
Blog
Entrevista de 24 preguntas y respuestas sobre Deep Learning para Entrevistas

Es importante que, cuando acudimos a una entrevista de trabajo de Deep Learning, nos preparemos lo mejor posible para lograr alcanzar el éxito. Por ello, a continuación hemos dejado una selección de preguntas y respuestas frecuentes en una entrevista de Deep Learning. Comprende desde conceptos básicos hasta preguntas más avanzadas. Si eres novato o principiante, de todas formas te van a servir de mucho.
La función de costo, es la de darnos a entender corno se ha desempeñando la red neural. El objetivo es conseguir parámetros que disminuyan la función de coste. Un ejemplo de una función de costo, es considerar la función de error promedio al cuadrado:
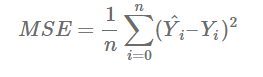 La media de las diferencias cuadradas en una predicción Y^ y el valor deseado Y es lo que se quiere disminuir.
La media de las diferencias cuadradas en una predicción Y^ y el valor deseado Y es lo que se quiere disminuir.
Es un algoritmo iterativo de optimización que se usa en el machine learning para conocer los valores de parámetros que bajan la función de coste. En cada iteración, se calcula el gradiente de función de coste con respecto a los parámetros y se actualiza los parámetros de la función a través de.
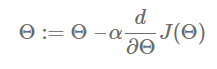
Θ - es el parámetro vector, α - tasa de aprendizaje, J(Θ) - es una función de coste
La multiplicación de matrices por elementos se hace a través de dos matrices con las mismas dimensiones y origina otra matriz con elementos producto de los elementos de la matriz a y b.
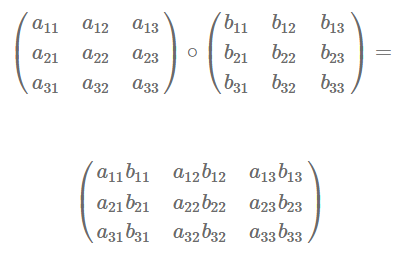
Ejemplo de tomar el producto de dos matrices, A (2×3) y B (3×2).
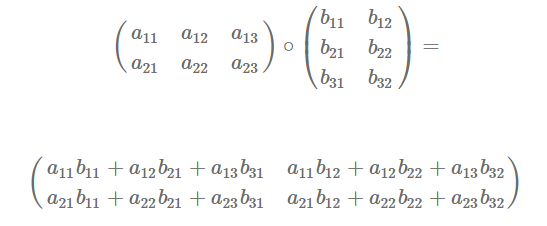
La matriz producto es definida solamente cuando el número de columnas en A sea igual al número de filas en B.
La transposición de una matriz es la formación de una nueva matriz que va a estar formada por el intercambio de filas y columnas.
![]()
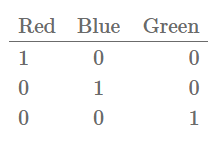
La codificación en caliente es utilizada para codificar características categóricas. Como por ejemplo la del color. Por ejemplo, supongamos que tenemos una característica llamada color, que puede tomar valores como: rojo, azul, verde.
Sigmoideo (sigmoid): es una función conocida también como logística, es usada para la clasificación binaria, su derivado se puede calcular de manera fácil y es continúa. Esta función 'aplasta' los números reales para que oscilen entre [0,1]. Por ejemplo:
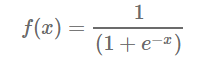 Softmax: es la generalización de la función sigmoide, si queremos manejar muchas clases. Los valores de salida están en el rango (0, 1) y suman hasta 1,0, por lo que se puede interpreta como probabilidades de que la entrada pertenezca a la de una, de un conjunto de clases de salida.
Softmax: es la generalización de la función sigmoide, si queremos manejar muchas clases. Los valores de salida están en el rango (0, 1) y suman hasta 1,0, por lo que se puede interpreta como probabilidades de que la entrada pertenezca a la de una, de un conjunto de clases de salida.
Unidades lineales rectificadas - ReLU: Las salidas ReLU dan 0 si la entrada es menor o igual a 0 y salida raw, porque de lo contrario, se puede pensar que ellas son interruptores. De 'inspiración biológica' dejan entrenar redes más profundas a través de la retropropagación. No sufre el problema del gradiente de fuga, que lo hace muy rápido. Se ha utilizado en redes convolucionales de manera más efectiva que la función logística ampliamente utilizada.
![]()
La función de coste cruzada es usada para clasificar. Es una opción natural por si se encuentra una no-linealidad sigmoide o softmax en capa de salida.
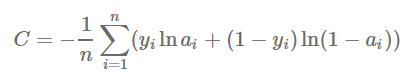 La a - representa la salida de la red neuronal, y valor objetivo 'n' es el número total de ejemplos de entrenamiento.
La a - representa la salida de la red neuronal, y valor objetivo 'n' es el número total de ejemplos de entrenamiento.
La red Feedforward da oportunidad que las señales se desplacen en un solo sentido, de entrada a salida. La red neuronal recurrente es una red especial que tiene conexiones recurrentes. El RNN puede describirse usando fórmula recurrente:
![]()
El estado St en el tiempo 't' es una función del estado anterior St-1 y la entrada Xt en el paso de tiempo (step). La red neuronal recurrente mantiene un estado interno St, utilizando su propia salida como parte de la entrada para el siguiente paso de tiempo (step). Este vector de estado resume la historia de la secuencia que ha visto hasta ahora.
Las redes neuronales recurrentes: son Turing y completas, llegan a simular programas arbitrarios y la red de alimentación, calcula una entrada o salida de tamaño fijo, el RNN maneja datos secuenciales de longitud arbitraria.