
Blog
Cómo desarrollar un modelo de lenguaje neural basado en palabras
El modelado del lenguaje implica predecir la siguiente palabra en una secuencia dada la secuencia de palabras ya presentes. Un modelo de lenguaje es un elemento clave en muchos modelos de procesamiento de lenguaje natural, como la traducción automática y el reconocimiento de voz. La elección de cómo se enmarca el modelo de idioma debe coincidir con la forma en que se pretende utilizar el modelo de idioma. En este tutorial, descubrirás cómo el encuadre de un modelo de lenguaje afecta la habilidad del modelo al generar secuencias cortas a partir de una canción infantil. Después de completar este tutorial, tú sabrás:
- El reto de desarrollar un buen encuadre de un modelo de lenguaje basado en palabras para una aplicación dada.
- Cómo desarrollar marcos basados en una palabra, dos palabras y líneas para modelos de lenguaje basados en palabras.
- Cómo generar secuencias utilizando un modelo de lenguaje adecuado.
Vamos a empezar.
Descripción general de la lección de hoy
Este tutorial está dividido en las siguientes partes:
- Modelado de Lenguaje de Enmarcado
- Rima infantil Jack y Jill
- Modelo 1: Secuencias One-Word-In, One-Word-Out
- Modelo 2: Secuencia línea por línea
- Modelo 3: Secuencia de entrada y salida de dos palabras
Modelado de Lenguaje de Enmarcado
Un modelo de lenguaje estadístico se aprende del texto sin procesar y predice la probabilidad de la siguiente palabra en la secuencia dadas las palabras ya presentes en la secuencia. Los modelos de lenguaje son un componente clave en modelos más grandes para desafiar los problemas de procesamiento del lenguaje natural, como la traducción automática y el reconocimiento de voz. También pueden desarrollarse como modelos independientes y utilizarse para generar nuevas secuencias que tengan las mismas propiedades estadísticas que el texto fuente.
Los modelos lingüísticos aprenden y predicen una palabra a la vez. El entrenamiento de la red implica proporcionar secuencias de palabras como entrada que se procesan una a la vez donde se puede hacer una predicción y aprender para cada secuencia de entrada. De manera similar, cuando se hacen predicciones, el proceso puede ser sembrado con una o unas pocas palabras, luego las palabras pronosticadas pueden ser reunidas y presentadas como entrada en predicciones subsecuentes para construir una secuencia de salida generada.
Por lo tanto, cada modelo implicará dividir el texto fuente en secuencias de entrada y salida, de modo que el modelo pueda aprender a predecir palabras. Hay muchas maneras de enmarcar las secuencias de un texto fuente para el modelado del lenguaje. En este tutorial, exploraremos tres maneras diferentes de desarrollar modelos de lenguaje basados en palabras en la biblioteca de Deep Learning de Keras. No existe un único enfoque óptimo, sino diferentes marcos que pueden adaptarse a diferentes aplicaciones.
Rima infantil Jack y Jill
Jack y Jill es una simple canción infantil. Se compone de cuatro líneas, según se indica a continuación:
Jack and Jill went up the hill To fetch a pail of water Jack fell down and broke his crown And Jill came tumbling after
Usaremos esto como nuestro texto fuente para explorar diferentes marcos de un modelo de lenguaje basado en palabras. Podemos definir este texto en Python como sigue:
# texto fuente data = """ Jack and Jill went up the hill\n To fetch a pail of water\n Jack fell down and broke his crown\n And Jill came tumbling after\n """
Modelo 1: Secuencias One-Word-In, One-Word-Out
Podemos empezar con un modelo muy simple. Dada una palabra como entrada, el modelo aprenderá a predecir la siguiente palabra en la secuencia. Por ejemplo:
X, y Jack, and and, Jill Jill, went ...
