
Blog
Web scraping con Beautiful Soup III
Afianzar conceptos de web scrapping
Proporcionar otro ejemplo con una clara aplicación
En esta lección, le mostraremos cómo realizar el web scraping con Python y la biblioteca BeautifulSoup. Recogeremos los pronósticos meteorológicos del Servicio Meteorológico Nacional y luego los presentaremos utilizando la biblioteca Pandas.
Los componentes de la página web
Cuando visitamos una página web, nuestro navegador web realiza una solicitud a un servidor web. Esta solicitud se llama una solicitud GET, ya que estamos recibiendo archivos del servidor. El servidor luego envía los archivos que le indican a nuestro navegador cómo representar la página para nosotros. Los archivos se dividen en algunos tipos principales:
- HTML: contiene el contenido principal de la página.
- CSS: agrega estilo para que la página se vea mejor.
- JS: Los archivos Javascript agregan interactividad a las páginas web.
- Imágenes: los formatos de imagen, como JPG y PNG permiten que las páginas web muestren imágenes.
Después de que nuestro navegador recibe todos los archivos, muestra la página web. Cuando realizamos el web scraping, nos interesa el contenido principal de la página web, por lo que nos fijamos en el HTML.
HTML
El lenguaje de marcado de hipertexto (HTML) es un lenguaje con el que se crean páginas web. HTML no es un lenguaje de programación, como Python, sino que es un lenguaje de marcado que le dice a un navegador cómo diseñar el contenido.
Hagamos un recorrido rápido a través de HTML para que sepamos lo suficiente como para hacer web scraping. HTML consiste en elementos llamados etiquetas. La etiqueta más básica es la etiqueta <html>. Justo dentro de una etiqueta html, ponemos otras dos etiquetas, la etiqueta de la cabeza (head) y la etiqueta del cuerpo (body). El contenido principal de la página web va en la etiqueta del cuerpo. La etiqueta del encabezado contiene datos sobre el título de la página, y otra información:
<html> <head> </head> <body> </body> </html>
Ahora agregaremos nuestro primer contenido a la página, en la forma de la etiqueta p. La etiqueta p define un párrafo, y cualquier texto dentro de la etiqueta se muestra como un párrafo separado:
<html> <head> </head> <body> <p> ¡Aquí tenemos el 1º párrafo! </p> <p> ¡Aquí tenemos el 2º párrafo! </p> </body> </html>
Así es como se verá este código en una web:
¡Aquí tenemos el 1º párrafo!
¡Aquí tenemos el 2º párrafo!
Las etiquetas tienen nombres comúnmente usados que dependen de su posición en relación con otras etiquetas:
- child: (hijo) es una etiqueta dentro de otra etiqueta. Así que las dos etiquetas p anteriores son ambas de los child de la etiqueta del body.
- parent: (padre) es la etiqueta dentro de otra etiqueta. Arriba, la etiqueta html es la principal de la etiqueta del body.
- sibling: (hermano) es una etiqueta que está anidada dentro de la misma matriz principal que otra etiqueta. Por ejemplo, el head y el body son hermanos, ya que ambos están dentro de html. Ambas etiquetas p son hermanos, ya que están dentro del cuerpo (body).
También podemos agregar propiedades a las etiquetas HTML que cambian su comportamiento:
<html> <head> </head> <body> <p> Paragrafo texto 1 <a href="https://unipython.com">Aprender Python</a> </p> <p> Paragrafo texto 2 </body> </html>
En el ejemplo anterior, agregamos dos etiquetas a. Las etiquetas son enlaces, y le dicen al navegador que haga un enlace a otra página web. La propiedad href de la etiqueta determina dónde va el enlace.
a y p son etiquetas html extremadamente comunes. Aquí hay algunos otros:
- div – indica una división, o área de la página.
- b – en negrita cualquier texto dentro.
- i – pone en cursiva cualquier texto dentro.
- tabla – crea una tabla.
- formulario – crea un formulario de entrada.
Para una lista completa de etiquetas, mira aquí.
Antes de pasar al scrapeo web real, aprendamos sobre las propiedades de clase e id. Estas propiedades especiales dan nombres a los elementos HTML y hacen que sea más fácil interactuar con ellos cuando estamos scrapeando. Un elemento puede tener varias clases y una clase puede compartirse entre elementos. Cada elemento solo puede tener un ID, y un ID solo se puede usar una vez en una página. Las clases y los identificadores son opcionales, y no todos los elementos los tendrán.
<html> <head> </head> <body> <p class="bold-paragraph"> Aquí tenemos el 1º parrafo! <a href="https://unipython.com/" id="aprender-python">Aprender Programación</a> </p> <p class="bold-paragraph extra-large"> Aquí tenemos el 2º parrafo </p> </body> </html>
Este trozo de código será:
Aquí tenemos el 1º parrafo! Aprender Programación
Aquí tenemos el 2º parrafo!
Empezamos el proyecto “Descargar datos de predicción del tiempo”:
El primer paso es encontrar la página que queremos escrapear. Extraeremos información meteorológica sobre la ciudad de Madrid en esta web.
Objetivo: Extraeremos datos sobre el pronóstico en Madrid.
Como se puede ver en la web, la página contiene información sobre el pronóstico extendido para la próxima semana, incluida la hora del día, la temperatura y una breve descripción de las condiciones.
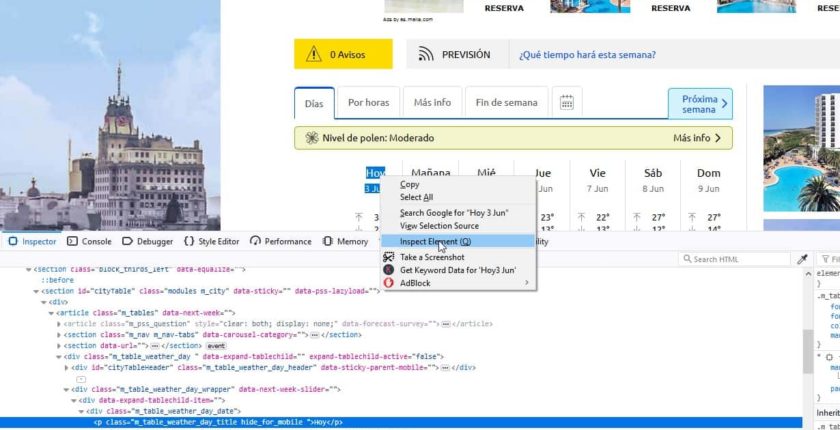
Inspeccionamos la estructura de la página con Chrome (inspeccionar) o con Firefox (inspect element).
Lo primero que debemos hacer es inspeccionar la página con Chrome o Firefox . Si está utilizando otro navegador como Safari u otros tienen equivalentes. Aunque en este ejemplo hemos usado Firefox.
Puede iniciar las herramientas para desarrolladores en firefox selecionando los datos que queremos inspeccionar (en nuestro caso la palabra “hoy”) y haciendo clic con el botón derecho -> Inspect Element (Q) entonces le aparerá el código de la web como en la siguiente imagen: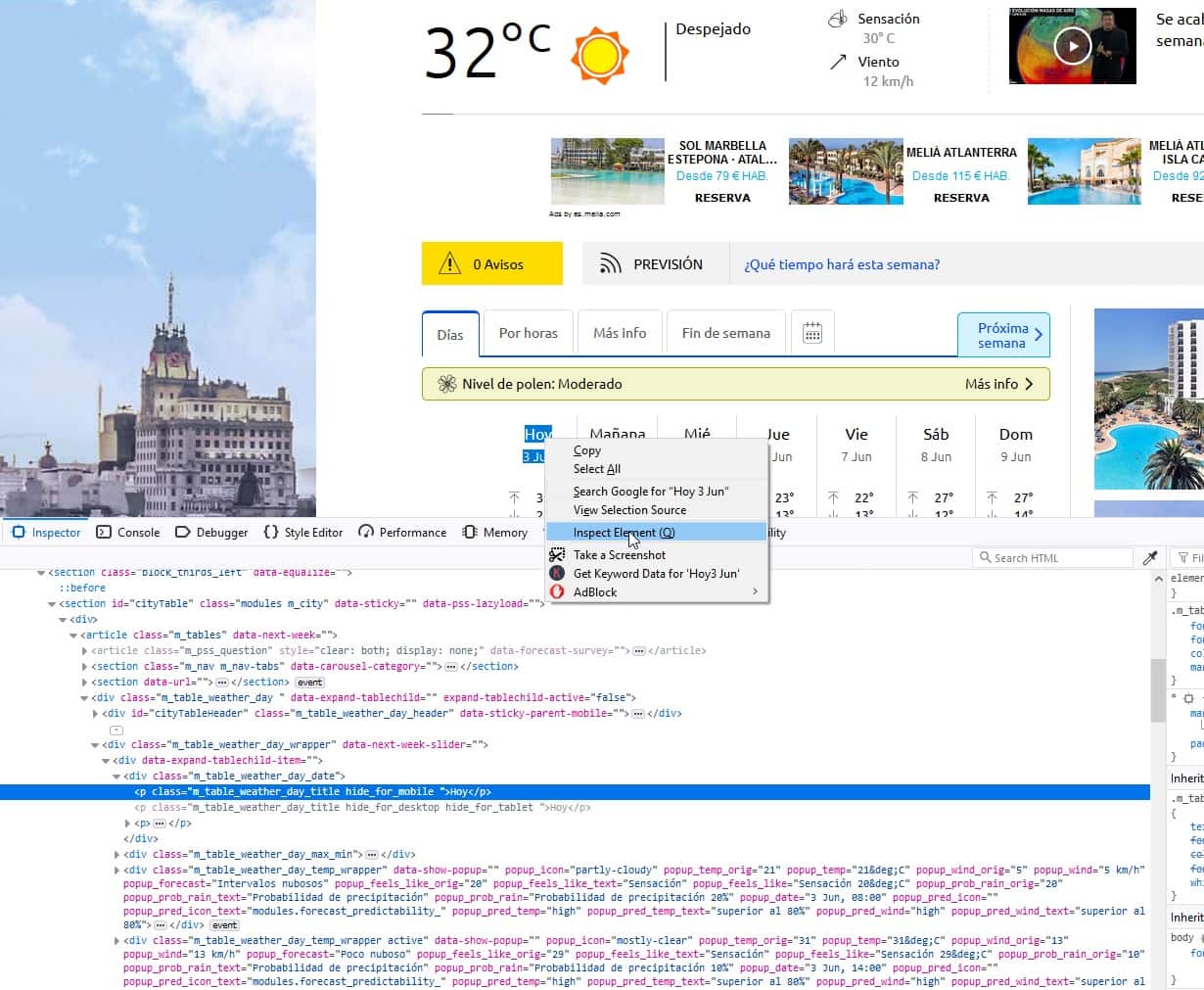
Vemos que esto nos lleva a una línea que comenza por p dentro de una clase.
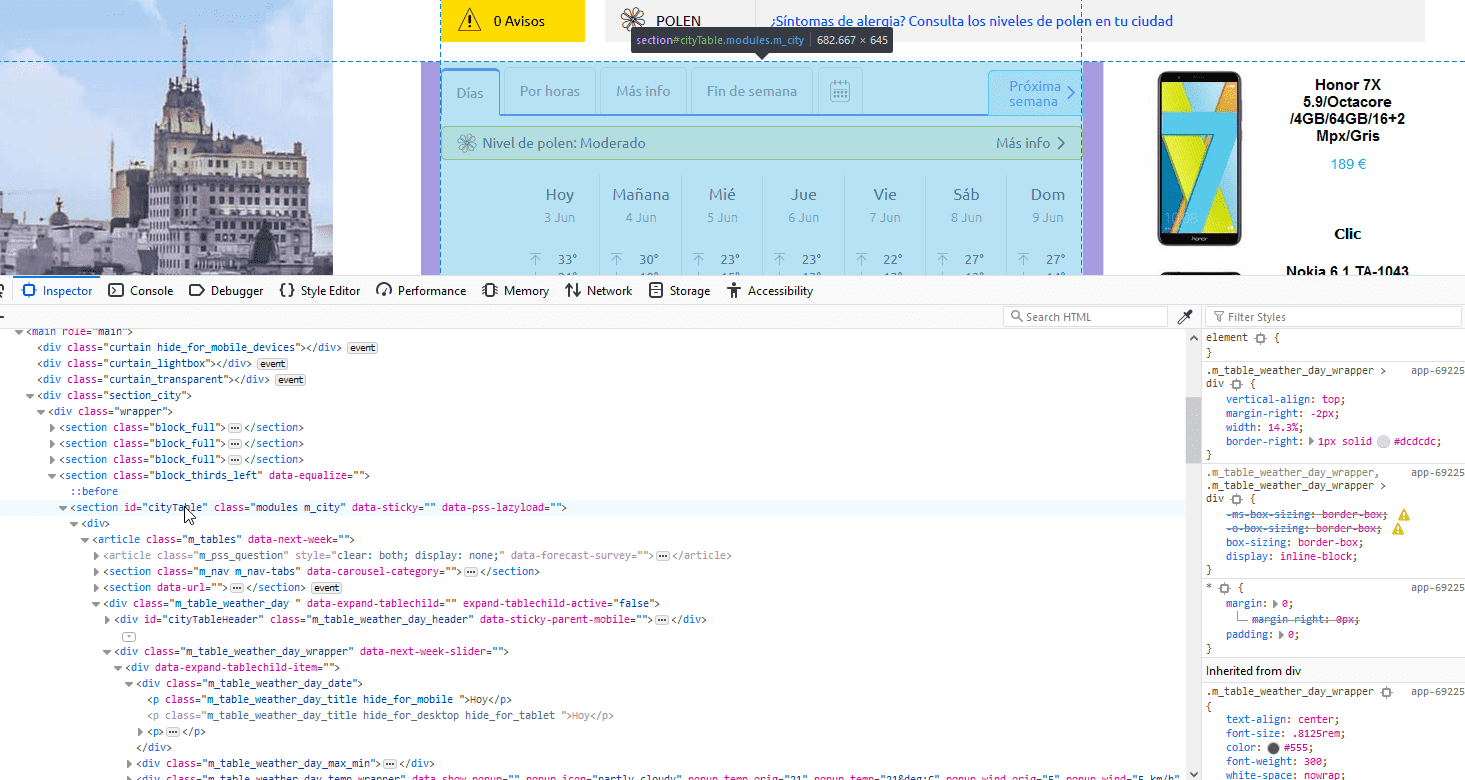 En este caso, es una section con id=”cityTable” y este id contiene los elementos de pronóstico extendido.
En este caso, es una section con id=”cityTable” y este id contiene los elementos de pronóstico extendido.Si hace clic en la consola de su navegador y explora el id, descubrirá que cada elemento del pronóstico está contenido en otros div con el contenedor de cada clase.
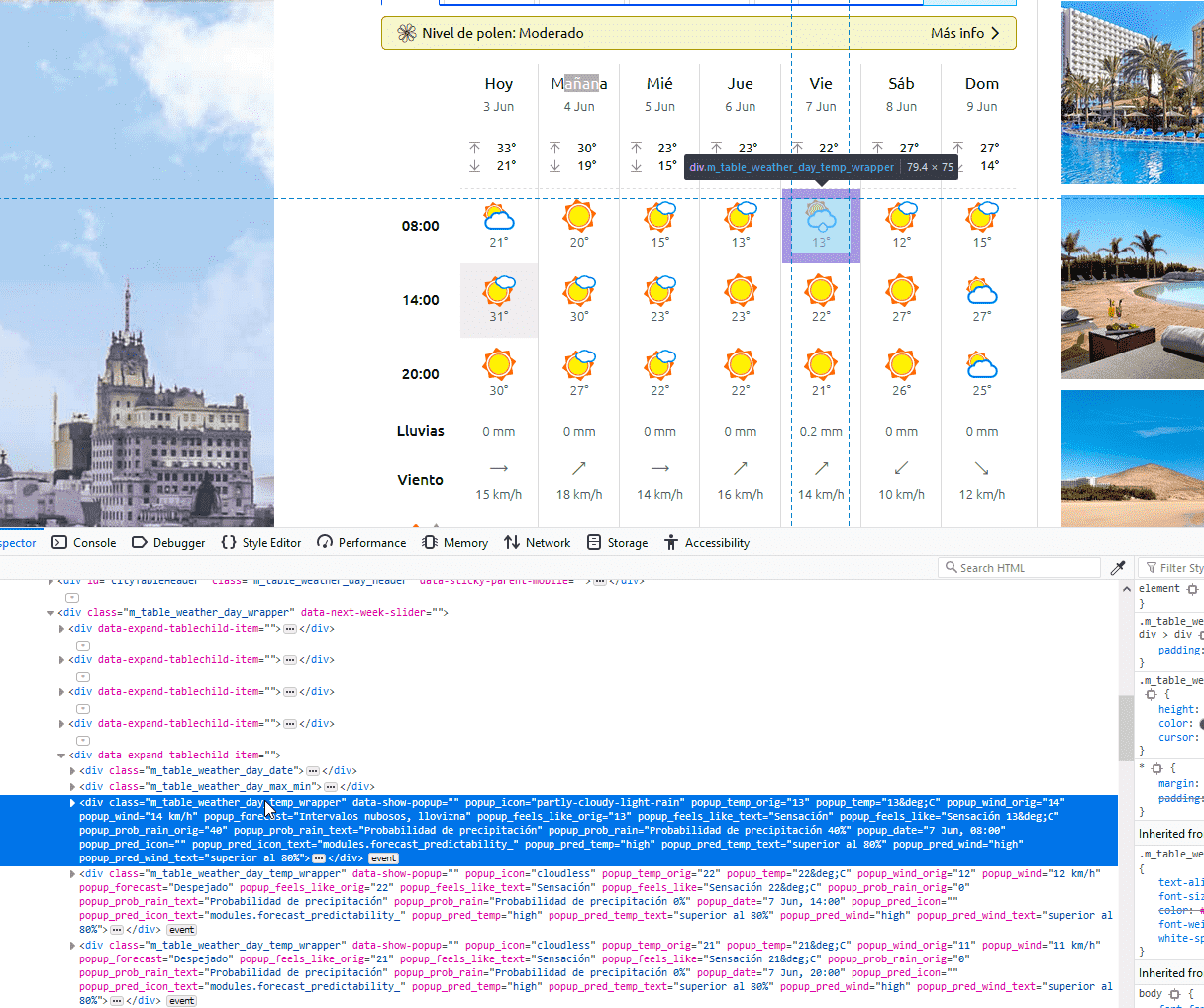
Ahora ya sabemos lo suficiente para scrapear la página y comenzar a analizarla. En el siguiente código haremos lo siguiente:
- Descargamos la página web que contiene el pronóstico.
- Se crea una clase BeautifulSoup para analizar la página.
- Encuentramos el div con id con los siete días de previsión y cityTable.
- Dentro de city, encontramos cada elemento de pronóstico individual dentro de la clase “m_table_weather_day_temp_wrapper”.
- Extraemos e imprimimos el primer artículo de pronóstico.
Lo que aparecerá por pantalla sera todo el contenido de las 3 primeras posiciones que hay en la clase “m_table_weather_day_temp_wrapper”:
from bs4 import BeautifulSoup
import requests
page = requests.get("https://www.eltiempo.es/madrid.html")
soup = BeautifulSoup(page.content, 'html.parser')
city = soup.find(id="cityTable")
semana = city.find_all(class_="m_table_weather_day_temp_wrapper")
dia0= semana[0]
print(dia0.prettify())
dia1= semana[1]
print('*****')
print(dia1.prettify())
dia2= semana[2]
print('*****')
print(dia2.prettify())
dia3= semana[3]
print(dia3.prettify())
Al ejecutar el código por la consola aparece:
<div class=”m_table_weather_day_temp_wrapper”>
08:00
</div>
*****
<div class=”m_table_weather_day_temp_wrapper”>
14:00
</div>
*****
<div class=”m_table_weather_day_temp_wrapper”>
20:00
</div>
<div class=”m_table_weather_day_temp_wrapper” data-show-popup=”” popup_date=”3 Jun, 08:00″ popup_feels_like=”Sensación 20°C” popup_feels_like_orig=”20″ popup_feels_like_text=”Sensación” popup_forecast=”Intervalos nubosos” popup_icon=”partly-cloudy” popup_pred_icon=”” popup_pred_icon_text=”modules.forecast_predictability_” popup_pred_temp=”high” popup_pred_temp_text=”superior al 80%” popup_pred_wind=”high” popup_pred_wind_text=”superior al 80%” popup_prob_rain=”Probabilidad de precipitación 20%” popup_prob_rain_orig=”20″ popup_prob_rain_text=”Probabilidad de precipitación” popup_temp=”21°C” popup_temp_orig=”21″ popup_wind=”5 km/h” popup_wind_orig=”5″>
<i class=”icon_weather_m partly-cloudy”>
</i>
<span>
<span data-temp=”21″ data-temp-include-units=””>
21°
</span>
</span>
</div>
Por lo que podemos entender que las 2 primeras posiciones solo tienen la hora y los datos están a partir de la 3º. En esta 3º posición podemos ver que se encuentran todos los datos que buscamos. Estos datos están en los atributos de la clase “m_table_weather_day_temp_wrapper”. Entonces si extraemos los datos de los atributos de la posición 3º ordenando por fecha, tiempo, viento y lluvia podemos obtener la predicción del tiempo del día:
from bs4 import BeautifulSoup
import requests
import pandas as pd
page = requests.get("https://www.eltiempo.es/madrid.html")
soup = BeautifulSoup(page.content, 'html.parser')
city = soup.find(id="cityTable")
semana = city.find_all(class_="m_table_weather_day_temp_wrapper")
dias= semana[3]
fecha=[dias.attrs['popup_date']]
tiempo=[dias.attrs['popup_forecast'] ]
viento=[dias.attrs['popup_wind']]
lluvia=[dias.attrs['popup_prob_rain']]
print(fecha, tiempo, viento, lluvia)
Si ejecutamos el código nos devuelve los datos de nuestras variables fecha, tiempo, viento y lluvia:
[‘3 Jun, 08:00’] [‘Intervalos nubosos’] [‘5 km/h’] [‘Probabilidad de precipitación 20%’]
Extraer toda la información de la página:
Ahora que sabemos cómo extraer cada pieza individual de información, podemos combinar nuestro conocimiento para extraer todo de una vez.
En el siguiente código, nosotros:
- Seleccionamos todos los elementos con el nombre de la clase m_table_weather_day_temp_wrapper.
- Usamos una lista para llamar al método dias.attrs[‘popup_date’ ,’popup_forecast’ …. ] en cada objeto BeautifulSoup.
semana = city.find_all(class_="m_table_weather_day_temp_wrapper") semana= semana[3:33] fecha=[dias.attrs['popup_date'] for dias in semana]
Combinando nuestros datos con Pandas
Ahora podemos combinar los datos en un DataFrame de Pandas y analizarlos. Un DataFrame es un objeto que puede almacenar datos tabulares, lo que facilita el análisis de los datos.
Para hacer esto, llamaremos a la clase DataFrame y pasaremos a cada lista de elementos que tenemos. Los pasamos como parte de un diccionario. Cada clave del diccionario se convertirá en una columna en el marco de datos, y cada lista se convertirá en los valores de la columna:
from bs4 import BeautifulSoup
import requests
import pandas as pd
page = requests.get("https://www.eltiempo.es/madrid.html")
soup = BeautifulSoup(page.content, 'html.parser')
city = soup.find(id="cityTable")
semana = city.find_all(class_="m_table_weather_day_temp_wrapper")
semana= semana[3:33]
fecha=[dias.attrs['popup_date'] for dias in semana]
tiempo=[dias.attrs['popup_forecast'] for dias in semana]
viento=[dias.attrs['popup_wind'] for dias in semana]
lluvia=[dias.attrs['popup_prob_rain'] for dias in semana]
prediccion = pd.DataFrame({
"fecha": fecha,
"tiempo": tiempo,
"viento": viento,
"lluvia": lluvia})
print(prediccion)
Si ejecutamos este código obtendremos una bonita tabla donde podemos analizar todos los datos scrapeados:
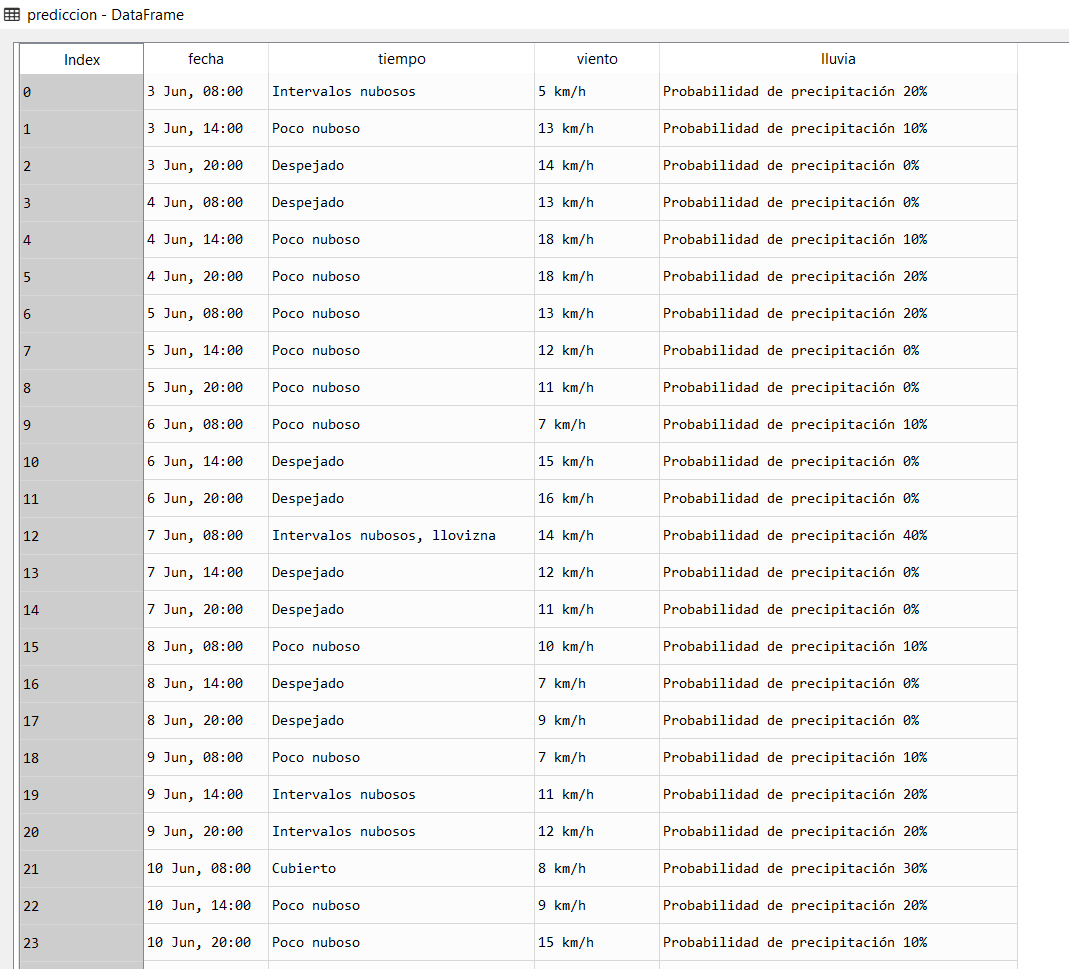
Ahora ya deberíamos tener una buena comprensión de cómo escrapear páginas web para extraer datos funcionales. Un buen paso siguiente sería elegir un sitio e intentar scrapear webs por su cuenta como por ejemplo:
- Precios de criptomonedas
- Precios de acciones de bolsa
- Precios productos
➡ Aprende mucho mas de Web Scraping y Beatiful Soup con nuestro Curso de Web Scraping con Python: