
Blog
Gráficos Dinámicos para Sentimientos – GUI de Análisis de Sentimientos con Dash y Python p.4
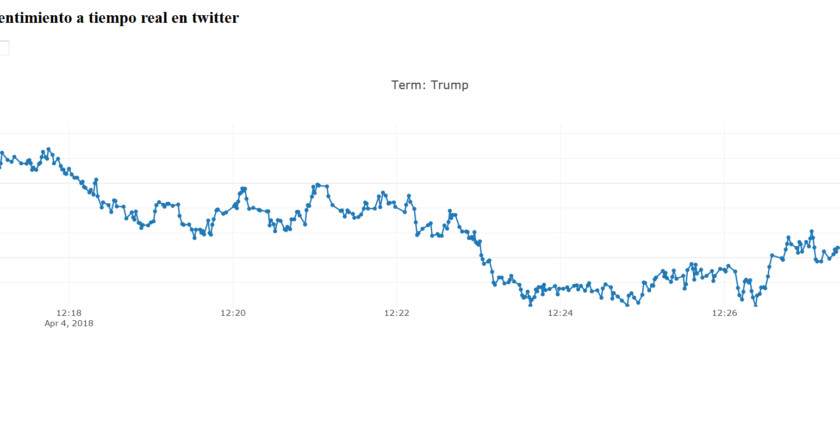
-Vamos a aprender a utilizar la GUI (interfaz gráfica) para escribir cualquier palabra a rastrear en Twitter y realizar la gráfica a tiempo real.
Bienvenido a la parte 4 de nuestra aplicación de análisis de sentimientos con el tutorial de Dash en Python. Hasta este punto, tenemos el seguimiento de la aplicación a tiempo real, pero lo que nos gustaría poder hacer es usar la interfaz de usuario para escribir cualquier palabra(s) que queramos rastrear en twitter.
Para ello, primero tenemos que añadir un campo de entrada en nuestra maqueta:
dcc.Input(id='sentimiento_term', value='usa', type='text'),
Dentro de:
app.layout = html.Div(
[ html.H2('Gráfica de sentimiento a tiempo real en Twitter'),
dcc.Input(id='sentimiento_term', value='usa', type='text'),
dcc.Graph(id='live-graph', animate=False),
dcc.Interval(
id='graph-update',
interval=1*1000
),
]
)
Nuestra anterior llamada fue sólo por el intervalo de actualización y la salida al gráfico de tiempo real. Ahora queremos incluir la entrada:
@app.callback(Output('live-graph', 'figure'),
[Input(component_id='sentimiento_term', component_property='value')],
events=[Event('graph-update', 'interval')])
Ahora pasamos este input a la función que la envuelve:
def update_graph_scatter(sentimiento_term):
A continuación, queremos que nuestra consulta utilice el término escrito en el cuadro de búsqueda. Dicho esto, tenemos que tener cuidado con la inyección SQL. Nunca confíes en tus usuarios. Incluso si el 99,99% de sus usuarios son bien intencionados. SQLite ofrece algunas opciones para hacer esto, pero también estamos intentando usar Pandas. Afortunadamente, pandas también tienen soporte para parámetros. He aquí un ejemplo, usando nuestra variable:
df = pd.read_sql("SELECT * FROM sentimiento WHERE tweet LIKE ? ORDER BY unix DESC LIMIT 1000", conn ,params=('%' + sentimiento_term + '%',))
Combinando lo explicado tenemos:
import dash
from dash.dependencies import Output, Event, Input
import dash_core_components as dcc
import dash_html_components as html
import plotly
import random
import plotly.graph_objs as go
from collections import deque
import sqlite3
import pandas as pd
import time
#popular topics: google, olympics, trump, gun, usa
app = dash.Dash(__name__)
app.layout = html.Div(
[ html.H2('Gráfico de sentimiento a tiempo real en twitter'),
dcc.Input(id='sentimiento_term', value='usa', type='text'),
dcc.Graph(id='live-graph', animate=False),
dcc.Interval(
id='graph-update',
interval=1*1000
),
]
)
@app.callback(Output('live-graph', 'figure'),
[Input(component_id='sentimiento_term', component_property='value')],
events=[Event('graph-update', 'interval')])
def update_graph_scatter(sentimiento_term):
try:
conn = sqlite3.connect('twitterF1.db')
c = conn.cursor()
df = pd.read_sql("SELECT * FROM sentimiento WHERE tweet LIKE '%usa%' ORDER BY unix DESC LIMIT 1000", conn ,params=('%' + sentimiento_term + '%',))
df.sort_values('unix', inplace=True)
df['sentimiento_smoothed'] = df['sentimiento'].rolling(int(len(df)/5)).mean()
df.dropna(inplace=True)
X = df.unix.values[-100:]
Y = df.sentimiento_smoothed.values[-100:]
data = plotly.graph_objs.Scatter(
x=X,
y=Y,
name='Scatter',
mode= 'lines+markers'
)
return {'data': [data],'layout' : go.Layout(xaxis=dict(range=[min(X),max(X)]),
yaxis=dict(range=[min(Y),max(Y)]),
title='Term: {}'.format(sentimiento_term))}
except Exception as e:
with open('errors.txt','a') as f:
f.write(str(e))
f.write('\n')
if __name__ == '__main__':
app.run_server(debug=True)
Vale, en este punto, estamos en un comienzo bastante decente. Al menos para mí, esto funciona bastante bien. Para un sentimiento a tiempo real, retroceder ~1000 puntos de datos debería ser más que suficiente. Ahora mismo, estamos sacando 1.000 puntos de datos, usando un 200MA (si hay 1.000 puntos de datos), y luego mostrando sólo los últimos 100. Esto es probablemente inútil, así que en vez de mantener la consulta lo más pequeña posible, podríamos hacerlo:
df = pd.read_sql("SELECT * FROM sentimiento WHERE tweet LIKE '%usa%' ORDER BY unix DESC LIMIT 200", conn ,params=('%' + sentimiento_term + '%',))
Al menos por ahora, esto tiene más sentido. Nuestros sellos de tiempo Unix tampoco son atractivos en absoluto. Podemos arreglarlo:
df['date'] = pd.to_datetime(df['unix'],unit='ms')
df.set_index('date', inplace=True)
Ahora, podemos hacerlo nosotros:
conn = sqlite3.connect('twitterF1.db')
c = conn.cursor()
df = pd.read_sql("SELECT * FROM sentimiento WHERE tweet LIKE '%usa%' ORDER BY unix DESC LIMIT 200", conn ,params=('%' + sentimiento_term + '%',))
df.sort_values('unix', inplace=True)
df['sentimiento_smoothed'] = df['sentimiento'].rolling(int(len(df)/2)).mean()
df['date'] = pd.to_datetime(df['unix'],unit='ms')
df.set_index('date', inplace=True)
df.dropna(inplace=True)
X = df.index
Y = df.sentimiento_smoothed
Dando como resultado:
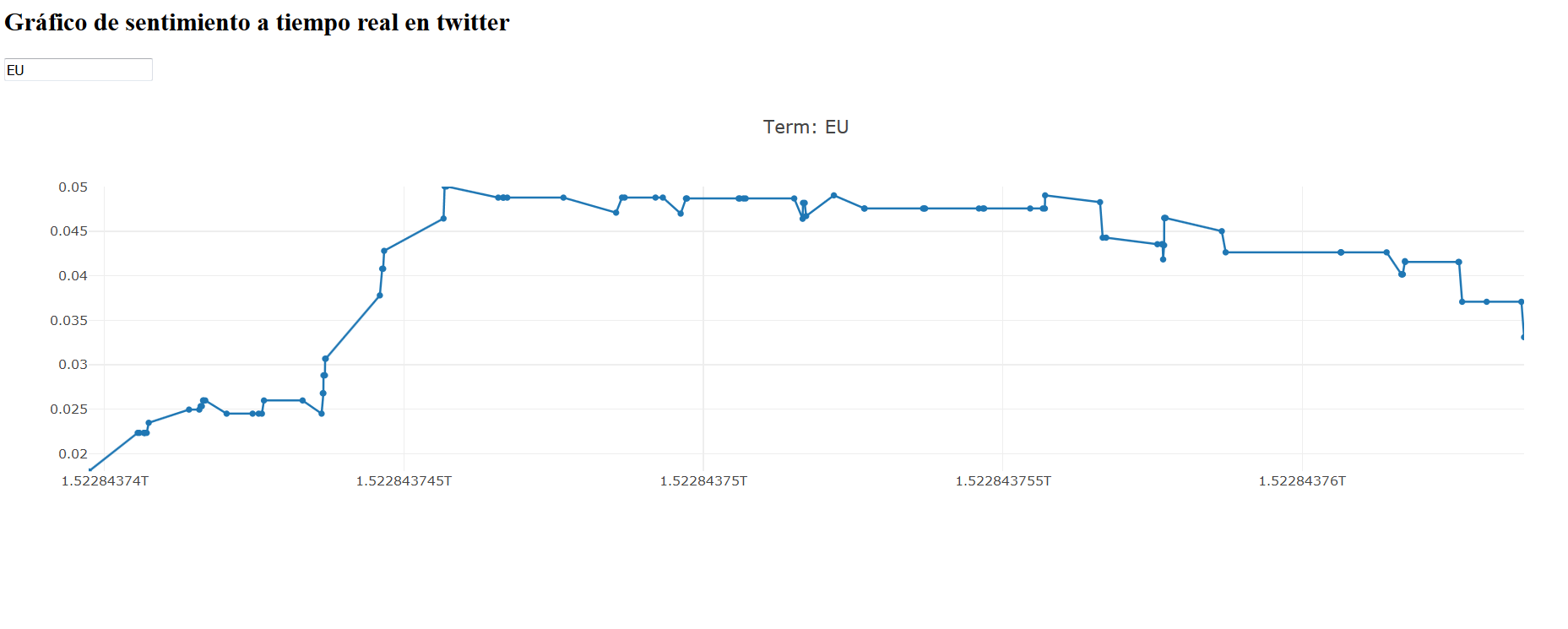
¿Y si quisiéramos retroceder más? Digamos que quisiéramos mostrar 10.000 puntos de datos, ya sea porque el término es alto volumen/queremos más historia?
Realmente no deberíamos estar trazando más de unos pocos cientos de puntos de datos en un gráfico en vivo, por lo que esto tendrá un impacto significativo en el rendimiento. Una opción que tenemos es usar la nueva muestra de Pandas. Podríamos remuestrear a un segundo con:
df = df.resample('1s').mean()
La función completa sería:
@app.callback(Output('live-graph', 'figure'),
[Input(component_id='sentimiento_term', component_property='value')],
events=[Event('graph-update', 'interval')])
def update_graph_scatter(sentimiento_term):
try:
conn = sqlite3.connect('twitterF1.db')
c = conn.cursor()
df = pd.read_sql("SELECT * FROM sentimiento WHERE tweet LIKE ? ORDER BY unix DESC LIMIT 1000", conn ,params=('%' + sentimiento_term + '%',))
df.sort_values('unix', inplace=True)
df['sentimiento_smoothed'] = df['sentimiento'].rolling(int(len(df)/2)).mean()
df['date'] = pd.to_datetime(df['unix'],unit='ms')
df.set_index('date', inplace=True)
df = df.resample('1min').mean()
df.dropna(inplace=True)
X = df.index
Y = df.sentimiento_smoothed
data = plotly.graph_objs.Scatter(
x=X,
y=Y,
name='Scatter',
mode= 'lines+markers'
)
return {'data': [data],'layout' : go.Layout(xaxis=dict(range=[min(X),max(X)]),
yaxis=dict(range=[min(Y),max(Y)]),
title='Term: {}'.format(sentimiento_term))}
except Exception as e:
with open('errors.txt','a') as f:
f.write(str(e))
f.write('\n')
Sin la nueva muestra:

Con la nueva muestra:

¡Felicidades! Has llegado al final del Curso de Dash en Python. Te felicitamos por haber culminado el curso. Te invitamos a seguir navegando en mi web Unipython.com, para que descubras otros cursos!