, ya que requiere tanto técnicas de visión artificial para interpretar el contenido de la fotografía, como técnicas de procesamiento del lenguaje natural para generar la descripción textual. Recientemente, los métodos de Deep Learning han logrado resultados de vanguardia en este difícil problema. Los resultados son tan impresionantes que este problema se ha convertido en un problema de demostración estándar para las capacidades de Deep Learning.
Arquitectura de codificador-decodificador
Se utiliza una arquitectura de red neuronal recurrente de codificador-decodificador estándar para resolver el problema de generación de subtítulos de imágenes. Esto implica dos elementos:
- Codificador: Un modelo de red que lee la entrada de la fotografía y codifica el contenido en un vector de longitud fija utilizando una representación interna.
- Decodificador: Un modelo de red que lee la fotografía codificada y genera la salida de la descripción textual.
Generalmente, una red neuronal convolucional se utiliza para codificar las imágenes y una red neuronal recurrente, como una red de memoria de corto plazo a largo plazo, se utiliza para codificar la secuencia de texto generada hasta ahora, y/o generar la siguiente palabra en la secuencia. Hay muchas maneras de realizar esta arquitectura para el problema de la generación de subtítulos. Es común utilizar un modelo de red neural convolucional preentrenado, entrenado en un problema de clasificación fotográfica desafiante, para codificar la fotografía. El modelo pre-entrenado puede ser cargado, la salida del modelo removido, y la representación interna de la fotografía utilizada como codificación o representación interna de la imagen de entrada.
También es común enmarcar el problema de tal manera que el modelo genere una palabra de la descripción textual de salida, dada tanto la fotografía como la descripción generada hasta el momento como entrada. En este encuadre, el modelo se llama recursivamente hasta que se genera la secuencia de salida completa.
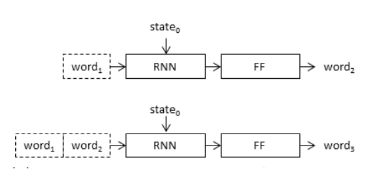
Este enmarcado puede ser implementado usando una de dos arquitecturas, llamada por Marc Tanti, et al. como modelos de inyección y fusión.
Modelo de inyección
El modelo de inyección combina la forma codificada de la imagen con cada palabra de la descripción de texto generada hasta ahora. El enfoque utiliza la red neuronal recurrente como modelo de generación de texto que utiliza una secuencia de información de imagen y palabra como entrada para generar la siguiente palabra en la secuencia.

Este modelo combina las preocupaciones de la imagen con cada palabra de entrada, requiriendo que el codificador desarrolle una codificación que incorpore tanto información visual como lingüística.
Modelo de fusión
El modelo de fusión combina la forma codificada de la entrada de imagen con la forma codificada de la descripción de texto generada hasta ahora. La combinación de estas dos entradas codificadas es utilizada por un modelo de decodificador muy simple para generar la siguiente palabra en la secuencia. El enfoque utiliza la red neuronal recurrente sólo para codificar el texto generado hasta ahora.

Esto separa la preocupación de modelar la entrada de imagen, la entrada de texto y la combinación e interpretación de las entradas codificadas. Como se mencionó anteriormente, es común utilizar un modelo pre-entrenado para codificar la imagen, pero de manera similar, esta arquitectura también permite utilizar un modelo de lenguaje pre-entrenado para codificar la entrada de texto de los subtítulos.
Hay múltiples maneras de combinar las dos entradas codificadas, tales como concatenación, multiplicación y adición, aunque los experimentos de Marc Tanti, han demostrado que la adición funciona mejor. En general, en los trabajos de Marc Tanti, encontraron que la arquitectura de fusión era más efectiva en comparación con el enfoque de inyección.
Más información sobre el modelo de fusión
El éxito del modelo de fusión para la arquitectura codificador-decodificador sugiere que el papel de la red neuronal recurrente es codificar la entrada en lugar de generar salida. Esto se aparta del entendimiento común en el que se cree que la contribución de la red neuronal recurrente es la de un modelo generativo.
La comparación explícita de los modelos de inyección y fusión, y el éxito de la fusión sobre la inyección para la generación de subtítulos, plantea la cuestión de si este enfoque se traduce en problemas relacionados con la generación de secuencia a secuencia. En lugar de los modelos pre-aprendidos que se utilizan para codificar imágenes, los modelos lingüísticos pre-aprendidos podrían utilizarse para codificar el texto de origen en problemas tales como el resumen del texto, la respuesta a preguntas y la traducción automática.
➡ Continúa aprendiendo con nosotros en nuestro curso: