
Blog
Generación de subtítulos de imágenes neuronales
Subtitular una imagen implica generar una descripción textual legible por el ser humano, a partir de una imagen, como una fotografía. Es un problema fácil para un humano, pero muy desafiante para una máquina, ya que implica tanto la comprensión del contenido de una imagen como la forma de traducir esta comprensión al lenguaje natural. Recientemente, los métodos de Deep Learning han desplazado a los métodos clásicos y están logrando resultados de última generación para el problema de generar automáticamente descripciones, llamadas subtítulos, para las imágenes. En este capítulo, descubrirá cómo se pueden utilizar los modelos de redes neuronales profundas para generar automáticamente descripciones de imágenes, como las fotografías. Después de completar este capítulo, tú sabrás:
- Sobre el reto de generar descripciones textuales para imágenes y la necesidad de combinar los avances de la visión por ordenador y el procesamiento del lenguaje natural.
- Sobre los elementos que componen un modelo de subtitulado de características neurales, es decir, el extractor de características y el modelo de lenguaje.
- Cómo se pueden organizar los elementos del modelo en un codificador-decodificador, posiblemente con el uso de un mecanismo de atención.
Vamos a empezar.
Resumen de la lección de hoy
Este tutorial se divide en las siguientes partes:
- Descripción de una imagen con texto
- Modelo Neural de Subtitulado
- Arquitectura de codificador-decodificador
Descripción de una imagen con texto
Describir una imagen es el problema de generar una descripción textual legible por el ser humano de una imagen, como una fotografía de un objeto o escena. El problema a veces se llama anotación automática de imagen o etiquetado de imagen. Es un problema fácil para un humano, pero muy difícil para una máquina.
Una solución requiere tanto que el contenido de la imagen sea entendido y traducido a significado en los términos de las palabras, como que las palabras deben encadenarse para ser comprensibles. Combina tanto la visión por ordenador como el procesamiento del lenguaje natural y constituye un verdadero reto en la inteligencia artificial más amplia.
Además, los problemas pueden tener dificultades; veamos tres variaciones diferentes del problema con ejemplos.
- Clasificar imagen: Asignar a una imagen una etiqueta de clase de una de las muchas clases conocidas.
- Describir la imagen: Generar una descripción textual de la imagen del contenido.
- Anotar Imagen: Generar descripciones textuales para regiones específicas de la imagen.
El problema general también puede ampliarse para describir imágenes en vídeo a lo largo del tiempo. En este capítulo, centraremos nuestra atención en la descripción de imágenes, que describiremos como subtitulado de imágenes.
Modelo Neural de Subtitulado
Los modelos de redes neuronales han llegado a dominar el campo de la generación automática de subtítulos; esto se debe principalmente a que los métodos están demostrando resultados de vanguardia. Los dos métodos dominantes antes de los modelos de red neural de extremo a extremo para generar subtítulos de imágenes, eran los métodos basados en plantillas y los métodos basados en el vecino más cercano y la modificación de los subtítulos existentes.
Los modelos de redes neuronales para subtitular involucran dos elementos principales:
- Extracción de características.
- Modelo de lenguaje.
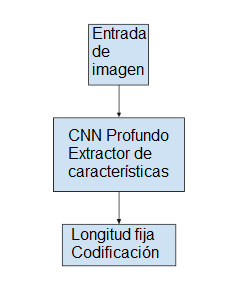
Modelo de extracción de características
El modelo de extracción de características es una red neuronal que, dada una imagen, es capaz de extraer las características más destacadas, a menudo en forma de un vector de longitud fija. Las características extraídas son una representación interna de la imagen, no algo directamente inteligible. Se utiliza una red neural convolucional profunda, o CNN, como submodelo de extracción de características. Esta red puede ser entrenada directamente sobre las imágenes en el conjunto de datos de subtitulado de imágenes. Alternativamente, se puede utilizar un modelo pre-entrenado, como un modelo de última generación utilizado para la clasificación de imágenes, o algún híbrido en el que se utiliza un modelo pre-entrenado y se ajusta al problema. Es popular el uso de modelos de alto rendimiento en el conjunto de datos de ImageNet desarrollado para el desafío ILSVRC, como el modelo del Oxford Vision Geometry Group, llamado VGG para abreviar.
Modelo de lenguaje
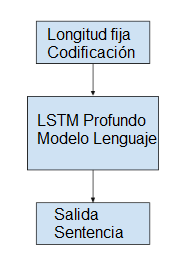
Generalmente, un modelo de lenguaje predice la probabilidad de la siguiente palabra en la secuencia, dadas las palabras ya presentes en la secuencia. Para el subtitulado de imágenes, el modelo de lenguaje es una red neuronal que, dadas las características extraídas de la red, es capaz de predecir la secuencia de palabras en la descripción y construir la descripción condicionada a las palabras que ya han sido generadas. Es popular utilizar una red neuronal recurrente, como una red de memoria de corto plazo a largo plazo, o LSTM, como modelo de lenguaje. Cada paso de tiempo de salida genera una nueva palabra en la secuencia. Cada palabra que se genera se codifica usando una palabra incrustada (como Word2Vec) y se pasa como entrada al decodificador para generar la palabra siguiente.
Una mejora en el modelo implica reunir la distribución de probabilidad de las palabras a través del vocabulario para la secuencia de salida y buscarla para generar múltiples descripciones posibles. Estas descripciones pueden ser calificadas y clasificadas por probabilidad. Es común utilizar una búsqueda de haces para esta búsqueda. El modelo de lenguaje puede ser entrenado de forma autónoma usando características pre-calculadas extraídas del conjunto de datos de la imagen; puede ser entrenado conjuntamente con la red de extracción de características, o alguna combinación.
Arquitectura de codificador-decodificador
Una forma popular de estructurar los sub-modelos es usar una arquitectura de Codificador-Decodificador donde ambos modelos son entrenados conjuntamente.
Se trata de una arquitectura desarrollada para la traducción automática en la que una secuencia de entrada, por ejemplo en francés, está codificada como un vector de longitud fija por una red de codificadores. Una red de decodificadores separada lee la codificación y genera una secuencia de salida en el nuevo idioma, por ejemplo, en inglés. Un beneficio de este enfoque, además de la impresionante habilidad del enfoque, es que se puede capacitar a un solo modelo de extremo a extremo sobre el problema. Cuando se adapta para el subtitulado de imágenes, la red de codificadores es una red neural convolucional profunda, y la red de decodificadores es una pila de capas LSTM.
Modelo de subtitulado con atención
Una limitación de la arquitectura Codificador-Decodificador es que se utiliza una sola representación de longitud fija para mantener las características extraídas. Esto se abordó en la traducción automática mediante el desarrollo de la atención a través de una codificación más rica, lo que permite que el decodificador aprenda dónde colocar la atención a medida que se genera cada palabra de la traducción. El enfoque de atención también se ha utilizado para mejorar el rendimiento de la arquitectura Codificador-Decodificador para el subtitulado de imágenes, permitiendo que el decodificador aprenda dónde poner atención en la imagen al generar cada palabra de la descripción.
Un beneficio de este enfoque es que es posible visualizar exactamente dónde se coloca la atención mientras se genera cada palabra en una descripción.
➡ Aprende mas de Procesamiento de Lenguaje Natural en nuestro curso: