
Blog
Proyecto: Desarrollar un Modelo Neural de Bolsa de Palabras para el Análisis de Sentimientos
Las críticas o comentarios de películas pueden ser clasificadas como favorables o no. La evaluación del texto de la revisión de la película es un problema de la clasificación a menudo llamado análisis de sentimientos. Una técnica popular para desarrollar modelos de análisis de sentimientos es usar un modelo de bolsa de palabras que transforma los documentos en vectores, donde a cada palabra del documento se le asigna una puntuación. En esta parte, descubrirás cómo puedes desarrollar un modelo predictivo de Deep Learning utilizando la representación de la bolsa de palabras para la clasificación de sentimientos de la crítica cinematográfica. Después de completar esta parte, tú sabrás:
- Cómo preparar los datos del texto de revisión para el modelado con un vocabulario restringido.
- Cómo usar el modelo de la bolsa de palabras para preparar los datos del entrenamiento, y las pruebas.
- Cómo desarrollar un modelo de bolsa de palabras multicapa de Perceptron, y utilizarlo para hacer predicciones sobre nuevos datos de texto de revisión.
Vamos a empezar.
Descripción del tutorial: Desarrollar un Modelo Neural de Bolsa de Palabras para el Análisis de Sentimientos
Este tutorial está dividido en las siguientes partes:
- Conjunto de datos de revisión de películas
- Preparación de datos
- Representación de la bolsa de palabras
- Modelos de Análisis de Sentimientos
- Comparación de métodos de valoración de palabras
- Prediciendo Sentimientos para Nuevas Revisiones
Conjunto de datos de revisión de películas
En este tutorial, utilizaremos el conjunto de datos de Movie Review. Este conjunto de datos diseñado para el análisis de sentimientos se describió anteriormente en el tutorial 3.2. Puede descargar el conjunto de datos desde aquí:
- Movie Review Polarity Dataset (review polarity.tar.gz, 3MB).
http://www.cs.cornell.edu/people/pabo/movie-review-data/review_polarity.tar.gz
Después de descomprimir el archivo, tendrá un directorio llamado txt sentoken con dos subdirectorios que contienen el texto neg y pos para comentarios negativos y positivos. Las revisiones se almacenan una por archivo con una convención de nomenclatura cv000 a cv999 para cada uno de los formatos neg y pos. A continuación, veamos cómo cargar los datos de texto.
Preparación de datos
La preparación del conjunto de datos de críticas de películas se describió por primera vez en el post anterior.
En esta sección, veremos tres cosas:
- Separación de datos en equipos de entrenamiento y de prueba.
- Cargar y limpiar los datos para eliminar la puntuación y los números.
- Definir un vocabulario de palabras preferidas
Dividir en entrenamiento y conjuntos de pruebas
Estamos pretendiendo desarrollar un sistema que puede predecir el sentimiento de una crítica cinematográfica textual como positivo o negativo. Esto significa que después de que el modelo sea desarrollado, necesitaremos hacer predicciones sobre nuevas revisiones textuales. Esto requerirá que se lleve a cabo la misma preparación de datos en las nuevas revisiones que se realiza en los datos de capacitación para el modelo.
Nos aseguraremos de que esta restricción se incorpore en la evaluación de nuestros modelos dividiendo los conjuntos de datos de formación y de prueba antes de cualquier preparación de datos. Esto significa que cualquier conocimiento en el conjunto de pruebas que pueda ayudarnos a preparar mejor los datos (por ejemplo, las palabras utilizadas) no está disponible durante la preparación de los datos y la capacitación del modelo. Dicho esto, utilizaremos las últimas 100 revisiones positivas y las últimas 100 negativas como conjunto de pruebas (100 revisiones) y las restantes 1.800 revisiones como conjunto de datos de formación. Esto es un entrenamiento del 90%, con una división del 10% de los datos. La división puede imponerse fácilmente utilizando los nombres de archivo de las revisiones, donde las revisiones nombradas de 000 a 899 son para datos de formación y las nombradas de 900 en adelante son para probar el modelo.
Comentarios sobre la carga y la limpieza
Los datos de texto ya están bastante limpios, por lo que no se requiere mucha preparación. Sin entrar demasiado en detalles, prepararemos los datos utilizando el siguiente método:
- Dividir tokens en espacios en blanco
- Eliminar todos los signos de puntuación de las palabras.
- Elimine todas las palabras que no estén compuestas únicamente de caracteres alfabéticos.
- Elimine todas las palabras que son palabras de parada conocidas.
- Elimine todas las palabras que tengan una longitud de ≤ 1 carácter.
Podemos poner todos estos pasos en una función llamada clean_doc() que toma como argumento el texto crudo cargado desde un archivo y devuelve una lista de tokens limpios. También podemos definir una función load_doc() que carga un documento desde un archivo listo para su uso con la función clean_doc(). Un ejemplo de la limpieza de la primera revisión positiva se enumeran a continuación.
from nltk.corpus import stopwords
import string
import re
# cargar el documento en la memoria
def load_doc(filename):
# abra el archivo como de solo lectura
file = open(filename, 'r')
# leer todo el texto
text = file.read()
# cierra el archivo
file.close()
return text
# convertir un documento en tokens limpios
def clean_doc(doc):
# dividido en tokens por espacio en blanco
tokens = doc.split()
# preparar regex para el filtrado de caracteres
re_punc = re.compile('[%s]' % re.escape(string.punctuation))
# eliminar puntuación de cada palabra
tokens = [re_punc.sub('', w) for w in tokens]
# eliminar los tokens restantes que no son alfabéticos
tokens = [word for word in tokens if word.isalpha()]
# filtrar las palabras de parada
stop_words = set(stopwords.words('english'))
tokens = [w for w in tokens if not w in stop_words]
# filtrar tokens cortos
tokens = [word for word in tokens if len(word) > 1]
return tokens
#cargar el documento
filename = 'txt_sentoken/pos/cv000_29590.txt'
text = load_doc(filename)
tokens = clean_doc(text)
print(tokens)
Al ejecutar el ejemplo se imprime una larga lista de tokens limpios. Hay muchos más pasos de limpieza que tal vez queramos explorar, y los dejo como ejercicios adicionales. Me encantaría ver qué se te ocurre.
['films', 'adapted', 'comic', 'books', 'plenty', 'success', 'whether', 'theyre', 'superheroes', 'batman', 'superman', 'spawn', 'geared', 'toward', 'kids', 'casper', 'arthouse', 'crowd', 'ghost', 'world', 'theres', 'never', 'really', 'comic', 'book', 'like', 'hell', 'starters', 'created', 'alan', 'moore', 'eddie', 'campbell', 'brought', 'medium', 'whole', 'new', 'level', 'mid', 'series', 'called', 'watchmen', 'say', 'moore', 'campbell', 'thoroughly', 'researched', 'subject', 'jack', 'ripper', 'would', 'like', 'saying', 'michael', 'jackson', 'starting', 'look', 'little', 'odd', 'book', 'graphic', 'novel', 'pages', 'long', 'includes', 'nearly', 'consist', 'nothing', 'footnotes', 'words', 'dont', 'dismiss', 'film', 'source', 'get', 'past', 'whole', 'comic', 'book', 'thing', 'might', 'find', 'another', 'stumbling', 'block', 'hells', 'directors', 'albert', 'allen', 'hughes', 'getting', 'hughes', 'brothers', 'direct', 'seems', 'almost', 'ludicrous', 'casting', 'carrot', 'top', 'well', 'anything', 'riddle', 'better', 'direct', 'film', 'thats', 'set', 'ghetto', 'features', 'really', 'violent', 'street', 'crime', 'mad', 'geniuses', 'behind', 'menace', 'ii', 'society', 'ghetto', 'question', 'course', 'whitechapel', 'londons', 'east', 'end', 'filthy', 'sooty', 'place', 'whores', 'called', 'unfortunates', 'starting', 'get', 'little', 'nervous', 'mysterious', 'psychopath', 'carving', 'profession', 'surgical', 'precision', 'first', 'stiff', 'turns', 'copper', 'peter', 'godley', 'robbie', 'coltrane', 'world', 'enough', 'calls', 'inspector', 'frederick', 'abberline', 'johnny', 'depp', 'blow', 'crack', 'case', 'abberline', 'widower', 'prophetic', 'dreams', 'unsuccessfully', 'tries', 'quell', 'copious', 'amounts', 'absinthe', 'opium', 'upon', 'arriving', 'whitechapel', 'befriends', 'unfortunate', 'named', 'mary', 'kelly', 'heather', 'graham', 'say', 'isnt', 'proceeds', 'investigate', 'horribly', 'gruesome', 'crimes', 'even', 'police', 'surgeon', 'cant', 'stomach', 'dont', 'think', 'anyone', 'needs', 'briefed', 'jack', 'ripper', 'wont', 'go', 'particulars', 'say', 'moore', 'campbell', 'unique', 'interesting', 'theory', 'identity', 'killer', 'reasons', 'chooses', 'slay', 'comic', 'dont', 'bother', 'cloaking', 'identity', 'ripper', 'screenwriters', 'terry', 'hayes', 'vertical', 'limit', 'rafael', 'yglesias', 'les', 'mis', 'rables', 'good', 'job', 'keeping', 'hidden', 'viewers', 'end', 'funny', 'watch', 'locals', 'blindly', 'point', 'finger', 'blame', 'jews', 'indians', 'englishman', 'could', 'never', 'capable', 'committing', 'ghastly', 'acts', 'hells', 'ending', 'whistling', 'stonecutters', 'song', 'simpsons', 'days', 'holds', 'back', 'electric', 'carwho', 'made', 'steve', 'guttenberg', 'star', 'dont', 'worry', 'itll', 'make', 'sense', 'see', 'onto', 'hells', 'appearance', 'certainly', 'dark', 'bleak', 'enough', 'surprising', 'see', 'much', 'looks', 'like', 'tim', 'burton', 'film', 'planet', 'apes', 'times', 'seems', 'like', 'sleepy', 'hollow', 'print', 'saw', 'wasnt', 'completely', 'finished', 'color', 'music', 'finalized', 'comments', 'marilyn', 'manson', 'cinematographer', 'peter', 'deming', 'dont', 'say', 'word', 'ably', 'captures', 'dreariness', 'victorianera', 'london', 'helped', 'make', 'flashy', 'killing', 'scenes', 'remind', 'crazy', 'flashbacks', 'twin', 'peaks', 'even', 'though', 'violence', 'film', 'pales', 'comparison', 'blackandwhite', 'comic', 'oscar', 'winner', 'martin', 'childs', 'shakespeare', 'love', 'production', 'design', 'turns', 'original', 'prague', 'surroundings', 'one', 'creepy', 'place', 'even', 'acting', 'hell', 'solid', 'dreamy', 'depp', 'turning', 'typically', 'strong', 'performance', 'deftly', 'handling', 'british', 'accent', 'ians', 'holm', 'joe', 'goulds', 'secret', 'richardson', 'dalmatians', 'log', 'great', 'supporting', 'roles', 'big', 'surprise', 'graham', 'cringed', 'first', 'time', 'opened', 'mouth', 'imagining', 'attempt', 'irish', 'accent', 'actually', 'wasnt', 'half', 'bad', 'film', 'however', 'good', 'strong', 'violencegore', 'sexuality', 'language', 'drug', 'content']
Definir un vocabulario
Es importante definir un vocabulario de palabras conocidas cuando se utiliza un modelo de bolsa de palabras. Cuantas más palabras, mayor será la representación de los documentos, por lo que es importante limitar las palabras a sólo las que se consideran predictivas. Esto es difícil de saber de antemano, y a menudo es importante probar diferentes hipótesis sobre cómo construir un vocabulario útil. Ya hemos visto cómo podemos eliminar la puntuación y los números del vocabulario en la sección anterior. Podemos repetir esto para todos los documentos y construir un conjunto de todas las palabras conocidas.
Podemos desarrollar un vocabulario como Counter, que es un diccionario de mapeo de palabras y su conteom que nos permite actualizar y consultar fácilmente. Cada documento puede ser añadido al contador (una nueva función llamada add_doc_to_vocab()) y podemos pasar por encima de todas las revisiones en el directorio negativo y luego en el positivo (una nueva función llamada process_docs()).
El ejemplo completo se enumera a continuación.
import string
import re
from os import listdir
from collections import Counter
from nltk.corpus import stopwords
# cargar documento en la memoria
def load_doc(filename):
# abrir documento en modo solo lectura
file = open(filename, 'r')
# leer todo el texto
text = file.read()
# cerrar el documento
file.close()
return text
# convertir un documento en tokens limpias
def clean_doc(doc):
# dividir en tokens por espacio en blanco
tokens = doc.split()
# preparar regex para el filtrado de caracteres
re_punc = re.compile('[%s]' % re.escape(string.punctuation))
# eliminar puntuación de cada palabra
tokens = [re_punc.sub('', w) for w in tokens]
# eliminar los tokens restantes que no son alfabéticos
tokens = [word for word in tokens if word.isalpha()]
# filtrar palabras de parada
stop_words = set(stopwords.words('english'))
tokens = [w for w in tokens if not w in stop_words]
# filtrar tokens cortos
tokens = [word for word in tokens if len(word) > 1]
return tokens
# cargar documento y añadir al vocabulario
def add_doc_to_vocab(filename, vocab):
# cargar doc
doc = load_doc(filename)
# limpiar doc
tokens = clean_doc(doc)
# actualizar contadores
vocab.update(tokens)
# cargar todos los documentos en el directorio
def process_docs(directory, vocab):
# recorrer todos los archivos de la carpeta
for filename in listdir(directory):
# omitir cualquier revisión en el conjunto de pruebas
if filename.startswith('cv9'):
continue
# crear la ruta de acceso completa del archivo para abrir
path = directory + '/' + filename
# añadir doc al vocabulario
add_doc_to_vocab(path, vocab)
# define el vocabulario
vocab = Counter()
# añadir todos los documentos al vocabulario
process_docs('txt_sentoken/pos', vocab)
process_docs('txt_sentoken/neg', vocab)
# imprimir el tamaño del vocabulario
print(len(vocab))
# imprime las palabras más importantes en el vocabulario
print(vocab.most_common(50))
El ejemplo muestra que tenemos un vocabulario de 44.276 palabras. También podemos ver una muestra de las 50 palabras más usadas en las reseñas de películas. Tenga en cuenta que este vocabulario se construyó basándose sólo en las revisiones del conjunto de datos de la capacitación.
44276
[('film', 7983), ('one', 4946), ('movie', 4826), ('like', 3201), ('even', 2262), ('good', 2080), ('time', 2041), ('story', 1907), ('films', 1873), ('would', 1844), ('much', 1824), ('also', 1757), ('characters', 1735), ('get', 1724), ('character', 1703), ('two', 1643), ('first', 1588), ('see', 1557), ('way', 1515), ('well', 1511), ('make', 1418), ('really', 1407), ('little', 1351), ('life', 1334), ('plot', 1288), ('people', 1269), ('could', 1248), ('bad', 1248), ('scene', 1241), ('movies', 1238), ('never', 1201), ('best', 1179), ('new', 1140), ('scenes', 1135), ('man', 1131), ('many', 1130), ('doesnt', 1118), ('know', 1092), ('dont', 1086), ('hes', 1024), ('great', 1014), ('another', 992), ('action', 985), ('love', 977), ('us', 967), ('go', 952), ('director', 948), ('end', 946), ('something', 945), ('still', 936)]
Podemos repasar el vocabulario y eliminar todas las palabras que tengan una baja ocurrencia, como por ejemplo, que sólo se usen una o dos veces en todas las revisiones. Por ejemplo, el siguiente fragmento recuperará sólo los tokens que aparecen 2 o más veces en todas las revisiones.
# mantener tokens con una ocurrencia mínima min_occurrence = 2 tokens = [k for k,c in vocab.items() if c >= min_occurrence] print(len(tokens))
Finalmente, el vocabulario puede ser guardado en un nuevo archivo llamado vocab.txt que luego podemos cargar y usar para filtrar las reseñas de películas antes de codificarlas para modelarlas. Definimos una nueva función llamada save_list() que guarda el vocabulario en un archivo, con una palabra por línea. Por ejemplo:
# guardar lista en el archivo def save_list(lines, filename): # convertir líneas en una sola gota de texto data = '\n'.join(lines) # abrir documento file = open(filename, 'w') # escribir texto file.write(data) # cerrar documento file.close() # guardar tokens en un archivo de vocabulario save_list(tokens, 'vocab.txt')
Reuniendo todo esto, el ejemplo completo es puesto en una lista abajo.
import string
import re
from os import listdir
from collections import Counter
from nltk.corpus import stopwords
# cargar dos en la memoria
def load_doc(filename):
# abrir en archivo en modo solo lectura
file = open(filename, 'r')
# leer todo el texto
text = file.read()
# cerrar el documento
file.close()
return text
# convertir a doc en tokens limpias
def clean_doc(doc):
# dividido en tokens por espacio en blanco
tokens = doc.split()
# preparar a regex para el filtrado de caracteres
re_punc = re.compile('[%s]' % re.escape(string.punctuation))
# eliminar la puntuación de cada palabra
tokens = [re_punc.sub('', w) for w in tokens]
# eliminar los tokens restantes que no estén en orden alfabético
tokens = [word for word in tokens if word.isalpha()]
# filtrar las palabras de parada
stop_words = set(stopwords.words('english'))
tokens = [w for w in tokens if not w in stop_words]
# filtrar los tokens cortos
tokens = [word for word in tokens if len(word) > 1]
return tokens
# cargar doc y añadir al vocabulario
def add_doc_to_vocab(filename, vocab):
# cargar doc
doc = load_doc(filename)
# limpiar doc
tokens = clean_doc(doc)
# actualizar contadores
vocab.update(tokens)
# cargar todos los documentos en un directorio
def process_docs(directory, vocab):
# revisar todos los archivos de la carpeta
for filename in listdir(directory):
# omita cualquier comentario en el juego de pruebas
if filename.startswith('cv9'):
continue
# crear la ruta completa del archivo a abrir
path = directory + '/' + filename
# añadir doc al vocabulario
add_doc_to_vocab(path, vocab)
# guardar lista en un archivo
def save_list(lines, filename):
# convertir líneas en una sola gota de texto
data = '\n'.join(lines)
# abrir archivo
file = open(filename, 'w')
# escribir texto
file.write(data)
# cerrar archivo
file.close()
# definir vocabulario
vocab = Counter()
# añadir todos los documentos al vocabulario
process_docs('txt_sentoken/pos', vocab)
process_docs('txt_sentoken/neg', vocab)
# imprimir el tamaño del vocabulario
print(len(vocab))
# guardar tokens con una ocurrencia mínima
min_occurrence = 2
tokens = [k for k,c in vocab.items() if c >= min_occurrence]
print(len(tokens))
# guardar tokens en un archivo de vocabulario
save_list(tokens, 'vocab.txt')
Ejecutando el ejemplo anterior con esta adición muestra que el tamaño del vocabulario baja un poco más de la mitad de su tamaño, de unas 44.000 a unas 25.000 palabras.
44276 25767
Ejecutando el filtro de ocurrencia mínima en el vocabulario y guardándolo en un archivo, ahora debería tener un nuevo archivo llamado vocab.txt con sólo las palabras que nos interesan
El orden de las palabras en su archivo será diferente, pero debe parecerse al siguiente:
aberdeen dupe burt libido hamlet arlene available corners web columbia ...
Representación de la bolsa de palabras
En esta sección, veremos cómo podemos convertir cada revisión en una representación que podamos proporcionar a un modelo de Perceptrón multicapa. Un modelo de bolsa de palabras es una forma de extraer características del texto para que la entrada de texto se pueda utilizar con algoritmos de aprendizaje automático como las redes neuronales. Cada documento, en este caso una revisión, se convierte en una representación vectorial. El número de elementos en el vector que representa un documento corresponde al número de palabras del vocabulario. Cuanto mayor sea el vocabulario, más larga será la representación vectorial, de ahí la preferencia por vocabularios más pequeños en la sección anterior. El modelo de la bolsa de palabras se introdujo anteriormente en el Capítulo 8.
Las palabras de un documento se califican y las puntuaciones se colocan en el lugar correspondiente de la representación. En la siguiente sección veremos los diferentes métodos de puntuación de palabras. En esta sección, nos ocupamos de convertir las revisiones en vectores listos para entrenar un primer modelo de red neuronal. Esta sección se divide en 2 pasos:
1. Convertir comentarios en líneas de tokens.
2. Codificación de revisiones con una representación de un modelo de bolsa de palabras.
Reseñas de Líneas de Tokens
Antes de que podamos convertir las revisiones en vectores para modelar, primero debemos limpiarlas. Esto implica cargarlos, realizar la operación de limpieza desarrollada anteriormente, filtrar las palabras que no están en el vocabulario elegido y convertir los tokens restantes en una sola cadena o línea lista para ser codificada. En primer lugar, necesitamos una función para preparar un documento. Abajo se muestra la función doc_ to_line() que cargará un documento, lo limpiará, filtrará los tokens que no están en el vocabulario, y luego devolverá el documento como una cadena de tokens separados por espacios en blanco.
# carga del doc, limpieza y línea de retorno de los tokens def doc_to_line(filename, vocab): # cargar doc doc = load_doc(filename) # limpiar doc tokens = clean_doc(doc) # filtrar el vocabulario tokens = [w for w in tokens if w in vocab] return ' '.join(tokens)
A continuación, necesitamos una función para trabajar a través de todos los documentos en un directorio (como pos y neg) para convertir los documentos en líneas. A continuación se muestra la función process_docs() que hace precisamente esto, esperando un nombre de directorio y un conjunto de vocabulario como argumentos de entrada y devolviendo una lista de los documentos procesados.
# cargar todos los documentos en un directorio
def process_docs(directory, vocab):
lines = list()
# revisar todos los archivos de la carpeta
for filename in listdir(directory):
# omita cualquier comentario en el juego de pruebas
if filename.startswith('cv9'):
continue
# crear la ruta completa del archivo a abrir
path = directory + '/' + filename
# cargar y limpiar doc
line = doc_to_line(path, vocab)
# añadir a la lista
lines.append(line)
return lines
Podemos llamar al process_focs() consistentemente para revisiones positivas y negativas para construir un conjunto de datos de texto de revisión y sus etiquetas de salida asociadas, 0 para negativas y 1 para positivas. La función load_clean_dataset() de abajo implementa este comportamiento.
# cargar y limpiar un conjunto de datos
def load_clean_dataset(vocab):
# cargar documentos
neg = process_docs('txt_sentoken/neg', vocab)
pos = process_docs('txt_sentoken/pos', vocab)
docs = neg + pos
# preparar las etiquetas
labels = [0 for _ in range(len(neg))] + [1 for _ in range(len(pos))]
return docs, labels
Finalmente, necesitamos cargar el vocabulario y convertirlo en un conjunto para su uso en revisiones de limpieza.
# cargar vocabulario vocab_filename = 'vocab.txt' vocab = load_doc(vocab_filename) vocab = set(vocab.split())
Todo esto lo podemos agrupar, reutilizando las funciones de carga y limpieza desarrolladas en los apartados anteriores. El ejemplo completo se enumera a continuación, demostrando cómo preparar las revisiones positivas y negativas del conjunto de datos de la capacitación.
import string
import re
from os import listdir
from nltk.corpus import stopwords
# cargar doc en la memoria
def load_doc(filename):
# abrir el archivo en solo lectura
file = open(filename, 'r')
# leer todo el documento
text = file.read()
# cerrar el documento
file.close()
return text
# convertir el Doc en tokens limpios
def clean_doc(doc):
# dividido en tokens por espacio en blanco
tokens = doc.split()
# preparar a regex para el filtrado de caracteres
re_punc = re.compile('[%s]' % re.escape(string.punctuation))
# eliminar la puntuación de cada palabra
tokens = [re_punc.sub('', w) for w in tokens]
# eliminar los tokens restantes que no estén en orden alfabético
tokens = [word for word in tokens if word.isalpha()]
# filtrar las palabras de parada
stop_words = set(stopwords.words('english'))
tokens = [w for w in tokens if not w in stop_words]
# filtrar los tokens cortos
tokens = [word for word in tokens if len(word) > 1]
return tokens
# cargar doc, limpieza y línea de retorno de tokens
def doc_to_line(filename, vocab):
# cargar doc
doc = load_doc(filename)
# limpiar doc
tokens = clean_doc(doc)
# filtrar el vocabulario
tokens = [w for w in tokens if w in vocab]
return ' '.join(tokens)
# cargar todos los documentos en el vocabulario
def process_docs(directory, vocab):
lines = list()
# revisar todos los archivos de la carpeta
for filename in listdir(directory):
# omita cualquier comentario en el juego de pruebas
if filename.startswith('cv9'):
continue
# crear la ruta completa del archivo a abrir
path = directory + '/' + filename
# cargar y limpiar doc
line = doc_to_line(path, vocab)
# añadir a la lista
lines.append(line)
return lines
# cargar y limpiar un conjunto de datos
def load_clean_dataset(vocab):
# cargar documentos
neg = process_docs('txt_sentoken/neg', vocab)
pos = process_docs('txt_sentoken/pos', vocab)
docs = neg + pos
# preparar etiquetas
labels = [0 for _ in range(len(neg))] + [1 for _ in range(len(pos))]
return docs, labels
# cargar el vocabulario
vocab_filename = 'vocab.txt'
vocab = load_doc(vocab_filename)
vocab = vocab.split()
vocab = set(vocab)
# cargar todas las revisiones de entrenamiento
docs, labels = load_clean_dataset(vocab)
# resumir lo que tenemos
print(len(docs), len(labels))
Al ejecutar este ejemplo se carga y limpia el texto de revisión y se devuelven las etiquetas.
1800 1800
Comentarios de películas sobre los vectores de la bolsa de palabras
Usaremos la API de Keras para convertir revisiones a vectores de documentos codificados. Keras proporciona la clase Tokenizer que puede hacer algunas de las tareas de limpieza y definición de vocabulario de las que nos encargamos en la sección anterior. Es mejor hacerlo nosotros mismos para saber exactamente qué se hizo y por qué. Sin embargo, la clase Tokenizer es conveniente y transformará fácilmente documentos en vectores codificados. Primero, se debe crear el Tokenizer, y luego encajar en los documentos de texto en el conjunto de datos de formación. En este caso, se trata de la agregación de las matrices de líneas positivas y negativas desarrolladas en el apartado anterior.
# resumir lo que tenemos def create_tokenizer(lines): tokenizer = Tokenizer() tokenizer.fit_on_texts(lines) return tokenizer
Este proceso determina una manera consistente de convertir el vocabulario a un vector de longitud fija con 25,768 elementos, que es el número total de palabras en el archivo de vocabulario vocab.txt. Luego, los documentos pueden ser codificados usando el Tokenizer llamando textos a matrix(). La función toma tanto una lista de documentos a codificar como un modo de codificación, que es el método utilizado para puntuar palabras en el documento. Aquí especificamos freq para puntuar las palabras en función de su frecuencia en el documento. Esto se puede utilizar para codificar los datos de entrenamiento y de prueba cargados, por ejemplo:
# datos codificados Xtrain = tokenizer.texts_to_matrix(train_docs, mode='freq') Xtest = tokenizer.texts_to_matrix(test_docs, mode='freq')
Esto codifica todas las revisiones positivas y negativas del conjunto de datos de formación.
A continuación, la función process_docs() de la sección anterior necesita ser modificada para procesar selectivamente las revisiones en el conjunto de datos de prueba o entrenamiento. Apoyamos la carga de los conjuntos de datos de entrenamiento y de prueba añadiendo un argumento is_train y usándolo para decidir qué nombres de archivo de revisión omitir.
#cargar todos los docuentos en el directorio
def process_docs(directory, vocab, is_train):
lines = list()
# revisar todos los archivos de la carpeta
for filename in listdir(directory):
# omita cualquier comentario en el juego de pruebas
if is_train and filename.startswith('cv9'):
continue
if not is_train and not filename.startswith('cv9'):
continue
# crear la ruta completa del archivo a abrir
path = directory + '/' + filename
# cargar y limpiar el documento
line = doc_to_line(path, vocab)
# añadir a la lista
lines.append(line)
return lines
Del mismo modo, el conjunto de datos load_clean_dataset() debe actualizarse para cargar los datos de entrenamiento o de la prueba y asegurarse de que devuelve una matriz NumPy
# cargar y limpiar el conjunto de datos
def load_clean_dataset(vocab, is_train):
# cargar documentos
neg = process_docs('txt_sentoken/neg', vocab, is_train)
pos = process_docs('txt_sentoken/pos', vocab, is_train)
docs = neg + pos
# preparar etiquetas
labels = array([0 for _ in range(len(neg))] + [1 for _ in range(len(pos))])
return docs, labels
Podemos poner todo esto junto en un solo ejemplo.
import string
import re
from os import listdir
from numpy import array
from nltk.corpus import stopwords
from keras.preprocessing.text import Tokenizer
# cargar a doc en la memoria
def load_doc(filename):
# abrir el archivo en modo solo lectra
file = open(filename, 'r')
# leer todo el texto
text = file.read()
# cerrar el archivo
file.close()
return text
# convertir dos en tokens limpios
def clean_doc(doc):
# dividido en tokens por espacio en blanco
tokens = doc.split()
# preparar a regex para el filtrado de caracteres
re_punc = re.compile('[%s]' % re.escape(string.punctuation))
# remover la puntuación de cada palabra
tokens = [re_punc.sub('', w) for w in tokens]
# remover los tokens que no están en orden alfabético
tokens = [word for word in tokens if word.isalpha()]
# filtrar palabras de parada
stop_words = set(stopwords.words('english'))
tokens = [w for w in tokens if not w in stop_words]
# filtrar los tokens cortos
tokens = [word for word in tokens if len(word) > 1]
return tokens
# cargar doc, limpieza y línea de retorno de las tokens
def doc_to_line(filename, vocab):
# cargar documento
doc = load_doc(filename)
# limpiar documento
tokens = clean_doc(doc)
# filtrar vocabulario
tokens = [w for w in tokens if w in vocab]
return ' '.join(tokens)
# cargar todos los documentos en el directorio
def process_docs(directory, vocab, is_train):
lines = list()
# revisar todos los archivos de la carpeta
for filename in listdir(directory):
# omita cualquier comentario en el juego de pruebas
if is_train and filename.startswith('cv9'):
continue
if not is_train and not filename.startswith('cv9'):
continue
# crear la ruta completa del archivo a abrir
path = directory + '/' + filename
# cargar y limpiar doc
line = doc_to_line(path, vocab)
# añadir a la lista
lines.append(line)
return lines
# cargar y limpiar el comjunto de datos
def load_clean_dataset(vocab, is_train):
# cargar documentos
neg = process_docs('txt_sentoken/neg', vocab, is_train)
pos = process_docs('txt_sentoken/pos', vocab, is_train)
docs = neg + pos
# preparar etiquetas
labels = array([0 for _ in range(len(neg))] + [1 for _ in range(len(pos))])
return docs, labels
# instalar un tokenizador
def create_tokenizer(lines):
tokenizer = Tokenizer()
tokenizer.fit_on_texts(lines)
return tokenizer
# cargar el vocabulario
vocab_filename = 'vocab.txt'
vocab = load_doc(vocab_filename)
vocab = set(vocab.split())
# cargar todas las revisiones
train_docs, ytrain = load_clean_dataset(vocab, True)
test_docs, ytest = load_clean_dataset(vocab, False)
# crear el tokenizer
tokenizer = create_tokenizer(train_docs)
# codificar datos
Xtrain = tokenizer.texts_to_matrix(train_docs, mode='freq')
Xtest = tokenizer.texts_to_matrix(test_docs, mode='freq')
print(Xtrain.shape, Xtest.shape)
Al ejecutar el ejemplo, se imprime tanto la forma del conjunto de datos de entrenamiento codificado como el conjunto de datos de prueba con 1.800 y 200 documentos respectivamente, cada uno con el mismo tamaño de vocabulario codificado (longitud vectorial).
(1800, 25768) (200, 25768)
Modelos de Análisis de Sentimientos
En esta sección, desarrollaremos modelos de Perceptrón multicapa (MLP) para clasificar documentos codificados como positivos o negativos. Los modelos serán simples modelos de red avanzados con capas totalmente conectadas llamadas densas en la biblioteca de aprendizaje profundo de Keras. Esta sección está dividida en 3 secciones:
1. Modelo de análisis del primer sentimiento
2. Comparación de modos de puntuación de palabras
3. Hacer una predicción para nuevas revisiones
Primer Modelo de Análisis de Sentimientos
Podemos desarrollar un modelo simple de MLP para predecir el sentimiento de las revisiones codificadas. El modelo tendrá una capa de entrada que iguala el número de palabras en el vocabulario y, a su vez, la longitud de los documentos de entrada. Podemos almacenar esto en una nueva variable llamada n_words, como sigue:
n_words = Xtest.shape[1]
Ahora podemos definir la red. Toda la configuración del modelo fue encontrada con muy poco ensayo y error y no debe ser considerada ajustada para este problema. Usaremos una sola capa oculta con 50 neuronas y una función de activación lineal rectificada. La capa de salida es una sola neurona con una función de activación sigmoide para predecir 0 para las revisiones negativas y 1 para las positivas. La red será entrenada utilizando la eficiente implementación de Adam de descenso en gradiente y la función binaria de pérdida de entropía cruzada, adecuada para problemas de clasificación binaria. Mantendremos un registro de la precisión cuando entrenemos y evaluemos el modelo.
# definir el modelo def define_model(n_words): # definir la red model = Sequential() model.add(Dense(50, input_shape=(n_words,), activation='relu')) model.add(Dense(1, activation='sigmoid')) # compilar red model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) # resumir el modelo definido model.summary() return model
A continuación, podemos ajustar el modelo a los datos de entrenamiento; en este caso, el modelo es pequeño y se ajusta fácilmente en 10 épocas.
# red adecuada model.fit(Xtrain, ytrain, epochs=10, verbose=2)
Finalmente, una vez que el modelo es entrenado, podemos evaluar su desempeño haciendo predicciones en el conjunto de datos de prueba e imprimiendo la precisión.
# evaluar
loss, acc = model.evaluate(Xtest, ytest, verbose=0)
print('Test Accuracy: %f' % (acc*100))
El ejemplo completo se enumera a continuación:
import string
import re
from os import listdir
from numpy import array
from nltk.corpus import stopwords
from keras.preprocessing.text import Tokenizer
from keras.utils.vis_utils import plot_model
from keras.models import Sequential
from keras.layers import Dense
# cargar doc en la memoria
def load_doc(filename):
# abrir el archivo como de sólo lectura
file = open(filename, 'r')
# leer todo el texto
text = file.read()
# cerrar el archivo
file.close()
return text
# convertir a doc en tokens limpios
def clean_doc(doc):
# dividido en tokens por espacio en blanco
tokens = doc.split()
# preparar a regex para el filtrado de caracteres
re_punc = re.compile('[%s]' % re.escape(string.punctuation))
# eliminar la puntuación de cada palabra
tokens = [re_punc.sub('', w) for w in tokens]
# eliminar los tokens restantes que no estén en orden alfabético
tokens = [word for word in tokens if word.isalpha()]
# filtrar las palabras de parada
stop_words = set(stopwords.words('english'))
tokens = [w for w in tokens if not w in stop_words]
# filtrar los tokens cortos
tokens = [word for word in tokens if len(word) > 1]
return tokens
# cargar doc, limpiar y retornar línea de tokens
def doc_to_line(filename, vocab):
# cargar doc
doc = load_doc(filename)
# limpiar doc
tokens = clean_doc(doc)
# filtrar por vocabulario
tokens = [w for w in tokens if w in vocab]
return ' '.join(tokens)
# cargar todos los documentos en un directorio
def process_docs(directory, vocab, is_train):
lines = list()
# revisar todos los archivos de la carpeta
for filename in listdir(directory):
# omita cualquier comentario en el juego de pruebas
if is_train and filename.startswith('cv9'):
continue
if not is_train and not filename.startswith('cv9'):
continue
# crear la ruta completa del archivo a abrir
path = directory + '/' + filename
# cargar y limpiar el documento
line = doc_to_line(path, vocab)
# añadir a la lista
lines.append(line)
return lines
# cargar y limpiar un conjunto de datos
def load_clean_dataset(vocab, is_train):
# cargar documentos
neg = process_docs('txt_sentoken/neg', vocab, is_train)
pos = process_docs('txt_sentoken/pos', vocab, is_train)
docs = neg + pos
# prepar labels
labels = array([0 for _ in range(len(neg))] + [1 for _ in range(len(pos))])
return docs, labels
# instalar un tokenizador
def create_tokenizer(lines):
tokenizer = Tokenizer()
tokenizer.fit_on_texts(lines)
return tokenizer
# definir el modelo
def define_model(n_words):
# definir la red
model = Sequential()
model.add(Dense(50, input_shape=(n_words,), activation='relu'))
model.add(Dense(1, activation='sigmoid'))
# compilar la red
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
# resumir el modelo definido
model.summary()
return model
# cargar el vocabulario
vocab_filename = 'vocab.txt'
vocab = load_doc(vocab_filename)
vocab = set(vocab.split())
# cargar todos los comentarios
train_docs, ytrain = load_clean_dataset(vocab, True)
test_docs, ytest = load_clean_dataset(vocab, False)
# crear el tokenizador
tokenizer = create_tokenizer(train_docs)
# codificador de datos
Xtrain = tokenizer.texts_to_matrix(train_docs, mode='freq')
Xtest = tokenizer.texts_to_matrix(test_docs, mode='freq')
# definir el modelo
n_words = Xtest.shape[1]
model = define_model(n_words)
# red adecuada
model.fit(Xtrain, ytrain, epochs=10, verbose=2)
# evaluar
loss, acc = model.evaluate(Xtest, ytest, verbose=0)
print('Precision del Test: %f' % (acc*100))
Al ejecutar el ejemplo primero se imprime un resumen del modelo definido.
_________________________________________________________________ Layer (type) Output Shape Param # ================================================================= dense_1 (Dense) (None, 50) 1288450 _________________________________________________________________ dense_2 (Dense) (None, 1) 51 ================================================================= Total params: 1,288,501 Trainable params: 1,288,501 Non-trainable params: 0 _________________________________________________________________
Un gráfico del modelo definido se guarda en un archivo con el nombre model.png.
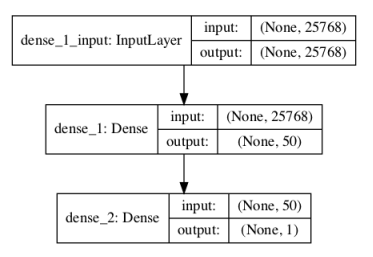
Podemos ver que el modelo se ajusta fácilmente a los datos de entrenamiento dentro de las 10 épocas, logrando una precisión cercana al 100%. Evaluando el modelo en el conjunto de datos de la prueba, podemos ver que el modelo funciona bien, logrando una precisión por encima del 85%, muy por debajo del valor aproximado de los niveles bajos a mediados de los 80 visto en el documento original. Sin embargo, es importante notar que esta no es una comparación de manzanas con manzanas, ya que el documento original usó una validación cruzada 10 veces mayor para estimar la habilidad del modelo en lugar de una sola división entrenamiento/prueba.
Dada la naturaleza estocástica de las redes neuronales, sus resultados específicos pueden variar. Considere la posibilidad de ejecutar el ejemplo varias veces.
... Epoch 7/10 - 1s - loss: 0.5221 - acc: 0.9444 Epoch 8/10 - 1s - loss: 0.4787 - acc: 0.9539 Epoch 9/10 - 1s - loss: 0.4370 - acc: 0.9567 Epoch 10/10 - 1s - loss: 0.3971 - acc: 0.9617 Precision del Test: 85.500000
A continuación, veamos cómo probar diferentes métodos de puntuación de palabras para el modelo de bolsa de palabras.
Comparación de métodos de valoración de palabras
La función texts_to_matrix() para el Tokenizer en la API de Keras proporciona 4 métodos diferentes para puntuar palabras;
- binario Donde las palabras están marcadas como presentes (1) o ausentes (0).
- Conteo Donde el conteo de ocurrencias para cada palabra está marcado como un número entero.
- tfidf Donde cada palabra es puntuada en base a su frecuencia, donde las palabras que son comunes a todos los documentos son penalizadas.
- freq Cuando las palabras se califican en base a su frecuencia de ocurrencia dentro del documento.
Podemos evaluar la habilidad del modelo desarrollado en la sección anterior usando cada uno de los 4 modos de puntuación de palabras soportados. Esto implica el desarrollo de una función para crear una codificación de los documentos cargados basada en un modelo de puntuación elegido. La función crea el tokenizer, lo encaja en los documentos de formación y, a continuación, crea el entrenamiento y prueba los encodings utilizando el modelo elegido. La función prepare_data() implementa este comportamiento con listas de documentos de entrenamiento y prueba.
# preparar la codificación de los documentos en bolsas de palabras def prepare_data(train_docs, test_docs, mode): # crear el tokenizer tokenizer = Tokenizer() # ajustar el tokenizador a los documentos tokenizer.fit_on_texts(train_docs) # codificar el conjunto de datos de formación Xtrain = tokenizer.texts_to_matrix(train_docs, mode=mode) # codificar el conjunto de datos de formación Xtest = tokenizer.texts_to_matrix(test_docs, mode=mode) return Xtrain, Xtest
También necesitamos una función para evaluar el MLP dada una codificación específica de los datos. Debido a que las redes neuronales son estocásticas, pueden producir resultados diferentes cuando el mismo modelo encaja en los mismos datos. Esto se debe principalmente a los pesos iniciales aleatorios y a la mezcla de patrones durante el descenso del gradiente de minilotes. Esto significa que cualquier puntuación de un modelo es poco fiable y debemos estimar la habilidad del modelo basándonos en un promedio de múltiples ejecuciones. La siguiente función, denominada evaluate_mode(), toma documentos codificados y evalúa la MLP entrenándola en el conjunto de ejercicios y estimando la habilidad en el conjunto de pruebas 10 veces y devuelve una lista de las puntuaciones de precisión en todas estas ejecuciones.
# evaluar un modelo de red neuronal
def evaluate_mode(Xtrain, ytrain, Xtest, ytest):
scores = list()
n_repeats = 30
n_words = Xtest.shape[1]
for i in range(n_repeats):
# definir red
model = Sequential()
model.add(Dense(50, input_shape=(n_words,), activation='relu'))
model.add(Dense(1, activation='sigmoid'))
# compilar red
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
# fit network
model.fit(Xtrain, ytrain, epochs=10, verbose=2)
# evaluar
loss, acc = model.evaluate(Xtest, ytest, verbose=0)
scores.append(acc)
print('%d precision: %s'% ((i+1), acc))
return scores
Ahora estamos listos para evaluar el rendimiento de los 4 diferentes métodos de puntuación de palabras. Juntando todo esto, el ejemplo completo se muestra a continuación.
import string
import re
from os import listdir
from numpy import array
from nltk.corpus import stopwords
from keras.preprocessing.text import Tokenizer
from keras.models import Sequential
from keras.layers import Dense
from pandas import DataFrame
from matplotlib import pyplot
# carga doc en la memoria
def load_doc(filename):
# abrir el archivo como de sólo lectura
file = open(filename,'r')
# leer todo el texto
text = file.read()
# cerrar el archivo
file.close()
return text
# convertir a un médico en tokens limpias
def clean_doc(doc):
# dividido en tokens por espacio en blanco
tokens = doc.split()
# preparar a regex para el filtrado de caracteres
re_punc = re.compile('[%s]'% re.escape(string.punctuation))
# eliminar la puntuación de cada palabra
tokens = [re_punc.sub('', w) for w in tokens]
# eliminar los tokens restantes que no estén en orden alfabético
tokens = [word for word in tokens if word.isalpha()]
# filtrar las palabras de parada
stop_words = set(stopwords.words('english'))
tokens = [w for w in tokens if not w in stop_words]
# filtrar los tokens cortos
tokens = [word for word in tokens if len(word) > 1]
return tokens
# doc de carga, limpieza y línea de retorno de las tokens
def doc_to_line(filename, vocab):
# cargar el documento
doc = load_doc(filename)
# expediente limpio
tokens = clean_doc(doc)
# filtrar por vocabulario
tokens = [w for w in tokens if w in vocab]
return''.join(tokens)
# cargar todos los documentos en un directorio
def process_docs(directory, vocab, is_train):
lines = list()
# revisar todos los archivos de la carpeta
for filename in listdir(directory):
# omita cualquier comentario en el juego de pruebas
if is_train and filename.startswith('cv9'):
continue
if not is_train and not filename.startswith('cv9'):
continue
# crear la ruta completa del archivo a abrir
path = directory +'/'+ filename
# cargar y limpiar el documento
line = doc_to_line(path, vocab)
# añadir a la lista
lines.append(line)
return lines
# cargar y limpiar un conjunto de datos
def load_clean_dataset(vocab, is_train):
# cargar documentos
neg = process_docs('txt_sentoken/neg', vocab, is_train)
pos = process_docs('txt_sentoken/pos', vocab, is_train)
docs = neg + pos
# preparar las etiquetas
labels = array([0 for _ in range(len(neg))] + [1 for _ in range(len(pos))])
return docs, labels
# definir el modelo
def define_model(n_words):
# definir la red
model = Sequential()
model.add(Dense(50, input_shape=(n_words,), activation='relu'))
model.add(Dense(1, activation='sigmoid'))
# compilar red
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
return model
# evaluar un modelo de red neuronal
def evaluate_mode(Xtrain, ytrain, Xtest, ytest):
scores = list()
n_repeats = 10
n_words = Xtest.shape[1]
for i in range(n_repeats):
# definir la red
model = define_model(n_words)
# red adecuada
model.fit(Xtrain, ytrain, epochs=10, verbose=0)
# evaluar
_, acc = model.evaluate(Xtest, ytest, verbose=0)
scores.append(acc)
print('%d precision: %s'% ((i+1), acc))
return scores
# preparar la bolsa de palabras que codifican los documentos
def prepare_data(train_docs, test_docs, mode):
# crear el tokenizador
tokenizer = Tokenizer()
# ajustar el tokenizador a los documentos
tokenizer.fit_on_texts(train_docs)
# codificar el conjunto de datos de formación
Xtrain = tokenizer.texts_to_matrix(train_docs, mode=mode)
# codificar el conjunto de datos de formación
Xtest = tokenizer.texts_to_matrix(test_docs, mode=mode)
return Xtrain, Xtest
# cargar el vocabulario
vocab_filename ='vocab.txt'
vocab = load_doc(vocab_filename)
vocab = set(vocab.split())
# cargar todos los comentarios
train_docs, ytrain = load_clean_dataset(vocab, True)
test_docs, ytest = load_clean_dataset(vocab, False)
# experimento de ejecución
modes = ['binary','count','tfidf','freq']
results = DataFrame()
for mode in modes:
# preparar los datos para el modo
Xtrain, Xtest = prepare_data(train_docs, test_docs, mode)
# evaluar el modelo sobre los datos para el modo
results[mode] = evaluate_mode(Xtrain, ytrain, Xtest, ytest)
# resumir los resultados
print(results.describe())
# resultados de gráficos
results.boxplot()
pyplot.show()
Al final de la ejecución, se proporcionan estadísticas resumidas para cada método de puntuación de palabras, resumiendo la distribución de las puntuaciones de habilidades del modelo en cada una de las 10 ejecuciones por modo. Podemos ver que la puntuación media tanto del método de recuento como del método binario parece ser mejor que la de freq y tfidf.
Dada la naturaleza estocástica de las redes neuronales, sus resultados específicos pueden variar. Considere la posibilidad de ejecutar el ejemplo varias veces.
binary count tfidf freq count 10.000000 10.000000 10.000000 10.000000 mean 0.927000 0.903500 0.876500 0.871000 std 0.011595 0.009144 0.017958 0.005164 min 0.910000 0.885000 0.855000 0.865000 25% 0.921250 0.900000 0.861250 0.866250 50% 0.927500 0.905000 0.875000 0.870000 75% 0.933750 0.908750 0.888750 0.875000 max 0.945000 0.915000 0.910000 0.880000
También se presenta un gráfico de caja y margenes de los resultados, resumiendo las distribuciones de precisión por configuración. Podemos ver que el binario obtuvo los mejores resultados con una dispersión modesta y podría ser el enfoque preferido para este conjunto de datos.
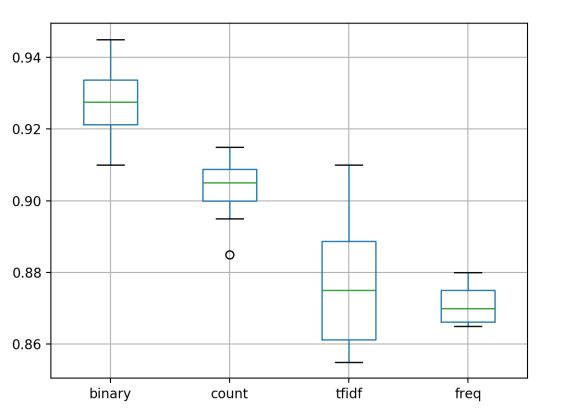
Prediciendo Sentimientos para Nuevas Revisiones
Finalmente, podemos desarrollar y utilizar un modelo final para hacer predicciones para nuevas revisiones textuales. Por eso queríamos el modelo en primer lugar. Primero entrenaremos un modelo final sobre todos los datos disponibles. Usaremos el modo binario para puntuar el modelo de bolsa de palabras que se ha demostrado que da los mejores resultados en la sección anterior.
Predecir el sentimiento de nuevas revisiones implica seguir los mismos pasos utilizados para preparar los datos de la prueba. Específicamente, cargar el texto, limpiar el documento, filtrar los tokens por el vocabulario elegido, convertir los tokens restantes en una línea, codificarlos usando el Tokenizer, y hacer una predicción. Podemos hacer una predicción de un valor de clase directamente con el modelo de ajuste llamando a predict() que devolverá un número entero de 0 para una revisión negativa y 1 para una revisión positiva. Todos estos pasos se pueden poner en una nueva función llamada predict_sentiment() que requiere el texto de revisión, el vocabulario, el tokenizer y el modelo de ajuste, y devuelve el sentimiento predicho y un porcentaje asociado o un resultado similar a la confianza.
# clasificar una crítica como negativa o positiva
def predict_sentiment(review, vocab, tokenizer, model):
# pulir
tokens = clean_doc(review)
# filtrar por vocabulario
tokens = [w for w in tokens if w in vocab]
# convertir a línea
line =''.join(tokens)
# codificar
encoded = tokenizer.texts_to_matrix([line], mode='binary')
# predecir el sentimiento
yhat = model.predict(encoded, verbose=0)
# recuperar el porcentaje previsto y etiquetar
percent_pos = yhat[0,0]
if round(percent_pos) == 0:
return (1-percent_pos),'NEGATIVE'
return percent_pos,'POSITIVE'
Ahora podemos hacer predicciones para nuevos textos de revisión. A continuación se muestra un ejemplo con una revisión claramente positiva y otra claramente negativa utilizando el simple MLP desarrollado anteriormente con el modo de puntuación de palabras de frecuencia.
#texto positivo
text ='Best movie ever! It was great, I recommend it.'
percent, sentiment = predict_sentiment(text, vocab, tokenizer, model)
print('Review: [%s]\nSentiment: %s (%.3f%%)'% (text, sentiment, percent*100))
# texto negativo
text ='This is a bad movie.'
percent, sentiment = predict_sentiment(text, vocab, tokenizer, model)
print('Review: [%s]\nSentiment: %s (%.3f%%)'% (text, sentiment, percent*100))
Juntando todo esto, el ejemplo completo para hacer predicciones para nuevas revisiones se enumera a continuación.
import string
import re
from os import listdir
from numpy import array
from nltk.corpus import stopwords
from keras.preprocessing.text import Tokenizer
from keras.models import Sequential
from keras.layers import Dense
# cargamos el documento
def load_doc(filename):
# abre el archivo solo para leer
file = open(filename, 'r')
# lee todo el texto
text = file.read()
# cierra el archivo
file.close()
return text
# cambia el documento a token filtrados
def clean_doc(doc):
# dividir en token por espacios
tokens = doc.split()
# exp regulares para filtar caracteres
re_punc = re.compile('[%s]' % re.escape(string.punctuation))
# eliminamos puntacion de cada palabra
tokens = [re_punc.sub('', w) for w in tokens]
# remove remaining tokens that are not alphabetic
tokens = [word for word in tokens if word.isalpha()]
# filter out stop words
stop_words = set(stopwords.words('english'))
tokens = [w for w in tokens if not w in stop_words]
# filter out short tokens
tokens = [word for word in tokens if len(word) > 1]
return tokens
# carga doc, limpieza y devuelve linea de tokens
def doc_to_line(filename, vocab):
# carga del doc
doc = load_doc(filename)
# limpieza del doc
tokens = clean_doc(doc)
# filtro del vocab
tokens = [w for w in tokens if w in vocab]
return ' '.join(tokens)
# cargamos los doc en el directorio
def process_docs(directory, vocab):
lines = list()
# recorremos los archivos de la carpeta
for filename in listdir(directory):
# crea la ruta completa del archivo para abrir
path = directory + '/' + filename
# carga and limpeza del doc
line = doc_to_line(path, vocab)
# añadimos a la lista
lines.append(line)
return lines
# carga and limpeza del dataset
def load_clean_dataset(vocab):
# cargamos documentos
neg = process_docs('txt_sentoken/neg', vocab)
pos = process_docs('txt_sentoken/pos', vocab)
docs = neg + pos
# preparacion de etiquetas
labels = array([0 for _ in range(len(neg))] + [1 for _ in range(len(pos))])
return docs, labels
# ajuste del tokenizer
def create_tokenizer(lines):
tokenizer = Tokenizer()
tokenizer.fit_on_texts(lines)
return tokenizer
# definimos el modelo
def define_model(n_words):
# definimos la network
model = Sequential()
model.add(Dense(50, input_shape=(n_words,), activation='relu'))
model.add(Dense(1, activation='sigmoid'))
# compilamos la network
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
# sumarizamos el modelo definido
model.summary()
#plot_model(model, to_file='model.png', show_shapes=True)
return model
# clasificacion de criticas como negativa o positiva
def predict_sentiment(review, vocab, tokenizer, model):
# limpio
tokens = clean_doc(review)
# filtro del vocabulario
tokens = [w for w in tokens if w in vocab]
# convertimos a linea
line = ' '.join(tokens)
# encode
encoded = tokenizer.texts_to_matrix([line], mode='binary')
# prediccion del sentimento
yhat = model.predict(encoded, verbose=0)
# recuperamos el % predicho por la etiqueta
percent_pos = yhat[0,0]
if round(percent_pos) == 0:
return (1-percent_pos), 'NEGATIVO'
return percent_pos, 'POSITIVO'
# cargamos el vocabulario
vocab_filename = 'vocab.txt'
vocab = load_doc(vocab_filename)
vocab = set(vocab.split())
# cargamos todas las criticas
train_docs, ytrain = load_clean_dataset(vocab)
test_docs, ytest = load_clean_dataset(vocab)
# creacion del tokenizer
tokenizer = create_tokenizer(train_docs)
# encode de data
Xtrain = tokenizer.texts_to_matrix(train_docs, mode='binary')
Xtest = tokenizer.texts_to_matrix(test_docs, mode='binary')
# define la network
n_words = Xtrain.shape[1]
model = define_model(n_words)
# ajuste de la network
model.fit(Xtrain, ytrain, epochs=10, verbose=2)
# test texto positivo
text = 'Best movie ever! It was great, I recommend it.'
percent, sentiment = predict_sentiment(text, vocab, tokenizer, model)
print('Cristica: [%s]\nSentimento: %s (%.3f%%)' % (text, sentiment, percent*100))
# test texto negativo
text = 'This is a bad movie.'
percent, sentiment = predict_sentiment(text, vocab, tokenizer, model)
print('Critica: [%s]\nSentimento: %s (%.3f%%)' % (text, sentiment, percent*100))
Ejecutando el ejemplo correctamente clasifica estas revisiones.
Critica: [Best movie ever! It was great, I recommend it.] Sentimento: POSITIVO (57.524%) Critica: [This is a bad movie.] Sentimento: NEGATIVO (64.7404%)
Idealmente, encajaríamos el modelo en todos los datos disponibles (entrenamiento y prueba) para crear un modelo final y guardar el modelo y el tokenizer en un archivo para que puedan ser cargados y utilizados en un nuevo software.
Extensiones
Esta sección enumera algunas extensiones si desea obtener más de este tutorial.
- Manejar el vocabulario. Explore usando un vocabulario más grande o más pequeño. Tal vez pueda obtener un mejor rendimiento con un conjunto más pequeño de palabras.
- Ajuste la topología de la red. Explore topologías de red alternativas, como redes más profundas o más amplias. Tal vez pueda obtener un mejor rendimiento con una red más adecuada.
- Usar Regularización. Explore el uso de técnicas de regularización, como la deserción. Tal vez pueda retrasar la convergencia del modelo y lograr un mejor rendimiento del equipo de prueba.
- Más limpieza de datos. Explore más o menos la limpieza del texto de revisión y vea cómo afecta la habilidad del modelo.
- Diagnóstico de formación. Utilice el conjunto de datos de prueba como conjunto de datos de validación durante la formación y cree diagramas de pérdidas de entrenamiento y de prueba. Utilice estos diagnósticos para ajustar el tamaño del lote y el número de épocas de formación.
- Palabras desencadenantes. Explore si hay palabras específicas en las críticas que sean altamente predictivas del sentimiento.
- Usa Bigrams. Preparar el modelo para calificar bigrams de palabras y evaluar el desempeño bajo diferentes esquemas de calificación.
- Revisiones truncadas. Explore cómo el uso de una versión truncada de los resultados de las críticas de películas impacta la habilidad del modelo, intente truncar el comienzo, el final y la mitad de las críticas.
- Modelos de conjuntos. Crear modelos con diferentes esquemas de puntuación de palabras y ver si el uso de conjuntos de los modelos resulta en una mejora de la habilidad del modelo.
- Críticas de este año. Entrenar un modelo final con todos los datos y evaluar el modelo con las críticas de películas de este año tomadas de Internet.
Si exploras alguna de estas extensiones, me encantaría saberlo.
➡ Continúa aprendiendo de Procesamiento de Lenguaje Natural en nuestro curso: