
Blog

Realizar el proceso de análisis al caso de estudio sobre la obesidad en el Reino Unido
Limpiar, analizar y visualizar nuestro análisis
Ayer leí un letrero en un gimnasio que decía, “los niños están engordando más y más cada década”. Debajo del letrero había un gráfico que básicamente mostraba como en cinco años el niño inglés promedio pronto pesaría tanto como un barril de cerveza. Encontré esta afirmación ligeramente increíble, así que decidí investigar…
Los Datos para este Análisis de Obesidad
Los datos han sido extraídos de Data.gov.uk. Utilizaremos el archivo XLS correspondiente al año 2014. Descárgalo, y ábrelo en la herramienta de hoja de cálculo de tu preferencia. También puedes descargar estos datos desde aquí.
Luego navega hasta la hoja 7.2, dado que contiene los datos que buscamos:
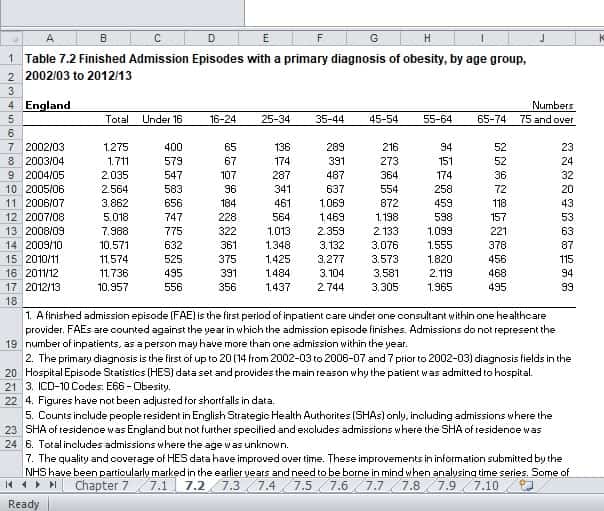
Ahora, antes de que saltemos al análisis de los datos con Pandas, regresemos un paso atrás y nos preguntaremos:
¿Si puede realizar el análisis en Excel, por qué usaría Python?
Python vs Excel
¿Debería usar Python o Excel?
Esta pregunta es frecuentemente hecha por personas que recién comienzan su andadura en el campo de los análisis de datos. Mientras que Python es popular contando con una amplia comunidad de programadores, Excel es mucho más prevaleciente en el mundo entero. La mayor parte de los gerentes de empresas, jefes de ventas, especialistas en mercado… usan Excel – y no hay nada malo en esto. Es una gran herramienta si sabes cómo usarla bien, y ha convertido a muchas personas no técnicas en analistas expertos.
La respuesta con respecto a si deberías usar Python o Excel no es fácil de conseguir.
Excel es grandioso para visualizar los datos, realizar análisis básicos, y dibujar gráficos simples, pero no es apto para limpiar tus datos (a menos que estés dispuesto a sumergirte en el VBA). Si posees un archivo de Excel de 500MB con datos que falten, fechas en distintos formatos, sin encabezados, te tomará muchísimo tiempo limpiarlo manualmente. Se puede decir lo mismo si tus datos se encuentra almacenados en una docena de archivos CSV, lo cual es muy común.
Hacer la limpieza se vuelve trivial con Python y Pandas, una librería de Python para el análisis de datos. Construida en Numpy, Pandas hace que tareas de alto nivel sean sencillas, y puedes plasmar los resultados obtenidos en un archivo de Excel, así que puedes seguir compartiéndolos con personas que no son programadores.
Además, a pesar de que Excel es ampliamente utilizado, Python es una herramienta grandiosa si deseas filtrar tus datos y llevar a cabo un análisis de datos de nivel alto.
El Código
Muy bien, comencemos con el código para Analizar la Obesidad de UK con Python
Comienza por crear un script nuevo llamado obesity.py e importa Pandas y matplotlib para que podamos representar los gráficos luego:
import pandas as pd import matplotlib.pyplot as plt import numpy as np
Asegúrate de instalar las librerias a usar:
- pandas
- matplot
- numpy
Luego, abriremos el archivo de Excel:
data = pd.ExcelFile("Obes-phys-acti-diet-eng-2014-tab.xls")
Ahora vamos a imprimir lo que tenemos:
print(data.sheet_names)
Ejecutamos el programa en el run de spyder o f5 o ejecutando el archivo donde tenemos el código desde el terminal:
$ python obesity.py
Y nos debe salir esta linea:
[u’Chapter 7′, u’7.1′, u’7.2′, u’7.3′, u’7.4′, u’7.5′, u’7.6′, u’7.7′, u’7.8′, u’7.9′, u’7.10′]¿Te resulta familiar? Estas son las hojas que habíamos visto antes. Recuerda, nos enfocaremos en la hoja 7.2. Ahora, si observas la hoja 7.2 en Excel, verás que las 4 filas de la parte superior y las 14 de la parte inferior contienen información inútil. Esta información es útil para los humanos, pero no para nuestro script. Sólo necesitaremos entre las filas 5-18, es decir donde están los números.
Limpieza / Filtrando datos
Cuando leemos la hoja debemos asegurarnos de que cualquier información innecesaria se deje afuera.
data_age = data.parse(u'7.2', skiprows=4, skipfooter=14) print(data_age)
Unnamed: 0 Total Under 16 16-24 25-34 35-44 45-54 55-64 65-74 \0 NaN NaN NaN NaN NaN NaN NaN NaN NaN1 2002/03 1275 400 65 136 289 216 94 522 2003/04 1711 579 67 174 391 273 151 523 2004/05 2035 547 107 287 487 364 174 364 2005/06 2564 583 96 341 637 554 258 72 #…snip…#
Leemos la hoja, saltándonos las primeras 4 filas igual que las 14 últimas (dado que contienen información no útil). Luego imprimimos lo que tenemos (Por simplicidad, sólo muestro las primeras líneas arriba.)
La primera línea representa los encabezados de las columnas. Luego puedes darte cuenta de que Pandas es muy inteligente porque detectó la mayor parte de los encabezados de forma automática. Excepto para el primero, por supuesto – por ejemplo, Unnamed: 0. ¿Por qué sucede eso? Simple. Observa el archivo de Excel, y verás que le falta un encabezado para el año.
Otro problema es que tenemos una línea vacía en el archivo original, y eso se muestra como NaN (Not a number).
Así que, ahora debemos hacer dos cosas:
- Renombrar el primer encabezado como Year, y
- Deshacernos de cualquier fila vacía.
Year = año (siempre evito usar la letra ñ)
data_age.rename(columns={u'Unnamed: 0': u'Year'}, inplace=True)[php]
#Ahora renombraremos el primer encabezado como YEAR#
Aquí le dijimos a Pandas que renombre la columna Unnamed: 0 como Year. Utilizando la función integrada rename().
Ahora vamos a suprimir las filas vacías con NaN:
# eliminaremos filas vacias NaN#
data_age.dropna(inplace=True)
Hay una cosa más que necesitamos hacer que hará nuestras vidas más sencillas. Si observas la tabla data_age, el primer valor es un número. Este es el índice, y Pandas usa la práctica por defecto de Excel de colocar un número como índice. Sin embargo, queremos cambiar el índice a Year. Esto hará el ploteado mucho más sencillo, dado que el índice usualmente se plotea como el eje de las x.
Fijamos el índice como Year.
#Para que el plotedo sea más sencillo cambiamos el indice a YEAR#
data_age.set_index('Year', inplace=True)
print(data_age)
Y ejecutamos:
Total Under 16 16-24 25-34 35-44 45-54 55-64 65-74 \Year2002/03 1275 400 65 136 289 216 94 522003/04 1711 579 67 174 391 273 151 522004/05 2035 547 107 287 487 364 174 362005/06 2564 583 96 341 637 554 258 72#…snip…#
Mucho mejor. Puedes ver el índice ahora como Year, y todos los NaNs desaparecieron.
Gráficos del Análisis de datos
Ahora podemos plotear lo que tenemos.
#Realizamos los gráficos#
data_age.plot() plt.show()

Oops. Hay un problema: Nuestros datos originales contienen un campo total que está eclipsando a todo lo demás. Necesitamos deshacernos de él.
#Representamos de nuevo, pero eliminando el número Total#
data_age_minus_total = data_age.drop('Total', axis=1)
axis =1 es un poco confuso, pero todo lo que significa realmente es – eliminar las columnas.
Ploteemos lo que tenemos ahora.
data_age_minus_total.plot() plt.show() plt.close()
Mucho mejor. Podemos ver grupos individuales de edades ahora.
¿Identificas cuál grupo de edad posee la mayor obesidad?

Regresando a la pregunta original: ¿Los niños están engordando?
Pues parece que no mucho…
Hagamos una gráfica sobre una pequeña sección de los datos:
- los niños por debajo de 16 años y los adultos en un intervalo de edad entre los 35 y los 44.
# Representamos children vs adults# data_age['Under 16'].plot(label="Under 16") data_age['35-44'].plot(label="35-44") plt.legend(loc="upper right") plt.show() plt.close()

Así que, ¿quiénes están engordando más?
Ejecutando. ¿Qué es lo que vemos?
Mientras que la obesidad infantil ha disminuido un poco, la de sus padres ha incrementado enormemente. Así que parece que los padres necesitan preocuparse más por ellos mismos que por sus hijos.
Pero, ¿qué hay sobre el futuro?
El gráfico aún no nos dice qué sucederá con la obesidad infantil en el futuro. Hay formas de extrapolar estos gráficos hacia el futuro, pero debo darles una advertencia antes de seguir: Los datos de obesidad no poseen una base matemática subyacente. Esto quiere decir, no podemos conseguir una fórmula para predecir cómo cambiarán estos valores en el futuro. Todo es esencialmente fruto del azar. Dada esta advertencia, veamos cómo podemos extrapolar nuestro gráfico.
Primero, Scipy provee una función para la extrapolación, pero sólo funciona para los datos que aumentan de forma monótona (mientras que nuestros datos suben y bajan).
- El Ajuste de Curvas busca ajustar una curva a través de los puntos de un gráfico, generando una función matemática para los datos. La función puede o no ser precisa, dependiendo de los datos.
- La Interpolación Polinomial: una vez que tienes una ecuación, puedes usar la interpolación polinomial para interpolar cualquier valor sobre el gráfico.
Utilizaremos estas dos funciones juntas para tratar de predecir el futuro de los niños ingleses:
kids_values = data_age['Under 16'].values x_axis = range(len(kids_values))
Aquí extraeremos estos valores sobre los niños menores de 16 años. Para el eje de las x, el gráfico original representaba fechas. Para simplificar el gráfico, usaremos los números entre el 0 y el 10.
Salida:
| array([ 400., 579., 547., 583., 656., 747., 775., 632., 525., 495., 556.]) [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10] |
poly_degree = 3 curve_fit = np.polyfit(x_axis, kids_values, poly_degree)
Fijamos el polinomio de grado 3. Luego usamos la función de Numpy polyfit() para obtener un gráfico de los datos que tenemos. La función poly1d() es llamada entonces a la ecuación que generamos para crear una función que será usada para generar nuestros valores. Esto retorna una función llamada poly_interp que usaremos abajo:
poly_interp = np.poly1d(curve_fit) poly_fit_values = [] for i in range(len(x_axis)): poly_fit_values.append(poly_interp(i))
Entramos en un bucle entre 0 y 10, y llamamos a la función poly_interp() para cada valor. Recuerda, esta es la función que generamos cuando corremos el algoritmo del ajuste de la curva.
Antes de continuar, observamos lo que ocurre al utilizar polinomios de distintos grados.
Vamos a plotear ambos, los datos originales, y nuestros datos, para observar cómo se ajusta nuestra ecuación a los datos ideales:
#Representamos los datos# plt.plot(x_axis, poly_fit_values, "-r", label = "Fitted") plt.plot(x_axis, kids_values, "-b", label = "Orig") plt.legend(loc="upper right")
Los datos originales serán ploteados en Azul y la etiquetaremos como Orig = Originales, mientras que los datos generados serán los rojos y los etiquetaremos como Fitted = ajustados
Con un polinomio grado 3 los resultados son:

Observamos que no es un buen ajuste por lo que pasamos entonces con grado 5:

Mucho mejor. ¿Y si intentamos con 7?
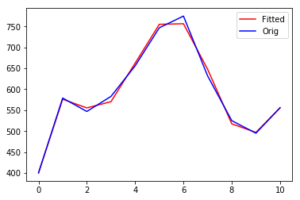
Ahora obtuvimos un ajuste de los datos casi perfectos. Así que:
¿por qué no usamos siempre valores más altos?
Porque los valores más altos han sido acoplados de forma tan sólida a este gráfico, que hacen la predicción una herramienta inútil. Si tratamos de extrapolar el gráfico de arriba, obtendremos valores basura. Intentando diferentes valores, conseguimos que los grados del polinomio 3 y 4 fueron los únicos que arrojaban resultados precisos, así que eso es lo que usaremos.
Vamos a ejecutar nuevamente la función poly_interp(), esta vez para valores entre 0-15, para predecir cinco años en el futuro.
x_axis2 = range(15) poly_fit_values = [] for i in range(len(x_axis2)): poly_fit_values.append(poly_interp(i))
Con 3:

Aquí, la obesidad está disminuyendo…
¿Qué tal con el polinomio grado 4?

Pero aquí, está subiendo…
¡los niños terminarán pesando como barriles de birra!
¿Cuál de los dos gráficos debemos ejecutar? Depende de si trabajas para el gobierno o la oposición.
Esto es realmente una característica, no un error. Seguramente has escuchado estos debates donde dos lados exponen conclusiones completamente opuestas a partir de los mismos datos. Ahora ves cómo es posible obtener dos conclusiones radicalmente distintas a partir de un mismo set de datos sólo retorciendo un poquito los parámetros.
Y esa es la razón por la cual debemos ser cuidadosos cuando aceptemos figuras o gráficos de parte de empresas con intereses concretos, especialmente si ellos no están dispuestos a compartir los datos en bruto. Algunas veces, las predicciones es mejor dejárselas a los videntes.
¡Gracias!
Código en Python del Análisis de Datos de este artículo
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
data = pd.ExcelFile("Obes-phys-acti-diet-eng-2014-tab.xls")
print(data.sheet_names)
data_age = data.parse(u'7.2', skiprows=4, skipfooter=14)
print(data_age)
data_age.rename(columns={u'Unnamed: 0': u'Year'}, inplace=True)
data_age.dropna(inplace=True)
data_age.set_index('Year', inplace=True)
print(data_age)
data_age.plot()
data_age_minus_total = data_age.drop('Total', axis=1)
data_age_minus_total.plot()
plt.show()
data_age['Under 16'].plot(label="Under 16")
data_age['35-44'].plot(label="35-44")
plt.legend(loc="upper right")
plt.show()
plt.close()
kids_values = data_age['Under 16'].values
x_axis = range(len(kids_values))
x_axis2 = range(15)
poly_degree = 5
curve_fit = np.polyfit(x_axis, kids_values, poly_degree)
poly_interp = np.poly1d(curve_fit)
poly_fit_values = []
for i in range(len(x_axis)):
poly_fit_values.append(poly_interp(i))
#Representamos los datos#
plt.plot(x_axis, poly_fit_values, "-r", label = "Fitted")
plt.plot(x_axis, kids_values, "-b", label = "Orig")
plt.legend(loc="upper right")
➡ Gracias por continuar con nosotros. Como pudiste ver, podemos hacer uso de la librería Scipy para ayudarnos en nuestro proceso de análisis. Aprende mas de análisis de datos con nuestro curso Python de análisis de datos.
Muy interesante el articulo me ha resultado muy ùtil para analizar mis datos. Un 10.
[…] Curso de Análisis de Datos, 2º clase […]