El primer paso es codificar el texto como números enteros. A cada palabra minúscula del texto fuente se le asigna un número entero único y podemos convertir las secuencias de palabras en secuencias de números enteros. Keras proporciona la clase Tokenizer que puede ser usada para realizar esta codificación. Primero, el Tokenizer encaja en el texto fuente para desarrollar el mapeo de palabras a enteros únicos. Entonces las secuencias de texto pueden ser convertidas en secuencias de números enteros llamando a la función texts_to_sequences().
# enteros codifican el texto tokenizer = Tokenizer() tokenizer.fit_on_texts([data]) encoded = tokenizer.texts_to_sequences([data])[0]
Necesitaremos saber el tamaño del vocabulario más adelante para definir la capa de incrustación de palabras en el modelo, y para codificar las palabras de salida usando una codificación en caliente. El tamaño del vocabulario se puede recuperar desde el Tokenizer entrenado accediendo al atributo word_index.
# determina el tamaño del vocabulario
vocab_size = len(tokenizer.word_index) + 1
print('Tamaño del vocabulario: %d' % vocab_size)
Al ejecutar este ejemplo, podemos ver que el tamaño del vocabulario es de 21 palabras. Añadimos uno, porque necesitaremos especificar el número entero para la palabra codificada más grande como un índice de matriz, por ejemplo, las palabras codificadas del 1 al 21 con las posiciones de las matrices 0 al 21 ó 22. Luego, necesitamos crear secuencias de palabras que se ajusten al modelo con una palabra como entrada y una palabra como salida.
# crear palabra -> secuencias de palabras
sequences = list()
for i in range(1, len(encoded)):
sequence = encoded[i-1:i+1]
sequences.append(sequence)
print('Secuencias totales: %d' % len(sequences))
La ejecución de esta pieza muestra que tenemos un total de 24 pares de entrada-salida para entrenar la red.
Secuencias totales: 24
Luego podemos dividir las secuencias en elementos de entrada (X) y salida (y). Esto es sencillo, ya que sólo tenemos dos columnas en los datos.
# dividido en elementos X e Y sequences = array(sequences) X, y = sequences[:,0],sequences[:,1]
Ajustaremos nuestro modelo para predecir una distribución de probabilidad a través de todas las palabras del vocabulario. Esto significa que necesitamos convertir el elemento de salida de un solo entero en una codificación en caliente con un 0 para cada palabra en el vocabulario y un 1 para la palabra real que el valor. Esto le da a la red una verdad de base para apuntar a partir de la cual podemos calcular el error y actualizar el modelo. Keras proporciona la función to_categorical() que podemos usar para convertir el entero a una codificación en caliente mientras especificamos el número de clases como el tamaño del vocabulario.
# una salida de codificación en caliente y = to_categorical(y, num_classes=vocab_size)
Ahora estamos listos para definir el modelo de red neuronal. El modelo utiliza una palabra aprendida incrustada en la capa de entrada. Esto tiene un vector de valor real para cada palabra en el vocabulario, donde cada vector de palabra tiene una longitud especificada. En este caso utilizaremos una proyección de 10 dimensiones. La secuencia de entrada contiene una sola palabra, por lo tanto la longitud de entrada = 1. El modelo tiene una sola capa oculta de LSTM con 50 unidades. Esto es mucho más de lo que se necesita. La capa de salida está compuesta por una neurona para cada palabra del vocabulario y utiliza una función de activación de softmax para garantizar que la salida se normaliza para que parezca una probabilidad.
# definir el modelo def define_model(vocab_size): model = Sequential() model.add(Embedding(vocab_size, 10, input_length=1)) model.add(LSTM(50)) model.add(Dense(vocab_size, activation='softmax')) # compilar red model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy']) # resumen del modelo definido model.summary() plot_model(model, to_file='model.png', show_shapes=True) return model
La estructura de la red puede resumirse del siguiente modo:
_________________________________________________________________ Layer (type) Output Shape Param # ================================================================= embedding_1 (Embedding) (None, 1, 10) 220 _________________________________________________________________ lstm_1 (LSTM) (None, 50) 12200 _________________________________________________________________ dense_1 (Dense) (None, 22) 1122 ================================================================= Total params: 13,542 Trainable params: 13,542 Non-trainable params: 0 _________________________________________________________________
Un gráfico del modelo definido se guarda en un archivo con el nombre model.png.
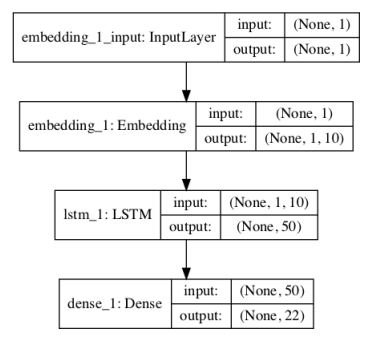
Usaremos esta misma estructura de red general para cada ejemplo de este tutorial, con pequeños cambios en la capa de incrustación aprendida. Podemos compilar y adaptar la red a los datos de texto codificados. Técnicamente, estamos modelando un problema de clasificación multiclase (predecir la palabra en el vocabulario), por lo tanto usando la función categórica de pérdida de entropía cruzada. Utilizamos la eficiente implementación de Adam de la precisión del descenso en pendiente y de la vía al final de cada época. El modelo es apto para 500 épocas de entrenamiento, una vez más, quizás más de lo necesario. La configuración de la red no fue ajustada para este y otros experimentos posteriores; se eligió una configuración demasiado prescrita para asegurar que pudiéramos centrarnos en el encuadre del modelo del lenguaje.
Después de que el modelo encaja, lo probamos pasándole una palabra dada del vocabulario y haciendo que el modelo prediga la siguiente palabra. Aquí pasamos a ‘Jack’ codificándolo y llamando a model.predict_classes() para obtener la salida entera de la palabra predicha. Esto luego se busca en el mapeo de vocabulario para dar la palabra asociada.
# evaluar in_text = 'Jack' print(in_text) encoded = tokenizer.texts_to_sequences([in_text])[0] encoded = array(encoded) yhat = model.predict_classes(encoded, verbose=0) for word, index in tokenizer.word_index.items(): if index == yhat: print(word)
Este proceso podría repetirse varias veces para crear una secuencia de palabras generada. Para hacer esto más fácil, envolvemos el comportamiento en una función que podemos llamar pasando nuestro modelo y la palabra semilla.
# generar una secuencia a partir del modelo
def generate_seq(model, tokenizer, seed_text, n_words):
in_text, result = seed_text, seed_text
# generar un número fijo de palabras
for _ in range(n_words):
# codificar el texto como un número entero
encoded = tokenizer.texts_to_sequences([in_text])[0]
encoded = array(encoded)
# Predecir una palabra en el vocabulario
yhat = model.predict_classes(encoded, verbose=0)
# mapa predicho palabra a palabra
out_word = ''
for word, index in tokenizer.word_index.items():
if index == yhat:
out_word = word
break
# añadir a la entrada
in_text, result = out_word, result + ' ' + out_word
return result
Podemos unir todo esto. La lista completa de códigos se proporciona a continuación.
from numpy import array
from keras.preprocessing.text import Tokenizer
from keras.utils import to_categorical
from keras.utils.vis_utils import plot_model
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import LSTM
from keras.layers import Embedding
#generar una secuencia a partir del modelo
def generate_seq(model, tokenizer, seed_text, n_words):
in_text, result = seed_text, seed_text
# generar un número fijo de palabras
for _ in range(n_words):
# codificar el texto como un número entero
encoded = tokenizer.texts_to_sequences([in_text])[0]
encoded = array(encoded)
# Predecir una palabra en el vocabulario
yhat = model.predict_classes(encoded, verbose=0)
# Mapa predicho palabra a palabra
out_word = ''
for word, index in tokenizer.word_index.items():
if index == yhat:
out_word = word
break
# añadir a la entrada
in_text, result = out_word, result + ' ' + out_word
return result
# definir el modelo
def define_model(vocab_size):
model = Sequential()
model.add(Embedding(vocab_size, 10, input_length=1))
model.add(LSTM(50))
model.add(Dense(vocab_size, activation='softmax'))
# compilar red
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
# resumen del modelo definido
model.summary()
plot_model(model, to_file='model.png', show_shapes=True)
return model
# texto fuente
data = """ Jack and Jill went up the hill\n
To fetch a pail of water\n
Jack fell down and broke his crown\n
And Jill came tumbling after\n """
# enteros codifican el texto
tokenizer = Tokenizer()
tokenizer.fit_on_texts([data])
encoded = tokenizer.texts_to_sequences([data])[0]
# determinar el tamaño del vocabulario
vocab_size = len(tokenizer.word_index) + 1
print('Tamaño del vocabulario: %d' % vocab_size)
# crear palabra -> secuencias de palabras
sequences = list()
for i in range(1, len(encoded)):
sequence = encoded[i-1:i+1]
sequences.append(sequence)
print('Secuencias totales: %d' % len(sequences))
# dividido en elementos X e Y
sequences = array(sequences)
X, y = sequences[:,0],sequences[:,1]
# una salida de codificación en caliente
y = to_categorical(y, num_classes=vocab_size)
# definir el modelo
model = define_model(vocab_size)
# red de ajuste
model.fit(X, y, epochs=500, verbose=2)
# evaluacion
print(generate_seq(model, tokenizer, 'Jack', 6))
Al ejecutar el ejemplo se imprime la pérdida y la precisión de cada época de entrenamiento.
... Epoch 496/500 0s - loss: 0.2358 - acc: 0.8750 Epoch 497/500 0s - loss: 0.2355 - acc: 0.8750 Epoch 498/500 0s - loss: 0.2352 - acc: 0.8750 Epoch 499/500 0s - loss: 0.2349 - acc: 0.8750 Epoch 500/500 0s - loss: 0.2346 - acc: 0.8750
Podemos ver que el modelo no memoriza las secuencias fuente, probablemente porque hay cierta ambigüedad en las secuencias de entrada, por ejemplo:
jack => and jack => fell
Y así sucesivamente. Al final de la carrera, se pasa a Jack y se genera una predicción o nueva secuencia. Obtenemos una secuencia razonable como salida que tiene algunos elementos de la fuente.
Jack and jill came tumbling after down
Este es un buen modelo de lenguaje de primer corte, pero no aprovecha al máximo la capacidad del LSTM para manejar secuencias de entrada y desambiguar algunas de las ambiguas secuencias de pares usando un contexto más amplio.
Modelo 2: Secuencia línea por línea
Otro enfoque es dividir el texto fuente línea por línea, y luego dividir cada línea en una serie de palabras que se acumulan. Por ejemplo:
X, y _, _, _, _, _, Jack, and _, _, _, _, Jack, and, Jill _, _, _, Jack, and, Jill, went _, _, Jack, and, Jill, went, up _, Jack, and, Jill, went, up, the Jack, and, Jill, went, up, the, hill
Este enfoque puede permitir que el modelo utilice el contexto de cada línea para ayudar al modelo en aquellos casos en que un simple modelo de entrada y salida de una palabra cree ambigüedad. En este caso, esto viene a costa de predecir palabras a través de las líneas, lo que podría estar bien por ahora si sólo estamos interesados en modelar y generar líneas de texto. Ten en cuenta que en esta representación, necesitaremos un relleno de secuencias para asegurarnos de que cumplen con una entrada de longitud fija. Esto es un requisito cuando se usa Keras. Primero, podemos crear las secuencias de números enteros, línea por línea, usando el Tokenizer que ya encaja en el texto fuente.
#crear secuencias basadas en línea
sequences = list()
for line in data.split('\n'):
encoded = tokenizer.texts_to_sequences([line])[0]
for i in range(1, len(encoded)):
sequence = encoded[:i+1]
sequences.append(sequence)
print('Secuencias totales: %d' % len(sequences))
A continuación, podemos rellenar las secuencias preparadas. Podemos hacer esto usando la función pad_sequences() provista en Keras. Esto implica primero encontrar la secuencia más larga, luego usarla como la longitud por la cual rellenar todas las otras secuencias.
# pad input sequences
max_length = max([len(seq) for seq in sequences])
sequences = pad_sequences(sequences, maxlen=max_length, padding='pre')
print('Longitud Máxima de Secuencia: %d' % max_length)
A continuación, podemos dividir las secuencias en elementos de entrada y salida, como antes.
# dividido en elementos de entrada y salida sequences = array(sequences) X, y = sequences[:,:-1],sequences[:,-1] y = to_categorical(y, num_classes=vocab_size)
El modelo se puede definir como antes, excepto que las secuencias de entrada son ahora más largas que una sola palabra. Específicamente, son de max_length-1, -1 porque cuando calculamos la longitud máxima de secuencias, incluían los elementos de entrada y salida
# definir el modelo def define_model(vocab_size, max_length): model = Sequential() model.add(Embedding(vocab_size, 10, input_length=max_length-1)) model.add(LSTM(50)) model.add(Dense(vocab_size, activation='softmax')) # compilar la red model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy']) # resumen del modelo definido model.summary() plot_model(model, to_file='model.png', show_shapes=True) return model
Podemos usar el modelo para generar nuevas secuencias como antes. La función generate_seq() puede ser actualizada para construir una secuencia de entrada añadiendo predicciones a la lista de palabras de entrada en cada iteración.
# generar una secuencia a partir de un modelo de lenguaje
def generate_seq(model, tokenizer, max_length, seed_text, n_words):
in_text = seed_text
# generar un número fijo de palabras
for _ in range(n_words):
# codificar el texto como un número entero
encoded = tokenizer.texts_to_sequences([in_text])[0]
# secuencias de pre-pad a una longitud fija
encoded = pad_sequences([encoded], maxlen=max_length, padding='pre')
# predecir probabilidades para cada palabra
yhat = model.predict_classes(encoded, verbose=0)
# mapa predicho palabra a palabra
out_word = ''
for word, index in tokenizer.word_index.items():
if index == yhat:
out_word = word
break
# añadir a la entrada
in_text += ' ' + out_word
return in_text
Enlazando todo esto, el ejemplo de código completo se muestra a continuación.
from numpy import array
from keras.preprocessing.text import Tokenizer
from keras.utils import to_categorical
from keras.preprocessing.sequence import pad_sequences
from keras.utils.vis_utils import plot_model
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import LSTM
from keras.layers import Embedding
# generar una secuencia a partir de un modelo de lenguaje
def generate_seq(model, tokenizer, max_length, seed_text, n_words):
in_text = seed_text
# generar un número fijo de palabras
for _ in range(n_words):
# codificar el texto como un número entero
encoded = tokenizer.texts_to_sequences([in_text])[0]
# secuencias de pre-pad a una longitud fija
encoded = pad_sequences([encoded], maxlen=max_length, padding='pre')
# predecir probabilidades para cada palabra
yhat = model.predict_classes(encoded, verbose=0)
# mapa predicho palabra a palabra
out_word = ''
for word, index in tokenizer.word_index.items():
if index == yhat:
out_word = word
break
# añadir a la entrada
in_text += ' ' + out_word
return in_text
# definir el modelo
def define_model(vocab_size, max_length):
model = Sequential()
model.add(Embedding(vocab_size, 10, input_length=max_length-1))
model.add(LSTM(50))
model.add(Dense(vocab_size, activation='softmax'))
# compilar red
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
# resumen del modelo definido
model.summary()
plot_model(model, to_file='model.png', show_shapes=True)
return model
# texto fuente
data = """ Jack and Jill went up the hill\n
To fetch a pail of water\n
Jack fell down and broke his crown\n
And Jill came tumbling after\n """
# preparar el tokenizer en el texto fuente
tokenizer = Tokenizer()
tokenizer.fit_on_texts([data])
# determinar el tamaño del vocabulario
vocab_size = len(tokenizer.word_index) + 1
print('Tamaño del vocabulario: %d' % vocab_size)
# crear secuencias basadas en línea
sequences = list()
for line in data.split('\n'):
encoded = tokenizer.texts_to_sequences([line])[0]
for i in range(1, len(encoded)):
sequence = encoded[:i+1]
sequences.append(sequence)
print('Secuencias totales: %d' % len(sequences))
# secuencias de entrada del pad
max_length = max([len(seq) for seq in sequences])
sequences = pad_sequences(sequences, maxlen=max_length, padding='pre')
print('Longitud Máxima de Secuencia: %d' % max_length)
# dividido en elementos de entrada y salida
sequences = array(sequences)
X, y = sequences[:,:-1],sequences[:,-1]
y = to_categorical(y, num_classes=vocab_size)
# definir modelo
model = define_model(vocab_size, max_length)
# red adecuada
model.fit(X, y, epochs=500, verbose=2)
# evaluar modelo
print(generate_seq(model, tokenizer, max_length-1, 'Jack', 4))
print(generate_seq(model, tokenizer, max_length-1, 'Jill', 4))
Al ejecutar el ejemplo se logra un mejor ajuste en los datos de origen. El contexto añadido ha permitido al modelo desambiguar algunos de los ejemplos. Todavía hay dos líneas de texto que empiezan con “Jack” que pueden ser un problema para la red.
... Epoch 496/500 0s - loss: 0.1039 - acc: 0.9524 Epoch 497/500 0s - loss: 0.1037 - acc: 0.9524 Epoch 498/500 0s - loss: 0.1035 - acc: 0.9524 Epoch 499/500 0s - loss: 0.1033 - acc: 0.9524 Epoch 500/500 0s - loss: 0.1032 - acc: 0.9524
Al final de la ejecución, generamos dos secuencias con diferentes palabras clave: Jack y Jill. La primera línea generada tiene buen aspecto y coincide directamente con el texto fuente. La segunda es un poco extraña. Esto tiene sentido, porque la red sólo vio a Jill dentro de una secuencia de entrada, no al principio de la secuencia, por lo que ha forzado a una salida a usar la palabra Jill, es decir, la última línea de la rima.
Jack fell down and broke Jill jill came tumbling after
Este fue un buen ejemplo de cómo el enmarcado puede resultar en mejores líneas nuevas, pero no en buenas líneas parciales de entrada.
Modelo 3: Secuencia de entrada y salida de dos palabras
Podemos usar un intermediario entre los enfoques de una palabra dentro y de toda la frase dentro y pasar una sub-secuencia de palabras como entrada. Esto proporcionará una compensación entre los dos enmarcados permitiendo que se generen nuevas líneas y que la generación se recoja en la línea media. Usaremos tres palabras como entrada para predecir una palabra como salida. La preparación de las secuencias es muy parecida al primer ejemplo, excepto que con diferentes desplazamientos en las matrices de secuencias de origen, como se indica a continuación:
# codifica 2 palabras -> 1 palabra sequences = list() for i in range(2, len(encoded)): sequence = encoded[i-2:i+1] sequences.append(sequence)
El ejemplo completo se enumera a continuación.
from numpy import array
from keras.preprocessing.text import Tokenizer
from keras.utils import to_categorical
from keras.preprocessing.sequence import pad_sequences
from keras.utils.vis_utils import plot_model
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import LSTM
from keras.layers import Embedding
# generar una secuencia a partir de un modelo de lenguaje
def generate_seq(model, tokenizer, max_length, seed_text, n_words):
in_text = seed_text
# generar un número fijo de palabras
for _ in range(n_words):
# codificar el texto como un número entero
encoded = tokenizer.texts_to_sequences([in_text])[0]
# secuencias de pre-pad a una longitud fija
encoded = pad_sequences([encoded], maxlen=max_length, padding='pre')
# predecir probabilidades para cada palabra
yhat = model.predict_classes(encoded, verbose=0)
# mapa predicho palabra a palabra
out_word = ''
for word, index in tokenizer.word_index.items():
if index == yhat:
out_word = word
break
# añadir a la entrada
in_text += ' ' + out_word
return in_text
# definir el modelo
def define_model(vocab_size, max_length):
model = Sequential()
model.add(Embedding(vocab_size, 10, input_length=max_length-1))
model.add(LSTM(50))
model.add(Dense(vocab_size, activation='softmax'))
# compilar red
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
# resumen del modelo definido
model.summary()
plot_model(model, to_file='model.png', show_shapes=True)
return model
# texto fuente
data = """ Jack and Jill went up the hill\n
To fetch a pail of water\n
Jack fell down and broke his crown\n
And Jill came tumbling after\n """
# enteros codifican secuencias de palabras
tokenizer = Tokenizer()
tokenizer.fit_on_texts([data])
encoded = tokenizer.texts_to_sequences([data])[0]
# recuperar el tamaño del vocabulario
vocab_size = len(tokenizer.word_index) + 1
print('Tamaño del vocabulario: %d' % vocab_size)
# codifica 2 palabras -> 1 palabra
sequences = list()
for i in range(2, len(encoded)):
sequence = encoded[i-2:i+1]
sequences.append(sequence)
print('Secuencias totales: %d' % len(sequences))
# Secuencias de pads
max_length = max([len(seq) for seq in sequences])
sequences = pad_sequences(sequences, maxlen=max_length, padding='pre')
print('Longitud Máxima de Secuencia: %d' % max_length)
# dividido en elementos de entrada y salida
sequences = array(sequences)
X, y = sequences[:,:-1],sequences[:,-1]
y = to_categorical(y, num_classes=vocab_size)
# definir el modelo
model = define_model(vocab_size, max_length)
# red adecuada
model.fit(X, y, epochs=500, verbose=2)
# evaluacion del modelo
print(generate_seq(model, tokenizer, max_length-1, 'Jack and', 5))
print(generate_seq(model, tokenizer, max_length-1, 'And Jill', 3))
print(generate_seq(model, tokenizer, max_length-1, 'fell down', 5))
print(generate_seq(model, tokenizer, max_length-1, 'pail of', 5))
Ejecutando el ejemplo de nuevo se obtiene un buen ajuste en el texto fuente con una precisión de alrededor del 95%.
... Epoch 496/500 0s - loss: 0.0685 - acc: 0.9565 Epoch 497/500 0s - loss: 0.0685 - acc: 0.9565 Epoch 498/500 0s - loss: 0.0684 - acc: 0.9565 Epoch 499/500 0s - loss: 0.0684 - acc: 0.9565 Epoch 500/500 0s - loss: 0.0684 - acc: 0.9565
Observamos cuatro ejemplos de generación, dos casos de inicio de línea y dos de inicio de línea media.
Jack and jill went up the hill And Jill went up the fell down and broke his crown and pail of water jack fell down and
El primer caso de inicio de línea se generó correctamente, pero el segundo no. El segundo caso fue un ejemplo de la cuarta línea, que es ambigua con el contenido de la primera línea. Tal vez una nueva expansión a tres palabras de entrada sería mejor. Los dos ejemplos de generación de líneas intermedias se crearon correctamente y coinciden con el texto fuente.
Podemos ver que la elección de cómo se enmarca el modelo de lenguaje y los requisitos sobre cómo se utilizará el modelo deben ser compatibles. Se requiere un diseño cuidadoso cuando se utilizan modelos de lenguaje en general, tal vez seguido de pruebas puntuales con generación de secuencias para confirmar que se han cumplido los requisitos del modelo.
➡ Continúa aprendiendo de Procesamiento de Lenguaje Natural en nuestro curso: