
Blog
Reducción de ruido en imágenes utilizando Autocodificadores
Objectivos:
- Entender el principio básico de funcionamiento de una red neuronal artificial
- Entender el tipo de redes neuronales artificiales denominadas Autocodificadores
- Utilizar Autocodificadores para disminuir el ruido en imágenes
Los Autocodificadores (Autoencoders en inglés) son un tipo especial de red neuronal artificial (ANN por sus siglas en inglés). Es por eso que para entender los autocodificadores es mejor primero tener una idea de cómo funciona una ANN.
Fundamentos básicos de ANN
Las ANN son modelos computacionales inspirados en las redes neuronales biológicas. De manera simplificada una ANN se puede dividir en tres componentes principales: una capa de entrada, varias capas ocultas y una capa de salida (ver Figura 1). El conjunto de todas las capas ocultas puede entenderse como una función que depende de múltiples parámetros a priori desconocidos, denominados pesos de las neuronas. Para encontrar los valores de estos pesos la ANN debe ser entrenada.
Supongamos, por ejemplo, que se quiere entrenar una red para identificar imágenes de dígitos del 0 al 9, escritos a mano -Tal tipo de ANN, esto es, que acepta imágenes en su entrada, se denomina CNN (Convolutional Neural Network en inglés)- Entonces durante el entrenamiento se deberán proporcionar como entrada varias imágenes de los dígitos del 0 al 9, pero también deberá proporcionarse la variable de salida. En este caso la variable de salida corresponderá con un vector indicando que las imágenes del cero corresponden con un cero, las del uno con un uno, y así sucesivamente. Inicialmente, a los pesos se le asignan valores aleatorios. En cada iteración los pesos se van ajustando de tal manera que la predicción a la salida se corresponda con la imagen de entrada. Esto se hace mediante la minimización de cierta función de error que penaliza los fallos y favorece los aciertos, y que se define dependiendo de cada caso particular. De esta manera, en cada iteración la ANN va “aprendiendo” a identificar correctamente las imágenes de los dígitos escritos a mano. Una vez entrenada podremos pasarle una imagen nueva (o sea, una que no haya sido utilizada durante el entrenamiento) y la red devolverá a la salida de qué dígito se trata. Es decir, después de entrenada, la ANN será capaz de reconocer con una alta probabilidad de acierto de qué dígito se trata, aunque nunca lo haya “visto”.
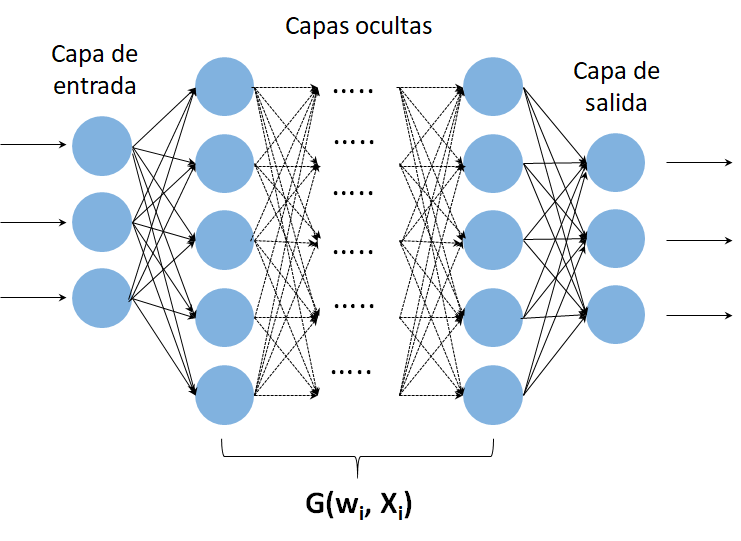
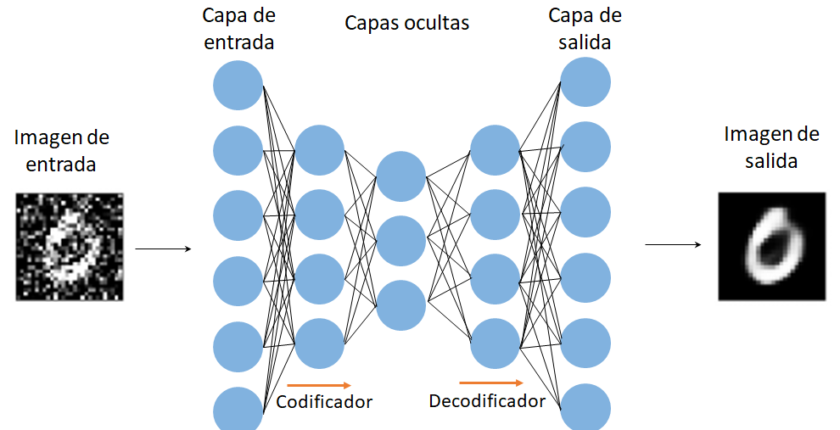
Figura 1: La capa de entrada puede estar compuesta, por ejemplo, por los valores de los píxeles de una imagen. Las capas ocultas pueden entenderse como cierta función G que depende de los pesos wi, los valores de entrada Xi. La función G transforma los valores a la entrada y dependiendo del tipo de ANN puede devolver a la salida otra imagen o la probabilidad de que la imagen en la entrada pertenezca a cierta clase previamente definida.
Para profundizar más en este tema de redes neuronales se recomienda leer el curso en el enlace a continuación (insertar link)
Autocodificadores
Como se ha mencionado anteriormente los autocodificadores son un caso particular de ANN. La particularidad de estos radica en que la entrada suele ser exactamente igual a la salida. Utilizando el ejemplo anterior, si se pasa la imagen de un 0 en la entrada, el Autocodificador devolverá a la salida la imagen de un cero lo más cercana posible a la imagen de la entrada (Fig. 2). En este punto es válido preguntarse: ¿cuál es la utilidad de tal red neuronal? Para responder a esta pregunta debemos entender un poco mejor la arquitectura de los Autocodificadores. La principal diferencia con las redes convencionales es que las capas intermedias (capas ocultas) primero reducen su tamaño (Codificador) y luego vuelven a aumentarlo (Decodificador) de manera simétrica (Fig. 2)
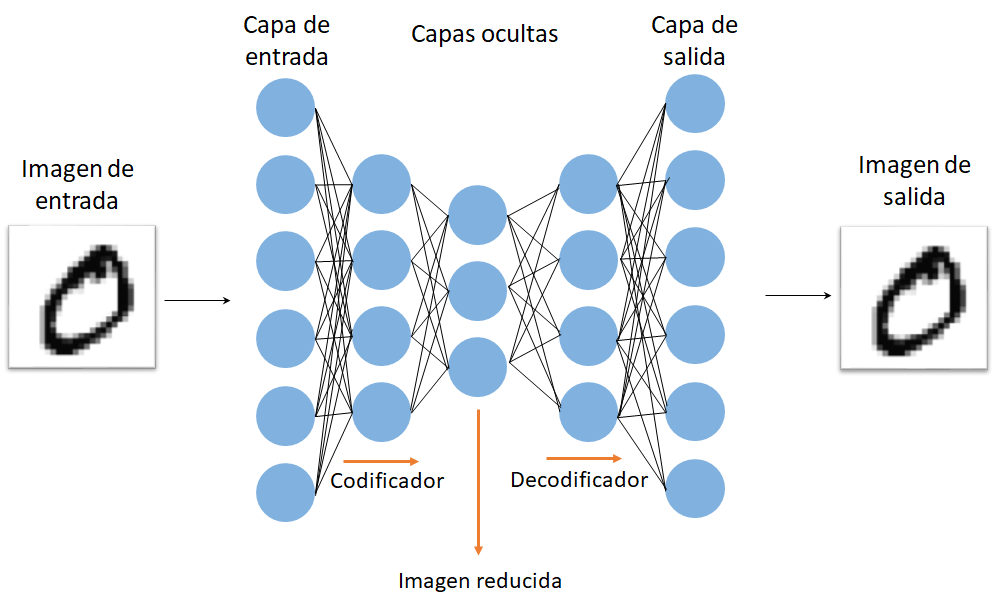
Figura 2: Arquitectura general de un Autocodificador.
Debido a la arquitectura de esta ANN la capa del centro es una representación compacta de las variables de entrada. Así, las capas que conforman el Codificador crearán una versión más compacta de la imagen original, mientras que las capas que conforman el Decodificador intentarán restablecer la imagen original a partir de su versión compacta. Una aplicación interesante de este tipo de algoritmo es en la obtención de imágenes de alta resolución a partir de imágenes con poca resolución. Otra aplicación, fuera del ámbito del procesamiento de imágenes, es en la reducción de dimensiones en problemas donde hay cientos de variables dependientes. En este sentido los Autocodificadores han demostrado ser una técnica alternativa y más robusta que PCA (Análisis de Componentes Principales).
Autocodificadores como filtros de imagen
Alternativamente a la reducción de la dimensionalidad, los Autocodificadores también pueden utilizarse para filtrar ruido de las imágenes. Para ello durante la fase de entrenamiento se tendría que pasar un conjunto de imágenes con ruido como entrada, y a la salida se tendrían que pasar las imágenes correspondientes sin ruido (Fig. 3)
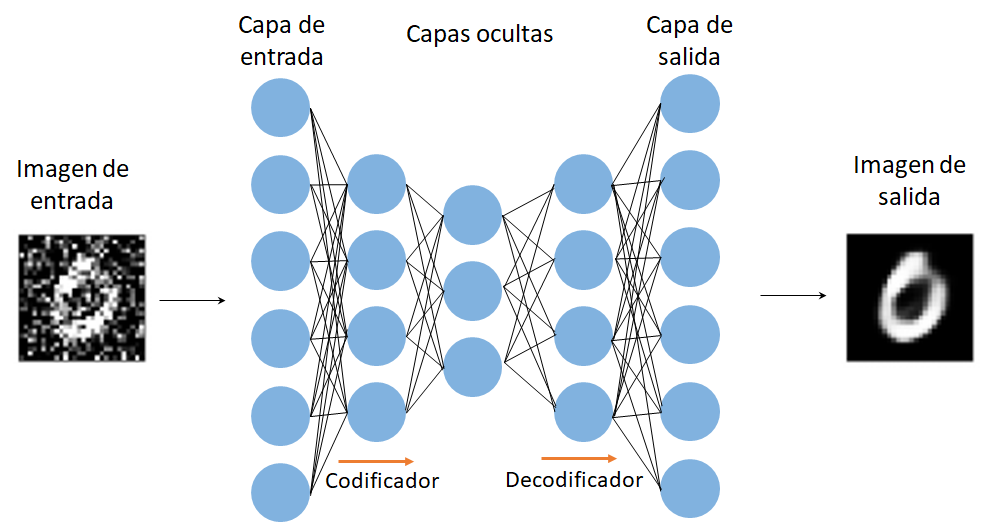
Figura 3: Arquitectura general de un Autocodificador para eliminar ruido de imágenes
De esta manera el Autocodificador “aprenderá” a remover el ruido de las imágenes. Una vez entrenado el Autocodificador será capaz de eliminar el ruido de cualquier imagen de dígitos del 0 a 9, aunque nunca la red los haya “visto”. Nótese que no es necesario indicarle ninguna regla o filtro específico a la red, sino que esta “aprende” sola durante la fase de entrenamiento.
Código para generar un Autocodificador para filtrar imágenes
A continuación, se muestra el código para crear un Autocodificador para eliminar el ruido de imágenes. En este ejemplo se utilizarán las imágenes de dígitos escritos a mano extraídos de los datos MNIST de la librería sklearn de Python. La librería cuenta con 70000 imágenes de dígitos
Primero, se separa el conjunto de imágenes en dos grupos; el primer grupo estará formado por los datos usados para entrenar la red (85%) y el resto (15%) para evaluar la calidad de la red. Luego en una nueva variable guardamos ambos conjuntos de imágenes, pero ahora después de añadirles un ruido gaussiano. Estas son las imágenes que se pasan a la entrada del Autocodificador en la fase de entrenamiento, mientras que a la salida se pasan las imágenes originales extraídas de MNIST. Para definir la arquitectura de la red se utiliza la librería keras de Python, que es una interfaz muy sencilla de TensorFlow.
# Importar librerías
from sklearn.datasets import fetch_openml
from sklearn.model_selection import train_test_split
import numpy as np
import matplotlib.pyplot as plt
from keras.layers import Input, Dense, Conv2D, MaxPooling2D, UpSampling2D
from keras.models import Model
from keras import backend as K
#Importar imágenes de dígitos de la librería MNIST
X, y = fetch_openml('mnist_784', version=1, return_X_y=True)
#Separar grupo de entrenamiento y grupo de validación
train_img, test_img, train_lbl, test_lbl = train_test_split( X, y, test_size=1/7.0, random_state=100)
#Visualizar algunas de las imágenes
#Esta parte del código se deja ejecutar al lector para que
#verifique como lucen las imágenes de la librería MNIST
plt.figure(figsize=(10,10))
for index, (image, label) in enumerate(zip(train_img[0:15], train_lbl[0:15])):
plt.subplot(3, 5, index + 1)
plt.imshow(np.reshape(image, (28,28)), cmap=plt.cm.gray)
plt.title('Training: %s' % label, fontsize = 20)
#Normalizar imágenes entre 0 y 1
train_img = train_img.astype('float32') / 255
test_img = test_img.astype('float32') / 255
# Añadir ruido Gausiano centrado en 0.5 y con std=0.5 a las imágenes originales
noise = np.random.normal(loc=0.5, scale=0.5, size=train_img.shape)
x_img_train_noisy = train_img + noise
noise = np.random.normal(loc=0.5, scale=0.5, size=test_img.shape)
x_img_test_nosisy = test_img + noise
# Ajustar tamño de las imágenes
x_train_noisy = np.reshape(x_img_train_noisy, [-1, 28, 28, 1])
x_test_nosisy = np.reshape(x_img_test_nosisy, [-1, 28, 28, 1])
#Definir la arquitectura del Autocodificador
input_img = Input(shape=(28, 28, 1))
x = Conv2D(16, (3, 3), activation='relu', padding='same')(input_img)
x = MaxPooling2D((2, 2), padding='same')(x)
x = Conv2D(8, (3, 3), activation='relu', padding='same')(x)
x = MaxPooling2D((2, 2), padding='same')(x)
x = Conv2D(8, (3, 3), activation='relu', padding='same')(x)
encoded = MaxPooling2D((2, 2), padding='same')(x)
x = Conv2D(8, (3, 3), activation='relu', padding='same')(encoded)
x = UpSampling2D((2, 2))(x)
x = Conv2D(8, (3, 3), activation='relu', padding='same')(x)
x = UpSampling2D((2, 2))(x)
x = Conv2D(16, (3, 3), activation='relu')(x)
x = UpSampling2D((2, 2))(x)
decoded = Conv2D(1, (3, 3), activation='sigmoid', padding='same')(x)
autoencoder = Model(input_img, decoded)
autoencoder.compile(optimizer='adadelta', loss='binary_crossentropy')
# Entrenar el Autocodificador. Note que los dos primeros argumentos de
#la función corresponden a los datos de entrada y de salida respectivamente
H1 = autoencoder.fit(x_train_noisy, x_train,
epochs=30,
batch_size=128,
shuffle=True,
validation_data=(x_test_nosisy, x_test)
)
# Aplicar el Autocodificador ya entrenado al conjunto de imágenes del grupo de validación
denoised_img = autoencoder.predict(x_test_nosisy)
# Mostrar imágenes de entrada y el resultado luego de aplicar el Autocodificador (Figura 4)
n = 9
plt.figure(figsize=(20, 4))
for i in range(n):
# mostrar originales
ax = plt.subplot(2, n, i+1)
plt.imshow(x_test_nosisy[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
# mostrar imágenes tras remover el ruido
ax = plt.subplot(2, n, i + n+1)
plt.imshow(denoised_img[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()
Finalmente, se muestran los resultados obtenidos al aplicar el Autocodificador sobre algunas de las imágenes del conjunto de validación (Fig. 4).

Figura 4: Imágenes con ruido gaussiano (línea superior) y las correspondientes imágenes devueltas por el Autocodificador de filtrado (línea inferior).
Como se puede ver en la Figura 4 el resultado es bastante impresionante. La principal ventaja de este método es que no tenemos que preocuparnos del tipo de filtro que debemos aplicar sino que la red neuronal aprende sola cuál es el conjuno de filtros más óptimos a aplicar para obtener el resultado esperado. Por otra parte, la principal desventaja de este método es que se necesita una gran cantidad de imágenes (más de 1000) para entrenar la red neuronal. Así que como siempre decimos el uso o no de los Autocodificadores con el fin de reducir el ruido de imágenes dependerá mucho del problema particular. En general si contamos con un conjunto grande de imágenes para entrenar la red, es preferible utilizar Autocodificadores antes de cualquier otro método para reducir el ruido de las imágenes.