
Blog
Cómo desarrollar un modelo de lenguaje neural basado en el carácter
Un modelo de lenguaje predice la siguiente palabra en la secuencia basándose en las palabras específicas que le han precedido en la secuencia. También es posible desarrollar modelos de lenguaje a nivel de caracteres utilizando redes neuronales. El beneficio de los modelos de lenguaje basados en caracteres es su pequeño vocabulario y flexibilidad en el manejo de cualquier palabra, puntuación y otra estructura del documento. Esto viene al costo de requerir modelos más grandes que son más lentos de entrenar. Sin embargo, en el campo de los modelos de lenguaje neural, los modelos basados en caracteres ofrecen muchas promesas para un enfoque general, flexible y poderoso del modelado del lenguaje. En el tutorial de hoy, descubrirás cómo desarrollar un modelo de lenguaje neural basado en caracteres. Después de completar este tutorial, tú sabrás:
- Cómo preparar el texto para el modelado de lenguaje basado en caracteres.
- Cómo desarrollar un modelo de lenguaje basado en caracteres utilizando LSTMs.
- Cómo utilizar un modelo de lenguaje basado en caracteres para generar texto.
Vamos a empezar con la lección de hoy.
Descripción general del tutorial
Este tutorial está dividido en las siguientes partes:
- Canta una canción de seis peniques
- Preparación de datos
- Modelo de entrenamiento de idiomas
- Generar texto
Canta una canción de seis peniques
La canción infantil “Canta una canción de seis peniques” es bien conocida en Occidente. El primer verso es común, pero también hay una versión de cuatro versos que usaremos para desarrollar nuestro modelo de lenguaje basado en el carácter. Es corto, así que el ajuste del modelo será rápido, pero no tan corto como para que no veamos nada interesante. La versión completa de cuatro versículos que usaremos como texto fuente está listada abajo.
Sing a song of sixpence, A pocket full of rye. Four and twenty blackbirds, Baked in a pie. When the pie was opened The birds began to sing; Wasn't that a dainty dish, To set before the king. The king was in his counting house, Counting out his money; The queen was in the parlour, Eating bread and honey. The maid was in the garden, Hanging out the clothes, When down came a blackbird And pecked off her nose.
Copia el texto y guárdelo en un nuevo archivo en su directorio de trabajo actual con el nombre de archivo rhyme.txt.
Preparación de datos
El primer paso es preparar los datos del texto. Empezaremos por definir el tipo de modelo lingüístico.
Diseño de Modelos de Lenguaje
Un modelo de lenguaje debe ser entrenado en el texto, y en el caso de un modelo de lenguaje basado en caracteres, las secuencias de entrada y salida deben ser caracteres. El número de caracteres utilizados como entrada también definirá el número de caracteres que será necesario proporcionar al modelo para obtener el primer carácter previsto. Una vez generado el primer carácter, puede añadirse a la secuencia de entrada y utilizarse como entrada para que el modelo genere el siguiente carácter.
Las secuencias más largas ofrecen más contexto para que el modelo aprenda qué carácter producir a continuación, pero tardan más en entrenarse e imponen más carga al sembrar el modelo al generar el texto. Usaremos una longitud arbitraria de 10 caracteres para este modelo. No hay mucho texto, y 10 caracteres son unas pocas palabras. Ahora podemos transformar el texto crudo en una forma que nuestro modelo pueda aprender; específicamente, secuencias de entrada y salida de caracteres.
Cargar texto
Debemos cargar el texto en la memoria para poder trabajar con él. Abajo hay una función llamada load_doc() que cargará un archivo de texto con un nombre de archivo y devolverá el texto cargado.
# carga doc en la memoria def load_doc(filename): # abrir el archivo como de sólo lectura file = open(filename, 'r') # leer todo el texto text = file.read() # cerrar el archivo file.close() return text
Podemos llamar a esta función con el nombre del archivo de la canción infantil rhyme.txt para cargar el texto en la memoria. El contenido del archivo se imprime a continuación en pantalla como un “control de sanidad”.
# cargar texto
raw_text = load_doc('rhyme.txt')
print(raw_text)
Limpiar texto
A continuación, tenemos que limpiar el texto cargado. No le haremos mucho en este ejemplo. Específicamente, despojaremos a todos los nuevos caracteres de línea de modo que tengamos una larga secuencia de caracteres separados sólo por un espacio en blanco.
# limpiar tokens = raw_text.split() raw_text = ' '.join(tokens)
Es posible que desees explorar otros métodos para la limpieza de datos, como normalizar el caso a minúsculas o eliminar la puntuación en un esfuerzo por reducir el tamaño del vocabulario final y desarrollar un modelo más pequeño y delgado.
Crear secuencias
Ahora que tenemos una larga lista de personajes, podemos crear nuestras secuencias input-output utilizadas para entrenar el modelo. Cada secuencia de entrada tendrá 10 caracteres con un carácter de salida, por lo que cada secuencia tendrá 11 caracteres. Podemos crear las secuencias enumerando los caracteres en el texto, empezando por el undécimo carácter en el índice 10.
# organizarse en secuencias de personajes
length = 10
sequences = list()
for i in range(length, len(raw_text)):
# seleccionar secuencia de tokens
seq = raw_text[i-length:i+1]
# tienda
sequences.append(seq)
print('Secuencias totales: %d' % len(sequences))
Ejecutando este fragmento, podemos ver que terminamos con poco menos de 400 secuencias de caracteres para la formación de nuestro modelo lingüístico.
Secuencias totales: 399
Guardar secuencias
Finalmente, podemos guardar los datos preparados en un archivo para poder cargarlos más tarde cuando desarrollemos nuestro modelo. Abajo hay una función save_doc() que, dada una lista de cadenas y un nombre de archivo, guardará las cadenas en un archivo, una por línea.
# guardar tokens en un archivo, un diálogo por línea def save_doc(lines, filename): data = '\n'.join(lines) file = open(filename, 'w') file.write(data) file.close()
Podemos llamar a esta función y guardar nuestras secuencias preparadas en el nombre de archivo char_sequences.txt en nuestro directorio de trabajo actual.
# guardar secuencias en un archivo out_filename = 'char_sequences.txt' save_doc(sequences, out_filename)
Ejemplo completo
Enlazando todo esto, el listado completo de códigos se proporciona a continuación.
# carga doc en la memoria
def load_doc(filename):
# abrir el archivo como de sólo lectura
file = open(filename, 'r')
# leer todo el texto
text = file.read()
# cerrar el archivo
file.close()
return text
# guardar tokens en un archivo, un diálogo por línea
def save_doc(lines, filename):
data = '\n'.join(lines)
file = open(filename, 'w')
file.write(data)
file.close()
# cargar texto
raw_text = load_doc('rhyme.txt')
print(raw_text)
# Limpiar
tokens = raw_text.split()
raw_text = ' '.join(tokens)
# organizarse en secuencias de personajes
length = 10
sequences = list()
for i in range(length, len(raw_text)):
# seleccionar secuencia de tokens
seq = raw_text[i-length:i+1]
# tienda
sequences.append(seq)
print('Secuencias totales: %d' % len(sequences))
# guardar secuencias en un archivo
out_filename = 'char_sequences.txt'
save_doc(sequences, out_filename)
Ejecute el ejemplo para crear el archivo char_sequences.txt. Echa un vistazo al interior, verás algo como lo siguiente:
Sing a song ing a song ng a song o g a song of a song of a song of s song of si song of six ong of sixp ng of sixpe ...
Ahora estamos listos para entrenar nuestro modelo de lenguaje neural basado en el carácter.
Modelo de entrenamiento de idiomas
En esta sección, desarrollaremos un modelo de lenguaje neural para los datos de secuencia preparados. El modelo leerá los caracteres codificados y predecirá el siguiente carácter de la secuencia. Se utilizará una capa oculta de red neuronal recurrente de la Memoria a Corto Plazo a Largo Plazo para aprender el contexto de la secuencia de entrada con el fin de hacer las predicciones.
Cargar datos
El primer paso es cargar los datos de secuencia de caracteres preparados desde char_sequences.txt. Podemos utilizar la misma función load_doc() desarrollada en la sección anterior. Una vez cargado, dividimos el texto por una nueva línea para dar una lista de secuencias listas para ser codificadas.
# carga doc en la memoria
def load_doc(filename):
# abrir el archivo como de sólo lectura
file = open(filename, 'r')
# leer todo el texto
text = file.read()
# cerrar el archivo
file.close()
return text
# carga
in_filename = 'char_sequences.txt'
raw_text = load_doc(in_filename)
lines = raw_text.split('\n')
Codificar secuencias
Las secuencias de caracteres deben codificarse como números enteros. Esto significa que a cada carácter único se le asignará un valor entero específico y cada secuencia de caracteres se codificará como una secuencia de números enteros. Podemos crear el mapeo con un conjunto ordenado de caracteres únicos en los datos de entrada brutos. El mapeo es un diccionario de valores de caracteres a valores enteros.
chars = sorted(list(set(raw_text))) mapping = dict((c, i) for i, c in enumerate(chars))
A continuación, podemos procesar cada secuencia de caracteres de uno en uno y usar el mapeo del diccionario para buscar el valor entero de cada carácter.
sequences = list() for line in lines: # línea entera de codificación encoded_seq = [mapping[char] for char in line] # tienda sequences.append(encoded_seq)
El resultado es una lista de listas enteras. Necesitamos saber el tamaño del vocabulario más tarde. Podemos recuperar esto como el tamaño de la asignación del diccionario.
# tamaño del vocabulario
vocab_size = len(mapping)
print('Tamaño del vocabulario: %d' % vocab_size)
Al ejecutar esta pieza, podemos ver que hay 38 caracteres únicos en los datos de la secuencia de entrada.
Tamaño del vocabulario: 38
Entradas y salidas divididas
Ahora que las secuencias han sido codificadas en números enteros, podemos separar las columnas en secuencias de entrada y salida de caracteres. Podemos hacer esto usando una simple rebanada de array.
sequences = array(sequences) X, y = sequences[:,:-1], sequences[:,-1]
A continuación, necesitamos una codificación en caliente para cada carácter. Es decir, cada carácter se convierte en un vector tan largo como el vocabulario (38 elementos) con un 1 marcado para el carácter específico. Esto proporciona una representación de entrada más precisa para la red. También proporciona un objetivo claro para que la red pueda predecir, donde una distribución de probabilidad sobre caracteres puede ser producida por el modelo y comparada con el caso ideal de todos los valores 0 con un 1 para el siguiente carácter real. Podemos usar la función to_categorical() en la API de Keras para codificar en caliente las secuencias de entrada y salida.
sequences = [to_categorical(x, num_classes=vocab_size) for x in X] X = array(sequences) y = to_categorical(y, num_classes=vocab_size)
Ahora estamos listos para adaptarnos al modelo.
Modelo de ajuste
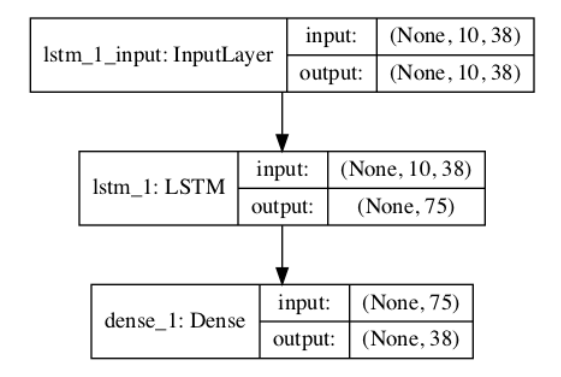
El modelo se define con una capa de entrada que toma secuencias que tienen 10 pasos de tiempo y 38 características para las secuencias de entrada codificadas en caliente. En lugar de especificar estos números, usamos la segunda y tercera dimensión en los datos de entrada X. Esto es así porque si cambiamos la longitud de las secuencias o el tamaño del vocabulario, no necesitamos cambiar la definición del modelo. El modelo tiene una sola capa oculta de LSTM con 75 celdas de memoria, elegidas con un pequeño ensayo y error. El modelo tiene una capa de salida totalmente conectada que produce un vector con una distribución de probabilidad entre todos los caracteres del vocabulario. Una función de activación softmax se utiliza en la capa de salida para asegurar que la salida tiene las propiedades de una distribución de probabilidad.
# definir el modelo def define_model(X): model = Sequential() model.add(LSTM(75, input_shape=(X.shape[1], X.shape[2]))) model.add(Dense(vocab_size, activation='softmax')) # compilar el modelo model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy']) # resumen del modelo definido model.summary() plot_model(model, to_file='model.png', show_shapes=True) return model
El modelo está aprendiendo un problema de clasificación multiclase, por lo tanto usamos la pérdida de registro categórica prevista para este tipo de problema. La eficiente implementación de Adam del descenso en pendiente se utiliza para optimizar el modelo y la precisión se informa al final de cada actualización de lote. El modelo es apto para 100 épocas de entrenamiento, otra vez encontradas con un poco de ensayo y error. Ejecutando esto se imprime un resumen de la red definida como un “chequeo de sanidad”.
_________________________________________________________________ Layer (type) Output Shape Param # ================================================================= lstm_1 (LSTM) (None, 75) 34200 _________________________________________________________________ dense_1 (Dense) (None, 38) 2888 ================================================================= Total params: 37,088 Trainable params: 37,088 Non-trainable params: 0 _________________________________________________________________
Un gráfico del modelo definido se guarda en un archivo con el nombre model.png.
Guardar modelo
Después de ajustar el modelo, lo guardamos en un archivo para su uso posterior. La API de modelos de Keras proporciona la función save() que podemos usar para guardar el modelo en un solo archivo, incluyendo información de pesos y topología.
# guardar el modelo en un archivo
model.save('model.h5')
También guardamos el mapeo de caracteres a enteros que necesitaremos para codificar cualquier entrada cuando usemos el modelo y decodificar cualquier salida del modelo.
# Guardar el mapeo
dump(mapping, open('mapping.pkl', 'wb'))
Ejemplo Completo
Enlazando todo esto, el listado completo de códigos para ajustar el modelo de lenguaje neural basado en caracteres se enumera a continuación.
from numpy import array
from pickle import dump
from keras.utils import to_categorical
from keras.utils.vis_utils import plot_model
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import LSTM
# cargar doc en la memoria
def load_doc(filename):
# abrir archivo en modo solo lectura
file = open(filename, 'r')
# leer todo el texto
text = file.read()
# cerrar el archivo
file.close()
return text
# definir el modelo
def define_model(X):
model = Sequential()
model.add(LSTM(75, input_shape=(X.shape[1], X.shape[2])))
model.add(Dense(vocab_size, activation='softmax'))
# compilar modelo
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
# resumen del modelo definido
model.summary()
plot_model(model, to_file='model.png', show_shapes=True)
return model
# cargar
in_filename = 'char_sequences.txt'
raw_text = load_doc(in_filename)
lines = raw_text.split('\n')
# enteros codifican secuencias de caracteres
chars = sorted(list(set(raw_text)))
mapping = dict((c, i) for i, c in enumerate(chars))
sequences = list()
for line in lines:
# línea entera de codificación
encoded_seq = [mapping[char] for char in line]
# almacenar
sequences.append(encoded_seq)
# tamaño del vocabulario
vocab_size = len(mapping)
print('Tamaño del vocabulario: %d' % vocab_size)
# separar en entrada y salida
sequences = array(sequences)
X, y = sequences[:,:-1], sequences[:,-1]
sequences = [to_categorical(x, num_classes=vocab_size) for x in X]
X = array(sequences)
# modelo adecuado
y = to_categorical(y, num_classes=vocab_size)
# definir modelo
model = define_model(X)
# Guardar el mapeo
model.fit(X, y, epochs=100, verbose=2)
# guardar el modelo en el archivo
model.save('model.h5')
dump(mapping, open('mapping.pkl', 'wb'))
Ejecutar el ejemplo puede llevar un minuto. Verás que el modelo aprende bien el problema, quizás demasiado bien para generar secuencias sorprendentes de caracteres.
... Epoch 96/100 0s - loss: 0.2193 - acc: 0.9950 Epoch 97/100 0s - loss: 0.2124 - acc: 0.9950 Epoch 98/100 0s - loss: 0.2054 - acc: 0.9950 Epoch 99/100 0s - loss: 0.1982 - acc: 0.9950 Epoch 100/100 0s - loss: 0.1910 - acc: 0.9950
Al final de la ejecución, tendrá dos archivos guardados en el directorio de trabajo actual, específicamente model.h5 y mapping.pkl. A continuación, podemos considerar el uso del modelo aprendido.
Generar texto
Utilizaremos el modelo del lenguaje aprendido para generar nuevas secuencias de texto que tengan las mismas propiedades estadísticas.
Cargar modelo
El primer paso es cargar el modelo guardado en el archivo model.h5. Podemos usar la función load_model() de la API de Keras.
# cargar el modelo
model = load_model('model.h5')
También necesitamos cargar el diccionario encurtido para mapear caracteres a enteros desde el archivo mapping.pkl. Usaremos la API de Pickle para cargar el objeto.
# cargar el mapeo
mapping = load(open('mapping.pkl', 'rb'))
Ahora estamos listos para usar el modelo cargado.
