
Blog
-Introducción al machine learning.
-Definir categorías principales de machine learning.
-Entender un poco sobre aprendizaje supervisado y no supervisado de machine learning.
Mientras que a mucha gente le gusta hacer que suene realmente complejo, Machine Learning es bastante simple en su núcleo. El Machine Learning brilla cuando el número de dimensiones excede lo que podemos representar gráficamente, pero vamos a hacer un ejemplo de una representación 2D del Machine Learning con dos características.
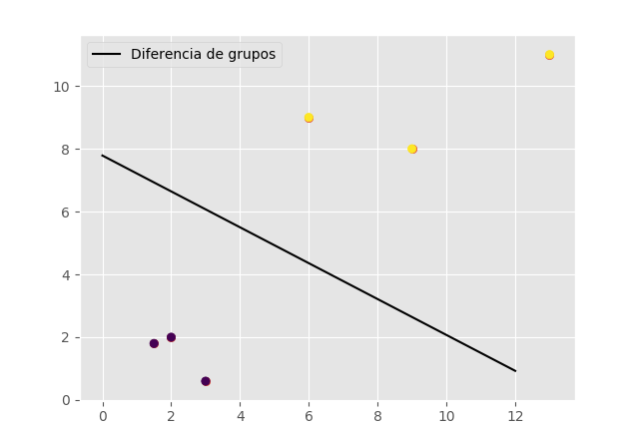
En esta imagen te mostramos un ejemplo extremadamente básico de cómo funciona una Máquina de Vectores de Soporte o en inglés Support Vector Machine (SVM), con el siguiente grupo de datos:
x = [2, 6, 1.5, 9, 3, 13] y = [2, 9, 1.8, 8, 0.6, 11]
Como puede ver, este conjunto de datos tiene algunos pares más grandes y otros más pequeños. Lo que una SVM va a hacer es ayudarle a encontrar la línea divisoria perfecta entre los datos. Entonces podemos ir un paso más allá y pedirle al SVM que prediga a qué “grupo” pertenecería una coordenada como[1.8,0.2].
Con las características (piensa en ellas como dimensiones) como 2D o 3D, es realmente muy fácil de visualizar y para nosotros los humanos simplemente mirar la gráfica y hacer un poco de clustering básico. El aprendizaje automático, sin embargo, se puede utilizar para analizar, por ejemplo, 100 características (100 dimensiones). Inténtalo tú mismo con 5 billones de muestras ?
Esta serie se ocupa del Machine Learning de forma práctica y utilizando el lenguaje de programación Python y el módulo Scikit-learn.
Nuestro ejemplo utilizado aquí es analizar las características fundamentales de las empresas cotizadas en bolsa, comparando estos fundamentos con el desempeño del valor de mercado de las acciones a lo largo del tiempo. Nuestro objetivo es ver si podemos utilizar el aprendizaje automático para identificar buenas acciones con sólidos fundamentos que son importantes para poder invertir en ellas.



Hay dos categorías principales de Machine Learning:
- Aprendizaje supervisado
- Aprendizaje no supervisado
Dentro del aprendizaje supervisado, tenemos clasificación y regresión. ¿Recuerdas cuando dije que el aprendizaje de máquinas es en realidad sólo clasificación de máquinas? Todavía lo es, pero también existe una forma específica de Machine Learning llamada clasificación.
Por lo tanto, el aprendizaje supervisado es donde los científicos supervisamos y a veces dirigimos el proceso de aprendizaje.
Dentro del aprendizaje supervisado, tenemos la clasificación. Un ejemplo aquí podría ser donde usted tiene un conjunto de números, y usted tiene un desconocido que desea encajar en una de sus categorías predefinidas.
También tenemos regresión en el aprendizaje supervisado, donde tenemos ciertas variables conocidas de los datos en cuestión, y entonces, usando muestras pasadas o datos históricos, podemos hacer predicciones sobre lo desconocido.
Un ejemplo aquí sería lo que Facebook te hace cuando adivina dónde vives. Dada tu red y las personas con las que tienes los vínculos más estrechos y con las que te comunicas, de dónde proceden… Facebook puede adivinar que tú también eres de esa ciudad.
Otro ejemplo sería si tomamos muestras de un millón de personas, luego encontramos a una persona desconocida que tiene el pelo rubio y la piel pálida. Tenemos curiosidad por saber de qué color son los ojos que tiene. Nuestro algoritmo de regresión probablemente sugerirá que nuestra nueva persona tiene ojos azules o grises, basados en las muestras anteriores.

El aprendizaje no supervisado es donde creamos el algoritmo de aprendizaje, entonces simplemente arrojamos una tonelada de datos a la computadora y dejamos que la computadora le dé sentido.
Lo básico del aprendizaje no supervisado es simplemente lanzar un conjunto de datos masivos a la máquina para que clasifique o agrupe los datos. Sólo recuerde que todo el machine learning es una clasificación de máquinas, donde estamos predefiniendo categorías y forzando a la máquina a elegir una.
Cuando “entrenamos” la máquina, es donde damos los datos que son pre-clasificados.
Cuando probamos algo, utilizamos nuevos datos no clasificados en la máquina, pero conocemos la clasificación adecuada. Generalmente, usted alimenta los datos a través de los datos para probarlos, luego usted ejecuta las respuestas correctas a través de la máquina y chequea cuántas la máquina acertó o falló.
Como pronto se dará cuenta, la parte más difícil es adquirir los datos necesarios para el entrenamiento y las pruebas.
Mientras que los algoritmos de Machine Learning son increíblemente largos y complejos, usted casi nunca necesitará escribir sus propios algoritmos, excepto por diversión.

Es mejor entender algunos de los parámetros principales, como ” learning rate” (tasa de aprendizaje), así como lo que el aprendizaje en máquina está haciendo realmente por usted, de esa manera usted puede determinar la mejor manera de aplicar el Machine Learning a un problema. Por eso me parece una gran idea visualizar algunos ejemplos antes de pasar a probemas con muchas dimensiones.
El objetivo de este curso es aplicar un algoritmo de Machine Learning a un problema.
➡ Si quieres aprender mucho mas de Machine Learning, ingresa a nuestro curso:
Curso de Machine Learning en Python
good lesson! me esclarifico lo basico en el machine learning
que interesante !!..gracias sigan así….