
Blog
Mejores Lenguajes, Librerías y Softwares para Data Science

Una de las mejores cosas de trabajar como Data Scientist es que este campo esta lleno de herramientas libres. La comunidad Data Science es, en general, bastante abierta y generosa, y muchas de las herramientas que se utilizan todos los días son completamente gratuitas.
Sin embargo, si acabas de empezar, la lista de recursos disponibles puede ser demasiado larga. Así que nos vamos a centrar en una lista de recursos de código abierto que todo Data Scientist debe dominar, las mejores herramientas gratuitas para Data Science:
Lenguajes de programación
Los lenguajes de programación son realmente las mejores herramientas gratuitas para el trabajo en Data Science. El simple hecho de aprender uno de estos lenguajes pone un tremendo poder analítico a tu alcance. Los tres mejores lenguajes de programación para un Data Scientist son:
- R
- Python
- SQL
Encontrarás cientos de artículos que tratan de separar qué Python y R son mejores para Data Science. Desde Unipython pensamos que si te interesa el mundo de la ciencia de datos y tienes intención de meterte en este campo recomendamos Python por diversas razones:
- Lenguaje más completo
- Mucha más información en internet
- Fácil de aprender
- Numerosas librerías en el campo de Data Science
- Mejor lenguaje para aplicar y desarrollar algoritmos de machine learning e IA (inteligencia artificial)
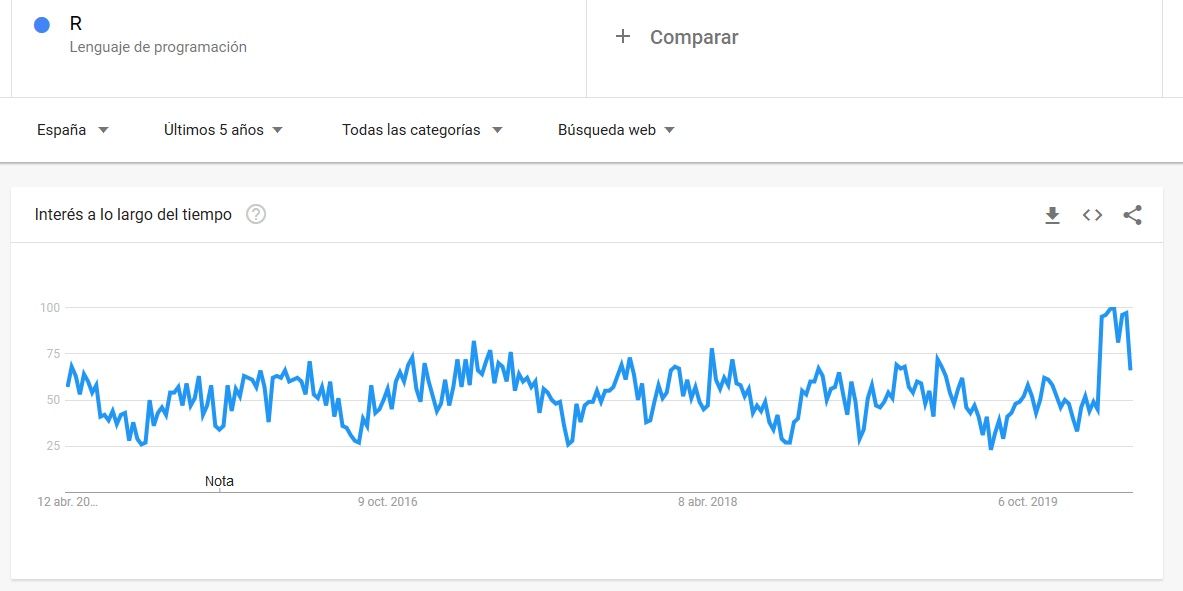
Hemos realizado una búsqueda en google trend para ver las tendencias de estos dos lenguajes en los ultimos 5 años:
Lenguaje R:
 Lenguaje Python:
Lenguaje Python:
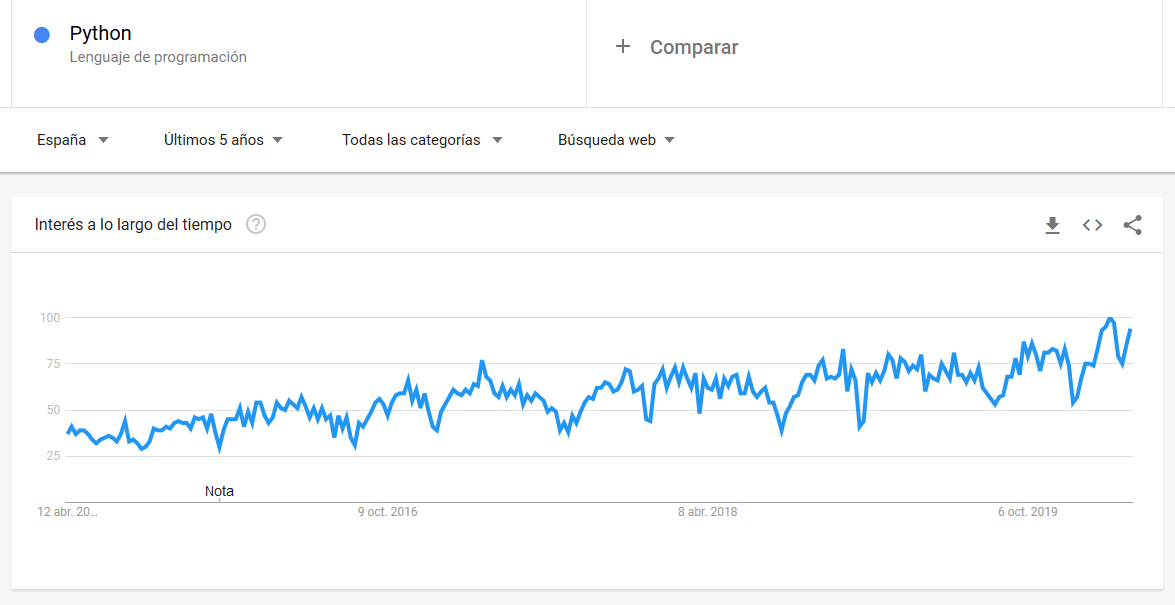
A partir de estas tendencias podemos ver que R es un lenguaje estable en el tiempo con una media de 55 puntos de interés en las búsquedas de google. También comentar que en los 3 últimos meses ha ganado popularidad (quizás esto puede ser debido al covid19). Por otro lado vemos que Python tiene una tendencia creciente lo cual significa que cada vez más este lenguaje es más popular. Al igual que R, python ha ganado popularidad en los últimos meses, también comentar que python no es solo un lenguaje para Data Science sino también para desarrollo web entre otros ámbitos.
La realidad es que ambas son grandes opciones y cada una con sus respectivas fortalezas. Si estás empezando, es mejor elegir cualquiera de los dos y empezar a aprender, en lugar de perder el tiempo tratando de averiguar cuál es el mejor.
SQL, por otro lado, es más complementario tanto a Python como a R. Puede que no sea el primer idioma que aprendas, pero tendrás que aprenderlo.
1. R
El lenguaje de programación R fue creado inicialmente a mediados de los 90. R es el lenguaje estadístico preferido en todo el mundo académico y tiene la reputación de ser fácil de aprender, especialmente para aquellos que nunca antes han usado un lenguaje de programación.
Un beneficio clave del lenguaje R es que fue diseñado principalmente para la computación estadística, por lo que muchas de las características clave que los científicos de datos necesitan están incorporadas.
R también tiene un fuerte ecosistema de paquetes que permiten capacidades extendidas. Hay varios paquetes R que son considerados por muchos como esenciales si se trabaja con datos.
2. Python
Al igual que R, Python también fue creado en los años 90. Pero a diferencia de R, Python es un lenguaje de programación de propósito general. Se usa a menudo para el desarrollo web, y es uno de los lenguajes de programación general más populares.
El uso de Python para el trabajo de ciencias de los datos comenzó a hacerse popular a mediados y finales de los años 90, después de que surgieran bibliotecas especializadas (análogas a los paquetes R) que proporcionaban una mejor funcionalidad para trabajar con datos. Durante la última década, el uso de Python como lenguaje de ciencias de los datos ha crecido enormemente, y ahora es el lenguaje más popular para Data Science según algunas métricas.
Uno de los beneficios clave de Python es que, al ser un lenguaje de propósito general, es más fácil realizar tareas generales que se cruzan con su trabajo de datos. Del mismo modo, si aprendes Python y más tarde decides que el desarrollo de software se ajusta mejor a ti que la ciencia de los datos, mucho de lo que has aprendido es transferible.
3. SQL
SQL es un lenguaje complementario a Python y R. A menudo será el segundo lenguaje que alguien aprenda si quiere entrar en la ciencia de los datos. SQL es un lenguaje usado para interactuar con datos almacenados en bases de datos.
Debido a que la mayoría de los datos del mundo se almacenan en bases de datos, el SQL es un lenguaje increíblemente valioso para aprender. Es común que los científicos de datos usen SQL para recuperar datos que luego limpiarán y analizarán usando Python o R.
Muchas empresas también utilizan SQL como un lenguaje de análisis de “primera clase”, utilizando herramientas que permiten construir visualizaciones e informes directamente a partir de los resultados de las consultas SQL.
Librerías de Python para Data Science
Python tiene una gran diversidad de librerías en el campo de Data Science.
Los paquetes Python pueden descargarse de PyPI (el Índice de Paquetes Python) utilizando pip, una herramienta que viene con Python pero que es externa al entorno de codificación de Python.
Pandas
Pandas es una biblioteca de software escrita para el lenguaje de programación Python para la manipulación y análisis de datos. En particular, ofrece estructuras de datos y operaciones para manipular tablas numéricas y series de tiempo. Es un software gratuito lanzado bajo la licencia BSD. El nombre se deriva del término “datos de panel”, un término econométrico para conjuntos de datos que incluyen observaciones durante varios períodos de tiempo para los mismos individuos. Características de la biblioteca pandas:
- Uso de bbjetos DataFrame para la manipulación de datos.
- Herramientas para leer y escribir datos entre estructuras de datos en memoria y diferentes formatos de archivo.
- Alineación de datos y manejo integrado de datos faltantes.
- Reforma y pivote de conjuntos de datos.
- Etiquetación, indexación elegante y subconjunto de grandes conjuntos de datos.
- Estructura de datos de inserción y eliminación de columnas.
- Agrupación por motor permitiendo operaciones dividir-aplicar-combinar en conjuntos de datos.
- Conjunto de datos de fusión y unión.
- Funcionalidad de series de tiempo: generación de rango de fechas, conversión de frecuencia y regresiones lineales
- Proporciona filtración de datos.
Dataframes
Pandas se utiliza principalmente para el machine learning en forma de Dataframes. Pandas permite importar datos de varios formatos de archivo, como csv, excel, etc. Pandas permite diversas operaciones de manipulación de datos como groupby, join, merge, melt, concatenation, así como características de limpieza de datos como rellenar, reemplazar o imponer valores nulos.
NumPy
NumPy es una biblioteca fundamental de Python que proporciona funcionalidad para la computación científica. NumPy proporciona parte de la lógica central sobre la que se construyen los dataframes de pandas. Normalmente, la mayoría de los científicos de datos trabajarán con pandas, pero conocer NumPy es importante ya que permite acceder a algunas de las funciones centrales cuando es necesario.
Matplotlib
La biblioteca de Matplotlib es una poderosa biblioteca de gráficos para Python. Los científicos de datos a menudo usan el módulo Pyplot de la biblioteca, que proporciona una interfaz estándar para trazar datos.
La funcionalidad de trazado que se incluye en pandas llama a Matplotlib, por lo que entender matplotlib ayuda a personalizar las gráficas que se hacen en pandas.
Scikit-Learn
Scikit-learn es la biblioteca de machine learning más popular para Python. La biblioteca proporciona un conjunto de herramientas construidas sobre NumPy y Matplotlib que permiten la preparación y el entrenamiento de los modelos de aprendizaje automático.
Los tipos de modelos disponibles incluyen la clasificación, la regresión, la agrupación y la reducción de la dimensionalidad.
Tensorflow
Tensorflow es una biblioteca de Python originalmente desarrollada por Google que proporciona una interfaz y un framework para trabajar con las redes neuronales y el Deep learning.
Tensorflow es ideal para tareas en las que sobresale el machine learning, como la visión por ordenador, el procesamiento del lenguaje natural, el reconocimiento de audio/vídeo y más.
Software para Data Science
Hasta ahora, hemos buscado los mejores lenguajes para la ciencia de los datos y sus mejores librerías.
A continuación, veremos algunas herramientas de software que son útiles para el trabajo como Data Scientist. No todas son de código abierto, pero son gratuitas para que cualquiera las use, y si se trabaja con datos de forma regular pueden ahorrar mucho tiempo.
Google Sheets
Si esta no fuera una lista de herramientas gratuitas, entonces sin duda Microsoft Excel estaría en la parte superior de esta lista. El omnipresente software de hoja de cálculo hace que sea rápido y fácil trabajar con los datos de una manera visual, y es utilizado por millones de personas en todo el mundo.
El clon de Google Excel tiene la funcionalidad principal de Excel, y está disponible gratuitamente para cualquiera con una cuenta de Google.
Jupyter Notebook
El Jupyter Notebook es el entorno más popular para trabajar con Python para la ciencia de los datos. Jupyter permite combinar código, texto y gráficos en un solo documento, lo que facilita el trabajo con los datos.
Jupyter se puede exportar en varios formatos, incluyendo HTML, PDF y más.
Anaconda
Anaconda es una distribución de Python diseñada específicamente para ayudar a instalar las herramientas científicas de Python. Antes de Anaconda, la única opción era instalar Python por sí mismo, y luego instalar paquetes como NumPy, pandas, Matplotlib uno por uno. Lo que no siempre era un proceso sencillo, y a menudo era difícil para los nuevos estudiantes.
Anaconda incluye todos los principales paquetes necesarios para la ciencia de los datos en una instalación sencilla, lo que ahorra tiempo y permite empezar rápidamente. También tiene incorporado Jupyter Notebook y hace que el inicio de un nuevo proyecto de Data Science sea fácilmente accesible con su editor Sypder. Es la forma recomendada de empezar a usar Python en el campo de Data Science.