Generar caracteres
Debemos proporcionar secuencias de 10 caracteres como entrada al modelo para iniciar el proceso de generación. Los recogeremos manualmente. Será necesario preparar una secuencia de entrada determinada de la misma manera que se preparan los datos de capacitación para el modelo. Primero, la secuencia de caracteres debe estar codificada en números enteros usando el mapeo cargado.
# codificar los caracteres como enteros encoded = [mapping[char] for char in in_text]
A continuación, los números enteros deben ser codificados en caliente usando la función to_categorical() Keras.
# una codificacion caliente encoded = to_categorical(encoded, num_classes=len(mapping))
Entonces podemos usar el modelo para predecir el siguiente carácter de la secuencia. Usamos predict _classes() en lugar de predict() para seleccionar directamente el entero para el carácter con la probabilidad más alta en lugar de obtener la distribución de probabilidad completa a través de todo el conjunto de caracteres.
# Predecir el carácter yhat = model.predict_classes(encoded, verbose=0)
Entonces podemos decodificar este número entero buscando en el mapeo para ver el carácter al cual se mapea.
out_char = '' for char, index in mapping.items(): if index == yhat: out_char = char break
Este carácter se puede añadir a la secuencia de entrada. Entonces necesitamos asegurarnos de que la secuencia de entrada sea de 10 caracteres truncando el primer carácter del texto de la secuencia de entrada. Podemos usar la función pad_sequences() de la API de Keras que puede realizar esta operación de truncamiento. Juntando todo esto, podemos definir una nueva función llamada generate_seq() para usar el modelo cargado para generar nuevas secuencias de texto.
# generar una secuencia de caracteres con un modelo de lenguaje def generate_seq(model, mapping, seq_length, seed_text, n_chars): in_text = seed_text # generar un número fijo de caracteres for _ in range(n_chars): # codificar los caracteres como enteros encoded = [mapping[char] for char in in_text] # cortar secuencias a una longitud fija encoded = pad_sequences([encoded], maxlen=seq_length, truncating='pre') # una codificacion caliente encoded = to_categorical(encoded, num_classes=len(mapping)) # Predecir el carácter yhat = model.predict_classes(encoded, verbose=0) # invierte un número entero del mapa a un carácter out_char = '' for char, index in mapping.items(): if index == yhat: out_char = char break # añadir a la entrada in_text += char return in_text
Ejemplo completo
Enlazando todo esto, el ejemplo completo para generar texto usando el modelo de lenguaje neural adecuado se enumera a continuación.
from pickle import load
from numpy import array
from keras.models import load_model
from keras.utils import to_categorical
from keras.preprocessing.sequence import pad_sequences
# generar una secuencia de caracteres con un modelo de lenguaje
def generate_seq(model, mapping, seq_length, seed_text, n_chars):
in_text = seed_text
# generar un número fijo de caracteres
for _ in range(n_chars):
# codificar los caracteres como enteros
encoded = [mapping[char] for char in in_text]
# cortar secuencias a una longitud fija
encoded = pad_sequences([encoded], maxlen=seq_length, truncating='pre')
# una codificacion caliente
encoded = to_categorical(encoded, num_classes=len(mapping))
# Predecir el carácter
yhat = model.predict_classes(encoded, verbose=0)
# invierte un número entero del mapa a un carácter
out_char = ''
for char, index in mapping.items():
if index == yhat:
out_char = char
break
# añadir a la entrada
in_text += char
return in_text
# cargar el modelo
model = load_model('model.h5')
# cargar el mapeo
mapping = load(open('mapping.pkl', 'rb'))
# Poniendo a prueba el comienzo de la rima
print(generate_seq(model, mapping, 10, 'Sing a son', 20))
# prueba en la línea media
print(generate_seq(model, mapping, 10, 'king was i', 20))
# prueba no en el original
print(generate_seq(model, mapping, 10, 'hello worl', 20))
Al ejecutar el ejemplo se generan tres secuencias de texto. La primera es una prueba para ver cómo le va al modelo desde el principio de la rima. La segunda es una prueba para ver qué tan bien lo hace al principio en la mitad de una línea. El último ejemplo es una prueba para ver qué tan bien lo hace con una secuencia de caracteres nunca antes vista.
Sing a song of sixpence, A poc king was in his counting house hello worls e pake wofey. The
Podemos ver que el modelo funcionó muy bien con los dos primeros ejemplos, como cabría esperar. También podemos ver que el modelo todavía generó algo para el nuevo texto, pero no tiene sentido.
➡ Aprende mucho mas con nosotros en el curso de Procesamiento de Lenguaje Natural: