
Blog
Los gustos de las personas generalmente siguen patrones y hay similitudes. A la gente le suelen gustar cosas de la misma categoría o cosas que comparten las mismas características. Por ejemplo, si has comprado recientemente un libro sobre “Historia de Europa” y has disfrutado leyéndolo, es muy probable que también disfrutes leyendo un libro sobre “Historia de América” o sobre “Ciudades de Europa con historia”. Los sistemas de recomendación intentan captar estos patrones y comportamientos similares, para ayudar a predecir qué más podría gustarle.
Los sistemas de recomendación suelen estar presentes en muchos sitios web, como sugiriendo libros en Amazon y películas en Netflix. Si una determinada película se ve con suficiente frecuencia, el sistema de recomendación de Netflix se encarga de que esa película reciba un número creciente de recomendaciones. Otro ejemplo puede encontrarse en una aplicación móvil de uso diario, donde un motor de recomendación se utiliza para recomendar cualquier cosa, desde dónde ir de vacaciones o dónde ir a comer.
Una de las principales ventajas del uso de sistemas de recomendación es que los usuarios obtienen una mayor exposición a muchos productos en los que podrían estar interesados. Esto no sólo proporciona una mejor experiencia para el usuario, sino que también beneficia al proveedor de servicios y aumenta los ingresos potenciales del sitio.
Tipos de sistemas de recomendación
En general, existen dos tipos principales de sistemas de recomendación:
- Basados en el contenido
- Filtrado colaborativo
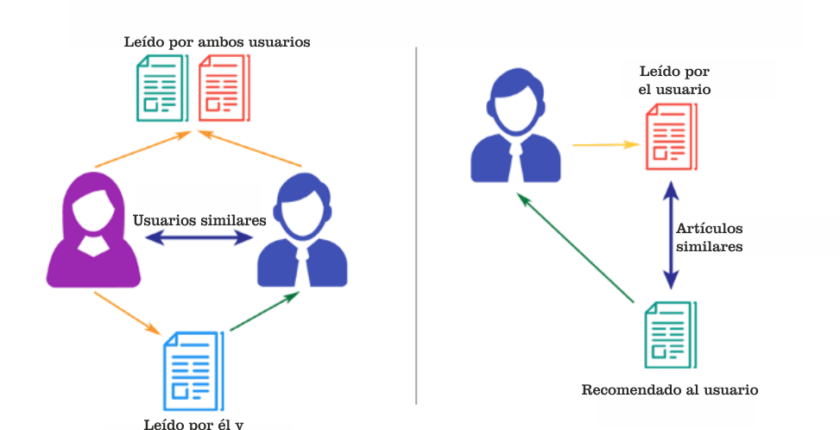
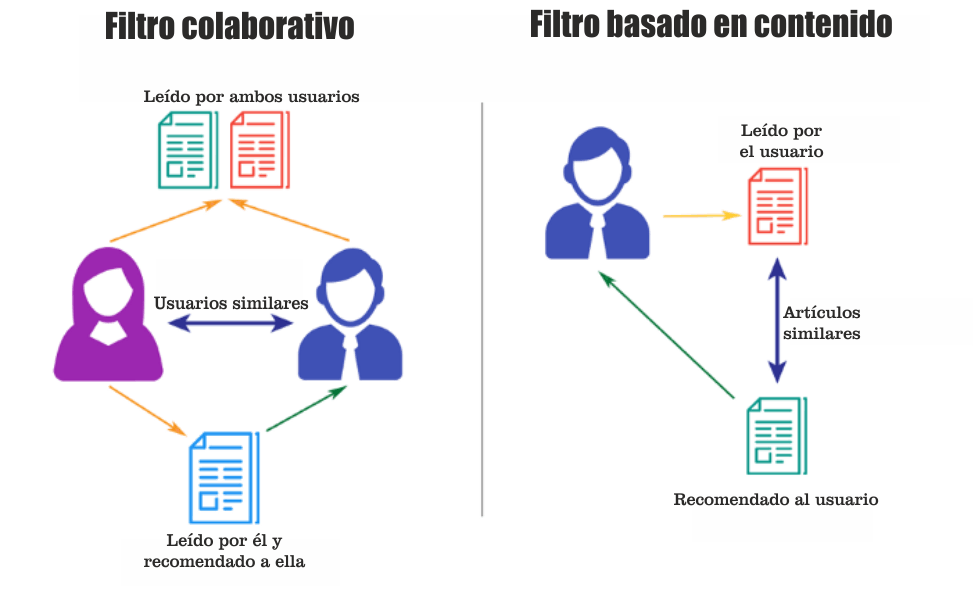
Los sistemas basados en el contenido intentan averiguar cuáles son los aspectos favoritos de un usuario de un artículo, y luego hacen recomendaciones sobre artículos que comparten esos aspectos. El filtrado colaborativo se basa en que unos usuarios de gustos similares probablemente le gusten artículos similares. En resumen, se supone que un usuario puede estar interesado en lo que les interesa a otros usuarios similares. También hay sistemas de recomendación híbridos que combinan varios mecanismos.
Implementación de los sistemas de recomendación
Existen dos tipos:
- Basados en la memoria
- Basados en el modelo
En los enfoques basados en la memoria se utilizan técnicas estadísticas para aproximar usuarios a los artículos. Ejemplos de estas técnicas son la Correlación de Pearson, la Similitud de Coseno, la Distancia Euclidiana. En los enfoques basados en modelos, se desarrolla un modelo de usuarios que pueden crearse utilizando técnicas de machine learning como la regresión, la agrupación, la clasificación, etc.
Filtrado colaborativo
El filtrado colaborativo se basa en el hecho de que existen relaciones entre los productos y los intereses de las personas. El filtrado colaborativo tiene básicamente dos enfoques: el basado en el usuario y el basado en el artículo. El filtrado colaborativo basado en el usuario se basa en la similitud o vecindad del usuario. El filtrado colaborativo basado en el artículo se basa en la similitud entre los artículos.
En el filtrado colaborativo basado en el usuario, tenemos un usuario activo al que se dirige la recomendación. El motor de filtrado colaborativo busca primero a los usuarios que comparten los patrones de valoración del usuario activo. El filtrado colaborativo basa esta similitud en aspectos como el historial, las preferencias y las elecciones que hacen los usuarios cuando compran. A continuación, utiliza las valoraciones de estos usuarios similares para predecir las posibles valoraciones del usuario activo de un producto que no haya visto previamente. Por ejemplo, si dos usuarios son similares o vecinos en cuanto a las películas que les interesan, podemos recomendar al usuario activo una película que su vecino ya haya visto.
¿Cómo funciona el Filtrado colaborativo?
Supongamos que tenemos una simple matriz usuario-artículo, que muestra las valoraciones de cuatro usuarios para cinco películas diferentes. Supongamos también que nuestro usuario activo (active usuario en la siguiente imagen) ha visto y valorado tres de estas cinco películas. Averigüemos cuál de las dos películas que nuestro usuario activo no ha visto debería recomendársele.

El primer paso es descubrir la similitud del usuario activo con los demás usuarios a través de una de las diferentes técnicas estadísticas y vectoriales como las medidas de distancia o similitud, incluyendo la distancia euclidiana, la correlación de Pearson, la similitud del coseno, etc. Para calcular el nivel de similitud entre dos usuarios, utilizamos las tres películas que ambos usuarios han valorado en el pasado.

Independientemente de lo que utilicemos para medir la similitud, por ejemplo, la similitud podría ser de 0,7, 0,9 y 0,4 entre el usuario activo y otros usuarios. Estos números representan los pesos de similitud o la proximidad del usuario activo a otros usuarios en el conjunto de datos. Ahora con estos pesos vamos a calcular la posible opinión del usuario activo sobre nuestras dos películas objetivo que lo definimos como la matriz de calificación ponderada. Esto se consigue multiplicando los pesos de similitud a las valoraciones de los usuarios.
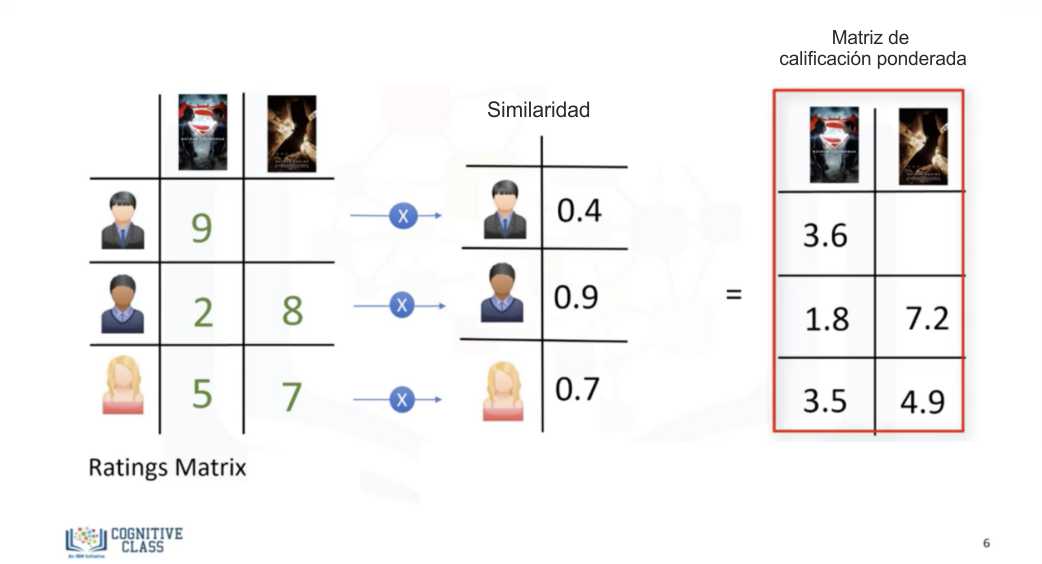
La matriz de valoraciones ponderadas representa las opiniones de los vecinos del usuario sobre nuestras dos películas candidatas a ser recomendadas. Esta matriz incorpora el comportamiento de otros usuarios y da más peso a las valoraciones de aquellos usuarios que son más similares al usuario activo.
Ahora, podemos generar la matriz de recomendación agregando todas las valoraciones ponderadas. Sin embargo, como tres usuarios calificaron la primera película potencial y dos usuarios calificaron la segunda película, tenemos que normalizar los valores de calificación ponderados. Para ello, dividimos la suma de las valoraciones ponderadas por la suma del índice de similitud de los usuarios.
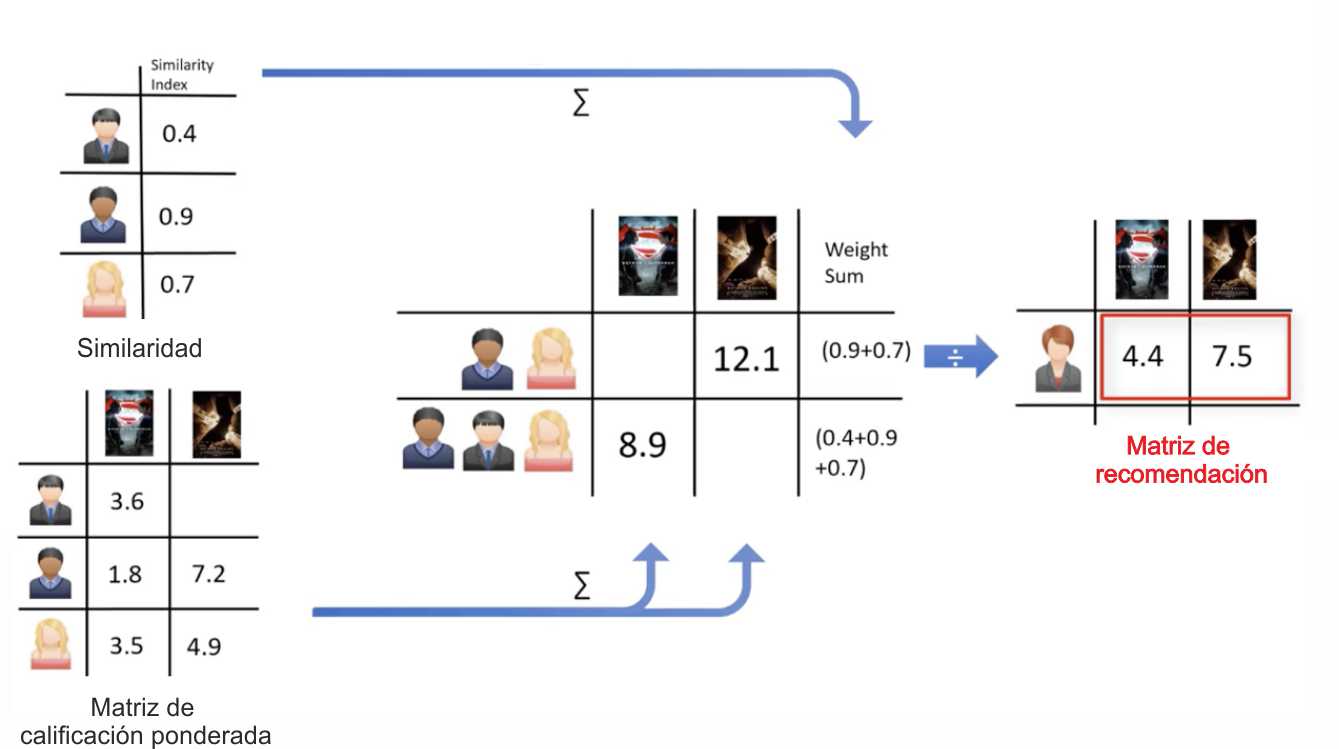
El resultado es la valoración potencial que nuestro usuario activo dará a estas películas en función de su similitud con otros usuarios. Es obvio que podemos utilizarlo para clasificar las películas y ofrecer recomendaciones a nuestro usuario activo.
Ahora, examinemos la diferencia entre el filtrado colaborativo basado en el usuario y el basado en los elementos.
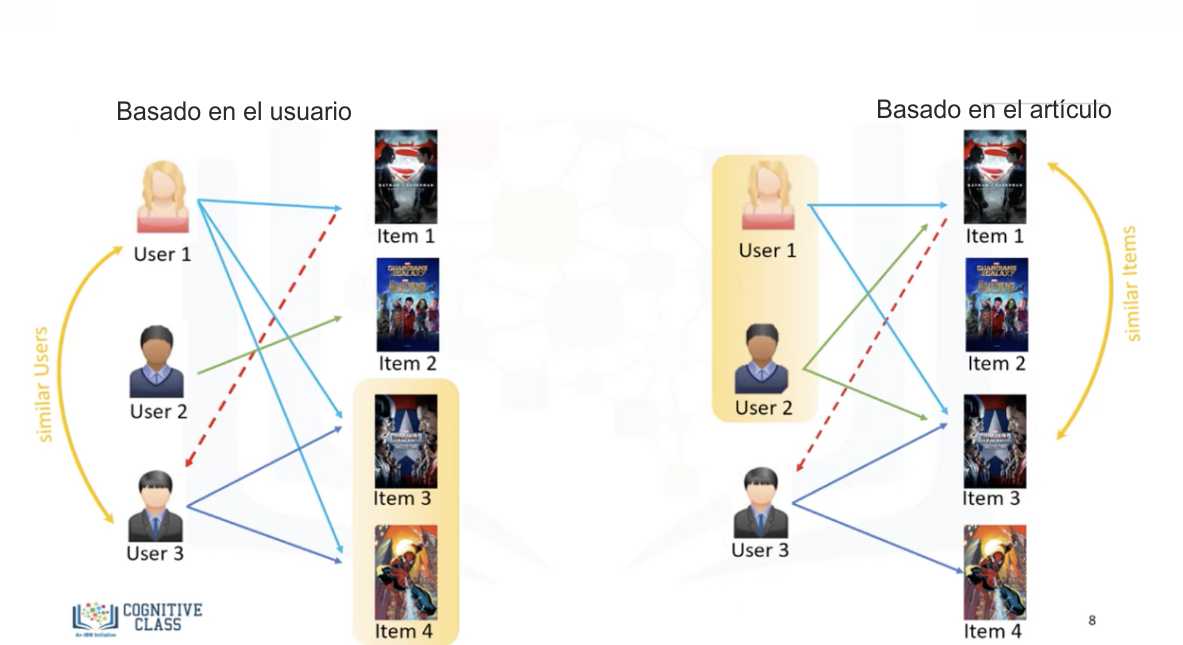
En el enfoque basado en el usuario, la recomendación se basa en los usuarios de la misma vecindad con los que comparte preferencias comunes. Por ejemplo, como al usuario 1 y al usuario 3 les gusta el artículo 3 y el artículo 4, los consideramos similares -o usuarios vecinos- y recomendamos al usuario 3 el artículo 1, que ha sido valorado positivamente por el usuario 1.
En el enfoque basado en artículos, los artículos similares construyen vecindades en base al comportamiento de los usuarios (¡no en base a sus contenidos!). Por ejemplo, el artículo 1 y el artículo 3 se consideran vecinos porque han sido valorados positivamente por el usuario 1 y el usuario 2. Por lo tanto, el artículo 1 puede recomendarse al usuario 3 porque ya ha mostrado interés en el artículo 3. Por lo tanto, las recomendaciones aquí se basan en los artículos de la vecindad que un usuario podría preferir.
Ejemplo de sistema de recomendación en Python
Para construir un sistema de recomedación vamos a necesitar un dataset donde usuarios han valorado previamente, para ellos vamos a usar los siguientes archivos:
Preprocesado de los datos
Primero importamos la librerías y leemos los csv para tener nuestros dataframes:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
movies_df = pd.read_csv('movies.csv')
ratings_df = pd.read_csv('ratings.csv')
Verificando nuestros dataframes podemos ver que en movies.csv tenemos el id de la película con el año, título y los géneros. Mientras que en ratings.csv tenemos el id del usuario, el id de la película y la valoración de la misma.
Ahora hacemos un poco de preprocesado de los datos:
#creamos una columna nueva que se llamará year
movies_df['year'] = movies_df.title.str.extract('(\(\d\d\d\d\))',expand=False)
#Quitando los paréntesis
movies_df['year'] = movies_df.year.str.extract('(\d\d\d\d)',expand=False)
#Eliminar los años de la columna "título" y el espacio
movies_df['title'] = movies_df.title.str.replace(' (\(\d\d\d\d\))', '')
#eliminamos los generos
movies_df = movies_df.drop('genres',1)
Filtrado colaborativo
La técnica que vamos a ver es el Filtrado Colaborativo, que también se conoce como Filtrado Usuario-Usuario. Como indica su nombre alternativo, esta técnica utiliza a otros usuarios para recomendar artículos al usuario de entrada. Trata de encontrar usuarios que tengan preferencias y opiniones similares a las del usuario de entrada y, a continuación, le recomienda los artículos que le han gustado. Existen varios métodos para encontrar usuarios similares y usaremos la función de correlación de Pearson.
Para recapitular el proceso de creación de un sistema de recomendación basado en el usuario:
- Seleccionar un usuario con las películas que ha visto
- Basado en su calificación a las películas, encontrar los X mejores vecinos
- Obtenga el registro de películas vistas por el usuario para cada vecino.
- Calcular una puntuación de similitud
- Recomendar los elementos con la puntuación más alta
Empecemos por crear un usuario de entrada al que recomendar películas:
userInput = [
{'title':'Heat', 'rating':5},
{'title':'Star Wars: Episode II - Attack of the Clones', 'rating':4.5},
{'title':'Secret in Their Eyes, The (El secreto de sus ojos)', 'rating':4.5},
{'title':'Terminator 2: Judgment Day', 'rating':4.5},
{'title':'Four Rooms', 'rating':3.5}
]
inputMovies = pd.DataFrame(userInput)
Ahora, con el movieId en nuestra entrada, podemos obtener el subconjunto de usuarios que han visto y revisado las películas en nuestra entrada. Despues agrupamos las filas por userId. También vamos a ordenar estos grupos para que los usuarios que comparten más películas en común con la entrada tengan mayor prioridad. Esto proporciona una recomendación más rica ya que no vamos a pasar por todos los usuarios.
#Filtrar las películas por título
inputId = movies_df[movies_df['title'].isin(inputMovies['title'].tolist())]
#Luego fusionándolo para que podamos obtener el movieId. Lo está fusionando implícitamente por título.
inputMovies = pd.merge(inputId, inputMovies)
#Eliminar información que no usaremos del dataframe
inputMovies = inputMovies.drop('year', 1)
#Final input dataframe
inputMovies
#Filtrar a los usuarios que han visto películas que la entrada ha visto y almacenarlas
userSubset = ratings_df[ratings_df['movieId'].isin(inputMovies['movieId'].tolist())]
userSubset.head()
# Groupby crea varios sub dataframes de datos donde todos tienen el mismo valor en la columna especificada #como parámetro
userSubsetGroup = userSubset.groupby(['userId'])
# Ordenamos por los usuarios que han puntuado mas a las peliculas en común con la entrada
userSubsetGroup = sorted(userSubsetGroup, key=lambda x: len(x[1]), reverse=True)
userSubsetGroup = userSubsetGroup[0:100]
Similitud de usuarios con el usuario de entrada
Vamos a averiguar qué tan similar es cada usuario a la entrada a través del coeficiente de correlación de Pearson. Se utiliza para medir la fuerza de una asociación lineal entre dos variables. La fórmula para encontrar este coeficiente entre los conjuntos X e Y con valores N se puede ver en la siguiente imagen:

Los valores dados por la fórmula varían de r = -1 a r = 1, donde 1 forma una correlación directa entre las dos entidades (significa una correlación positiva perfecta) y -1 forma una correlación negativa perfecta.
Seleccionaremos un subconjunto de usuarios para iterar. Este límite se impone porque no queremos perder demasiado tiempo recorriendo cada uno de los usuarios
pearsonCorrelationDict = {}
#Para cada grupo de usuarios de nuestro subconjunto
for name, group in userSubsetGroup:
#Comencemos ordenando la entrada y el grupo de usuarios actual para que los valores no se mezclen más adelante.
group = group.sort_values(by='movieId')
inputMovies = inputMovies.sort_values(by='movieId')
#Obtenga las puntuaciones de las reseñas de las películas que ambos tienen en común
temp_df = inputMovies[inputMovies['movieId'].isin(group['movieId'].tolist())]
#Y luego guárdelos en una variable de búfer temporal en un formato de lista para facilitar cálculos futuros
tempRatingList = temp_df['rating'].tolist()
#Pongamos también las reseñas del grupo de usuarios actual en un formato de lista
tempGroupList = group['rating'].tolist()
data_corr = {'tempGroupList': tempGroupList,
'tempRatingList': tempRatingList}
pd_corr = pd.DataFrame(data_corr)
r = pd_corr.corr(method="pearson")["tempRatingList"]["tempGroupList"]
#ahora eliminamos los nan de nuestro coef de pearson
if math.isnan(r) == True:
r = 0
pearsonCorrelationDict[name] = r
#Convertimos el diccionario a un dataframe:
pearsonDF = pd.DataFrame.from_dict(pearsonCorrelationDict, orient='index')
pearsonDF.columns = ['similarityIndex']
pearsonDF['userId'] = pearsonDF.index
pearsonDF.index = range(len(pearsonDF))
pearsonDF.head()
Los usuarios similares principales al usuario de entrada
Ahora veamos los 50 usuarios principales que son más similares a la entrada:
topUsers=pearsonDF.sort_values(by='similarityIndex', ascending=False)[0:50] topUsers.head()
Clasificación de usuarios seleccionados para todas las películas
topUsersRating=topUsers.merge(ratings_df, left_on='userId', right_on='userId', how='inner') topUsersRating.head()
Ahora todo lo que tenemos que hacer es simplemente multiplicar la calificación de la película por su peso (el índice de similitud), luego sumar las nuevas calificaciones y dividirlo por la suma de los pesos. Podemos hacer esto fácilmente simplemente multiplicando dos columnas, luego agrupando el dataframe por movieId y luego dividiendo dos columnas:
Muestra la idea de todos los usuarios similares a las películas candidatas para el usuario de entrada:
topUsersRating['weightedRating'] = topUsersRating['similarityIndex']*topUsersRating['rating'] topUsersRating.head()
Aplica una suma a los usuarios principales después de agruparlos por userId
tempTopUsersRating = topUsersRating.groupby('movieId').sum()[['similarityIndex','weightedRating']]
tempTopUsersRating.columns = ['sum_similarityIndex','sum_weightedRating']
tempTopUsersRating.head()
#Crea un nuevo dataframe recommendation_df = pd.DataFrame() #Ahora tomamos el promedio ponderado recommendation_df['weighted average recommendation score'] = tempTopUsersRating['sum_weightedRating']/tempTopUsersRating['sum_similarityIndex'] recommendation_df['movieId'] = tempTopUsersRating.index recommendation_df.head()
Ahora clasifiquémoslo y veamos las 30 películas principales recomendadas por el algoritmo.
recommendation_df = recommendation_df.sort_values(by='weighted average recommendation score', ascending=False) recommendation_df.head(30) print(movies_df.loc[movies_df['movieId'].isin(recommendation_df.head(30)['movieId'].tolist())])
Beautiful Girls
Some Kind of Wonderful
Horse Whisperer, The
American Flyers
Prizzi’s Honor
Love and Death
Tampopo
Phantasm II
Stranger Than Paradise
Waydowntown
Rain
Cherish
Belle époque
Human Condition III, The (Ningen no joken III)
Branded to Kill (Koroshi no rakuin)
Last Hurrah for Chivalry (Hao xia)
Eddie Murphy Delirious
Bullet in the Head
Summer’s Tale, A (Conte d’été)
Fired Up
Ugly Truth, The
Troll 2
Dinner for Schmucks
Lockout
Eva
Superman/Batman: Public Enemies
Day of the Doctor, The
Boyhood
Band of Brothers
De platte jungle
para recomendar a un candidato a un puesto de trabajo. Sería similar, aunque aquí necesitaríamos conocer los conocimientos, habilidades y actitudes del puesto de trabajo por un lado y por otro los conocimientos. Y luego las habilidades y actitudes. Que haga un test o prueba para que a través de IA. Me las valore objetivamente.
Sería así? O estoy confundido. Desde mi desconocimiento total de IA
Se podría crear un modelo fiable que ayudase a las consultoras en la selección de RRHH?