
Blog

Originalmente, las herramientas de la librería Pandas, fueron desarrolladas para series temporales financieras. Las robustas y flexibles estructuras de datos en Pandas pueden ser aplicadas a series temporales en cualquier dominio, incluyendo negocios, ciencia, ingeniería, salud pública y muchos otros. Con esta herramienta se pueden organizar, transformar, analizar y visualizar datos en cualquier nivel de granularidad (examinar los detalles durante períodos específicos de interés y extrapolarlos para explorar variaciones en diferentes escalas de tiempo, como agregaciones mensuales o anuales, patrones recurrentes, y tendencias a largo plazo).
➡ Te invitamos a nuestro Curso Python de Análisis de Datos:
En la definición más amplia, una serie temporal es cualquier conjunto de datos donde los valores se miden en diferentes puntos en el tiempo. Muchas series temporales son medidas uniformemente con una frecuencia específica, por ejemplo, las mediciones climáticas por hora, los recuentos diarios de visitas a sitios web o las ventas totales mensuales. Dichas series también pueden estar espaciadas irregularmente, por ejemplo, los datos con marca de tiempo (timestamp) en el registro de eventos (logs) de un sistema informático o un historial de llamadas de emergencia al 911. Las herramientas de series temporales de Pandas se aplican igualmente bien a cualquier tipo de serie temporal.
Este tutorial se enfocará principalmente en data wrangling y en los aspectos de visualización del análisis de las series temporales. Trabajando con una serie temporal de datos de energía eléctrica, se observará la forma en que técnicas como la indexación basada en el tiempo, el remuestreo y las ventanas deslizantes pueden ser de gran ayuda en la exploración de variaciones en la demanda de electricidad y el suministro de energía renovable a lo largo del tiempo. Los siguientes temas serán cubiertos:
- Conjunto de datos: Open Power Systems Data.
- Estructuras de datos de series temporales.
- Indexación basada en el tiempo.
- Visualización de datos de series temporales.
- Estacionalidad.
- Frecuencias.
- Remuestreo.
- Ventanas deslizantes.
- Tendencias.
Se utilizará Python 3.6, Pandas, matplotlib y seaborn. Para aprovechar al máximo este tutorial, se recomienda estar familiarizado con los conceptos básicos de pandas y matplotlib.
Conjunto de Datos: Open Power Systems Data
En este tutorial, se trabajará con series temporales diarias de Open Power System Data (OPSD) para Alemania, que ha estado expandiendo rápidamente su producción de energía renovable en los últimos años. El conjunto de datos incluye los consumos de electricidad totales, la producción de energía eólica y la producción de energía solar en todo el país para 2006-2017. Los datos se encuentran aquí.
El consumo y producción de la electricidad están expresados en GigaWatts-Hora(GWh). Las columnas del archivo de datos contienen la siguiente información:
- Date: La fecha (formato aaaa-mm-dd)
- Consumption: Consumo de electricidad en GWh.
- Wind: Producción de energía eólica en GWh.
- Solar: Producción de energía solar en GWh.
- Wind+Solar: Suma de la producción de energía eólica y solar en GWh.
Se explorará cómo el consumo y la producción de electricidad en Alemania ha variado a lo largo del tiempo, utilizando las herramientas de las series temporales de Pandas para responder las siguientes preguntas:
- ¿Cuándo es el consumo de electricidad tipicamente mas alto y mas bajo?
- ¿Cómo varía la producción de energía eólica y solar con las estaciones del año?
- ¿Cuáles son las tendencias a largo plazo en el consumo de electricidad, energía solar y energía eólica?
- ¿Cómo se compara la producción de energía eólica y solar con el consumo de electricidad, y cómo ha cambiado esta relación con el tiempo?
Estructuras de Datos de Series Temporales
Antes de comenzar el análisis de los datos de OPSD, es necesario conocer las principales estructuras de datos de Pandas para trabajar con fechas y horas. En Pandas, un solo punto en el tiempo se representa como una marca de tiempo (timestamp). La función to_datetime() crea marcas de tiempo a partir de cadenas de caracteres en una amplia variedad de formatos de fecha/hora. A continuación se importará Pandas y se convertirá algunas fechas y horas en marcas de tiempo (timestamps).
>>> import pandas as pnd
>>> pnd.to_datetime('2019-07-18 1:25pm')
Timestamp('2019-07-18 13:25:00')
>>> pnd.to_datetime('9/8/1993')
Timestamp('1993-09-08 00:00:00')
Como puede ser observado, la función to_datetime() infiere automáticamente un formato de fecha/hora basado en la entrada. En el ejemplo anterior, se supone que la fecha ambigua ‘9/8/1993’ es mes/día/año y se interpreta como el 8 de septiembre de 1993. Alternativamente, se puede utilizar el parámetro dayfirst (primero el día) para decirle a Pandas que interprete la fecha como 9 de agosto de 1993.
>>> pnd.to_datetime('9/8/1993', dayfirst=True) Timestamp('1993-08-09 00:00:00')
Si se suministra un arreglo de cadenas de caracteres como entrada para la función to_datetime(), esta devuelve una secuencia de valores de fecha/hora en un objeto DatetimeIndex, que es la estructura de datos central que alimenta gran parte de la funcionalidad de las series temporales de Pandas.
>>> pnd.to_datetime(['2019-07-18','9/8/1993','12/15/2003']) DatetimeIndex(['2019-07-18', '1993-09-08', '2003-12-15'], dtype='datetime64[ns]', freq=None)
En el DatetimeIndex anterior, el tipo de datos datetime64[ns] indica que los datos subyacentes se almacenan como enteros de 64 bits, en unidades de nanosegundos (ns). Esta estructura de datos permite que pandas almacene de forma compacta grandes secuencias de valores de fecha/hora y realice operaciones vectorizadas de manera eficiente utilizando arreglos NumPy datetime64.
Si se está trabajando con una secuencia de cadenas de caracteres en el mismo formato de fecha/hora, se puede especificar explicitamente con el parámetro format (formato). Para conjuntos de datos muy grandes, esto puede acelerar en gran medida el rendimiento de la función to_datetime() en comparación con el comportamiento predeterminado, donde el formato se deduce por separado para cada cadena de caracteres individual. Se puede usar cualquiera de los códigos de formato de las funciones strftime() y strptime() en el módulo datetime incorporado de Python. El siguiente ejemplo utiliza los códigos de formato %m (mes numérico), %d (día del mes) y %y (año de 2 dígitos) para especificar el formato.
>>> pnd.to_datetime(['18/07/19','9/8/93','15/12/03'], format='%d/%m/%y') DatetimeIndex(['2019-07-18', '1993-08-09', '2003-12-15'], dtype='datetime64[ns]', freq=None)
Además de los objetos Timestamp y DatetimeIndex que representan puntos individuales en el tiempo, pandas también incluye estructuras de datos que representan duraciones y períodos. A continuación, se utilizará DatetimeIndexes, la estructura de datos más común para series temporales de pandas.
Creación de un DataFrame de Series Temporales
Para trabajar con datos de series temporales en pandas, se utiliza un DatatimeIdex de fecha/hora como el índice para nuestro marco de datos (DataFrame). Veamos cómo hacer esto con nuestro conjunto de datos OPSD. Primero, usamos la función read_csv() para leer los datos en un DataFrame, y luego mostrar su forma.
>>> opsd_dia = pnd.read_csv('opsd_germany_daily.csv')
>>> opsd_dia.shape
(4383, 5)
El DataFrame tiene 4383 filas, que abarcan desde el 1 de enero de 2006 hasta el 31 de diciembre de 2017. Para ver el los datos, se utilizan los métodos head() y tail() que muestran las primeras y las últimas filas del documento.
>>> opsd_dia.head(4)
Date Consumption Wind Solar Wind+Solar
0 2006-01-01 1069.184 NaN NaN NaN
1 2006-01-02 1380.521 NaN NaN NaN
2 2006-01-03 1442.533 NaN NaN NaN
3 2006-01-04 1457.217 NaN NaN NaN
>>> opsd_dia.tail(4)
Date Consumption Wind Solar Wind+Solar
4379 2017-12-28 1299.86398 506.424 14.162 520.586
4380 2017-12-29 1295.08753 584.277 29.854 614.131
4381 2017-12-30 1215.44897 721.247 7.467 728.714
4382 2017-12-31 1107.11488 721.176 19.980 741.156
De esta forma se abren archivos y se puede hacer consultas.
Para definir el índice que se desea, se utilizan los parámetros index_col y parse_dates de la función read_csv(). Esto suele ser un atajo útil.
>>> opsd_dia = pnd.read_csv('opsd_germany_daily.csv', index_col=0, parse_dates=True)
>>> opsd_dia.index
DatetimeIndex(['2006-01-01', '2006-01-02', '2006-01-03', '2006-01-04',
'2006-01-05', '2006-01-06', '2006-01-07', '2006-01-08',
'2006-01-09', '2006-01-10',
...
'2017-12-22', '2017-12-23', '2017-12-24', '2017-12-25',
'2017-12-26', '2017-12-27', '2017-12-28', '2017-12-29',
'2017-12-30', '2017-12-31'],
dtype='datetime64[ns]', name='Date', length=4383, freq=None)
Ya que el índice de el DataFrame es un índice de fecha y hora, se puede utilizar la indexación basada en el tiempo de Pandas para organizar y analizar datos.
Otro aspecto útil del indexado de fecha y hora es que los componentes de fecha/hora individuales están disponibles como atributos, como año (year), mes (month), día (day), entre otros. Se agregarán algunas columnas mas a opsd_dia, que contienen el año, mes y nombre del día de la semana
>>> opsd_dia['Año'] = opsd_dia.index.year
>>> opsd_dia['Mes'] = opsd_dia.index.month
>>> opsd_dia['Dia'] = opsd_dia.index.weekday_name
>>> opsd_dia.sample(8, random_state=0)
Consumption Wind Solar Wind+Solar Año Mes Dia
Date
2008-08-23 1152.011 NaN NaN NaN 2008 8 Saturday
2013-08-08 1291.984 79.666 93.371 173.037 2013 8 Thursday
2009-08-27 1281.057 NaN NaN NaN 2009 8 Thursday
2015-10-02 1391.050 81.229 160.641 241.870 2015 10 Friday
2009-06-02 1201.522 NaN NaN NaN 2009 6 Tuesday
2015-02-03 1639.260 97.155 27.530 124.685 2015 2 Tuesday
2012-05-28 988.853 36.311 151.315 187.626 2012 5 Monday
2011-07-10 1023.542 22.717 NaN NaN 2011 7 Sunday
Indexación basada en el Tiempo
Una de las características más poderosas y convenientes de las series temporales de Pandas es la indexación basada en el tiempo: el uso de fechas y horas para organizar y acceder de forma intuitiva a los datos. Con la indexación basada en el tiempo, se pueden utilizar cadenas de caracteres con formato de fecha/hora para seleccionar datos en el DataFrame con la función loc. Esto funciona de manera similar a la indexación basada en etiquetas estándar, pero con algunas características adicionales.
Por ejemplo, se pueden seleccionar datos de un solo día utilizando una cadena de caracteres como ‘2015-07-18’.
>>> opsd_dia.loc['2015-07-18'] Consumption 1186.87 Wind 150.581 Solar 148.598 Wind+Solar 299.179 Año 2015 Mes 7 Dia Saturday Name: 2015-07-18 00:00:00, dtype: object
También es posible seleccionar un intervalo, como ‘2013-08-15’:’2013-08-20‘. El intervalo seleccionado es un intervalo cerrado.
>>> opsd_dia.loc['2013-08-15':'2013-08-20']
Consumption Wind Solar Wind+Solar Año Mes Dia
Date
2013-08-15 1230.894 41.649 161.266 202.915 2013 8 Thursday
2013-08-16 1235.737 67.690 177.432 245.122 2013 8 Friday
2013-08-17 1064.704 50.787 150.753 201.540 2013 8 Saturday
2013-08-18 1003.820 139.001 104.760 243.761 2013 8 Sunday
2013-08-19 1279.894 65.016 71.198 136.214 2013 8 Monday
2013-08-20 1262.606 43.807 112.443 156.250 2013 8 Tuesday
Otra característica muy útil de las series temporales de pandas es la indexación de cadenas de caracteres parciales, donde se pueden seleccionar todas las fechas/horas que coincidan parcialmente con una cadena de caracteres dada. Por ejemplo, se puede seleccionar todo el año 2008 con opsd_daily.loc [‘2008’], o todo el mes de marzo de 2009 con opsd_daily.loc [‘2009-03’].
>>> opsd_dia.loc['2009-03']
Consumption Wind Solar Wind+Solar Año Mes Dia
Date
2009-03-01 1098.937 NaN NaN NaN 2009 3 Sunday
2009-03-02 1413.017 NaN NaN NaN 2009 3 Monday
2009-03-03 1427.385 NaN NaN NaN 2009 3 Tuesday
2009-03-04 1423.119 NaN NaN NaN 2009 3 Wednesday
2009-03-05 1432.391 NaN NaN NaN 2009 3 Thursday
2009-03-06 1401.981 NaN NaN NaN 2009 3 Friday
2009-03-07 1190.840 NaN NaN NaN 2009 3 Saturday
2009-03-08 1114.724 NaN NaN NaN 2009 3 Sunday
2009-03-09 1410.659 NaN NaN NaN 2009 3 Monday
2009-03-10 1442.865 NaN NaN NaN 2009 3 Tuesday
2009-03-11 1411.512 NaN NaN NaN 2009 3 Wednesday
2009-03-12 1421.815 NaN NaN NaN 2009 3 Thursday
2009-03-13 1337.766 NaN NaN NaN 2009 3 Friday
2009-03-14 1118.664 NaN NaN NaN 2009 3 Saturday
2009-03-15 1067.434 NaN NaN NaN 2009 3 Sunday
2009-03-16 1330.620 NaN NaN NaN 2009 3 Monday
2009-03-17 1403.564 NaN NaN NaN 2009 3 Tuesday
2009-03-18 1367.561 NaN NaN NaN 2009 3 Wednesday
2009-03-19 1355.794 NaN NaN NaN 2009 3 Thursday
2009-03-20 1302.110 NaN NaN NaN 2009 3 Friday
2009-03-21 1125.085 NaN NaN NaN 2009 3 Saturday
2009-03-22 1130.425 NaN NaN NaN 2009 3 Sunday
2009-03-23 1437.337 NaN NaN NaN 2009 3 Monday
2009-03-24 1420.783 NaN NaN NaN 2009 3 Tuesday
2009-03-25 1409.995 NaN NaN NaN 2009 3 Wednesday
2009-03-26 1387.610 NaN NaN NaN 2009 3 Thursday
2009-03-27 1326.001 NaN NaN NaN 2009 3 Friday
2009-03-28 1150.563 NaN NaN NaN 2009 3 Saturday
2009-03-29 1049.947 NaN NaN NaN 2009 3 Sunday
2009-03-30 1332.565 NaN NaN NaN 2009 3 Monday
2009-03-31 1342.825 NaN NaN NaN 2009 3 Tuesday
Visualización de Datos de Series Temporales
Con pandas y matplotlib, se pueden visualizar fácilmente nuestros datos de las series temporales. En esta sección, se cubrirán algunos ejemplos y algunas personalizaciones útiles para gráficos de series temporales. Se recomienda el uso de Jupyter Notebooks para visualizar los gráficos. Primeramente, es necesario importar matplotlib.
import matplotlib.pyplot as mplt # Esta función es utilizada para mostrar los gráficos
Se utilizará seaborn para el estilo de los gráficos y se ajustará el tamaño de figura predeterminado a una forma más adecuada para las gráficas de series temporales.
import seaborn as sbn
sbn.set(rc={'figure.figsize':(10, 5)})
Se creará un gráfico de líneas de la series temporales completas del consumo diario de electricidad de Alemania, utilizando el método plot().
opsd_dia['Consumption'].plot(linewidth=0.1)
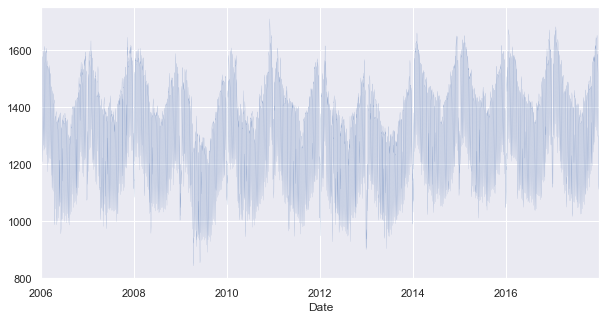
Se puede observar que el método plot() elige buenas escalas y etiquetas para el eje x, lo cual es útil. Sin embargo, con tantos datos, el trazado de línea está abarrotado y es difícil de leer. Se pueden trazar los datos como puntos en su lugar, y también mirar las series temporales de la producción de energía solar (Solar) y eólica (Wind).
col_graf = ['Consumption', 'Solar', 'Wind']
ejes = opsd_dia[col_graf].plot(marker='.', alpha=0.1, linestyle='None',figsize=(10,10),subplots=True)
for eje in ejes:
eje.set_ylabel('Consumo Diario (GWh)')
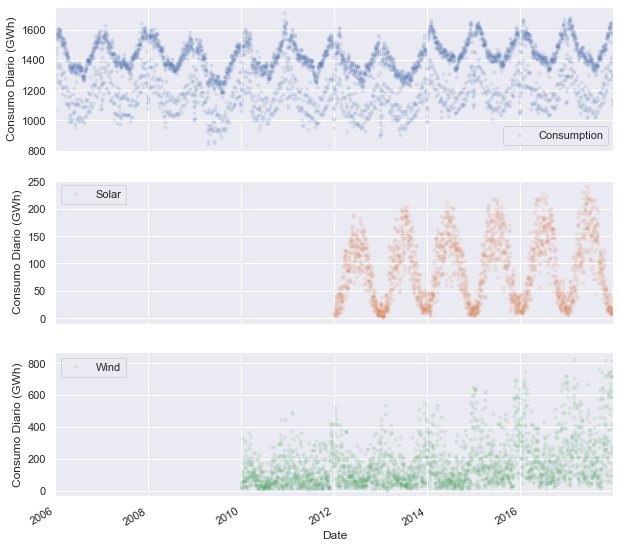
Las tres series temporales muestran claramente la periodicidad, a menudo llamada estacionalidad en el análisis de las series temporales, en la que un patrón se repite una y otra vez en intervalos de tiempo regulares. Las series temporales de consumo (Consumption), producción de energía solar (Solar) y producción de energía eólica (Wind) oscilan entre valores altos y bajos en una escala de tiempo anual, que se corresponde con los cambios estacionales del clima a lo largo del año. Sin embargo, la estacionalidad en general no tiene que corresponder con las estaciones meteorológicas. Por ejemplo, los datos de ventas minoristas a menudo muestran una estacionalidad anual con un aumento de las ventas en noviembre y diciembre, lo que lleva a las vacaciones.
La estacionalidad también puede ocurrir en otras escalas de tiempo. El gráfico anterior sugiere que puede haber alguna estacionalidad semanal en el consumo de electricidad de Alemania, correspondiente a los días de semana y fines de semana. Se trazará la serie temporal en un solo año para investigar más a fondo.
eje = opsd_dia.loc['2016','Consumption'].plot()
eje.set_ylabel('Consumo Diario (GWh)')
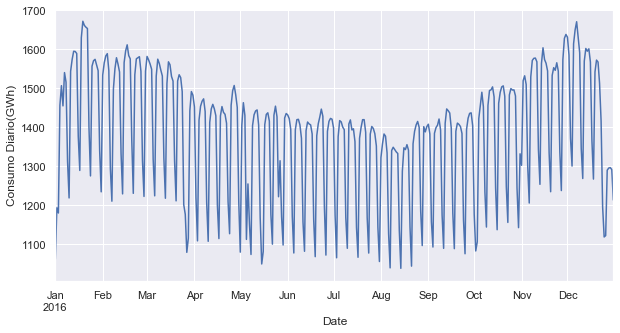
Ahora se pueden notar claramente las oscilaciones semanales. Otra característica interesante que se hace evidente a este nivel de granularidad es la drástica disminución en el consumo de electricidad a principios de enero y finales de diciembre, durante las vacaciones.
Para observar con mayor detalle, se presentará el gráfico de Enero y Febrero.
eje = opsd_dia.loc['2016-01':'2016-02', 'Consumption'].plot(marker='o',linestyle='-')
eje.set_ylabel('Consumo Diario (GWh)')
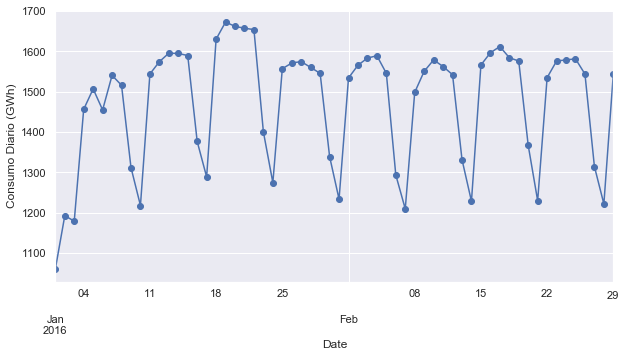
Como se esperaba, el consumo es más alto en los días de semana y más bajo los fines de semana.
El código final de los gráficos de esta parte es:
1er y 2do Gráfico de Visualización de Datos de Series Temporales
import pandas as pnd
import matplotlib.pyplot as mplt
import seaborn as sbn
opsd_dia = pnd.read_csv('opsd_germany_daily.csv', index_col=0, parse_dates=True)
sbn.set(rc={'figure.figsize':(10, 5)})
# 1er Gráfico
opsd_dia['Consumption'].plot(linewidth=0.1)
# 2do Gráfico
col_graf = ['Consumption', 'Solar', 'Wind']
ejes = opsd_dia[col_graf].plot(marker='.', alpha=0.1, linestyle='None',figsize=(10,10),subplots=True)
for eje in ejes:
eje.set_ylabel('Consumo Diario (GWh)')
3er Gráfico de Visualización de Datos de Series Temporales
import pandas as pnd
import matplotlib.pyplot as mplt
import seaborn as sbn
opsd_dia = pnd.read_csv('opsd_germany_daily.csv', index_col=0, parse_dates=True)
sbn.set(rc={'figure.figsize':(10, 5)})
# 3er Gráfico
eje = opsd_dia.loc['2016','Consumption'].plot()
eje.set_ylabel('Consumo Diario(GWh)')
4to Gráfico de Visualización de Datos de Series Temporales
import pandas as pnd
import matplotlib.pyplot as mplt
import seaborn as sbn
opsd_dia = pnd.read_csv('opsd_germany_daily.csv', index_col=0, parse_dates=True)
sbn.set(rc={'figure.figsize':(10, 5)})
# 4to Gráfico
eje = opsd_dia.loc['2016-01':'2016-02', 'Consumption'].plot(marker='o',linestyle='-')
eje.set_ylabel('Consumo Diario (GWh)')
Estacionalidad
A continuación, se profundizará en la estacionalidad de los datos con diagramas de caja, utilizando la función boxplot() de seaborn para agrupar los datos por diferentes períodos de tiempo y mostrar las distribuciones de cada grupo. Primero se agrupan los datos por mes, para visualizar la estacionalidad anual.
fig, ejes = mplt.subplots(3, 1, figsize=(11, 10), sharex=True)
for nombre, eje in zip(['Consumption','Solar','Wind'], ejes):
sbn.boxplot(data=opsd_dia,x='Mes',y=nombre,ax=eje)
eje.set_title(nombre)
if eje != ejes[-1]:
eje.set_xlabel('')
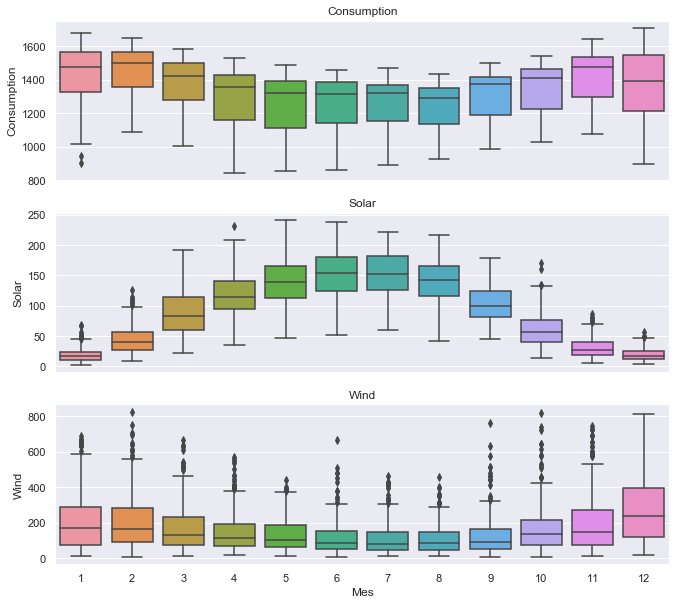
Estos diagramas confirman la estacionalidad anual que se observó en las gráficas anteriores y brindan algunas ideas adicionales:
- Aunque el consumo de electricidad es generalmente más alto en invierno y más bajo en verano, la mediana y los dos cuartiles más bajos son más bajos en diciembre y enero en comparación con noviembre y febrero, probablemente debido a que las empresas están cerradas durante las vacaciones. Esto se observó en la serie temporal del año 2016, y el diagrama de caja confirma que este es un patrón constante a lo largo de los años.
- Si bien la producción de energía solar y eólica muestran una estacionalidad anual, las distribuciones de energía eólica tienen muchos más valores atípicos, lo que refleja los efectos ocasionales de las velocidades extremas del viento asociadas con las tormentas y otras condiciones meteorológicas transitorias.
A continuación, se agruparán las series temporales de consumo de electricidad por día de la semana, para explorar la estacionalidad semanal.
sbn.boxplot(data=opsd_dia, x='Dia', y='Consumption')
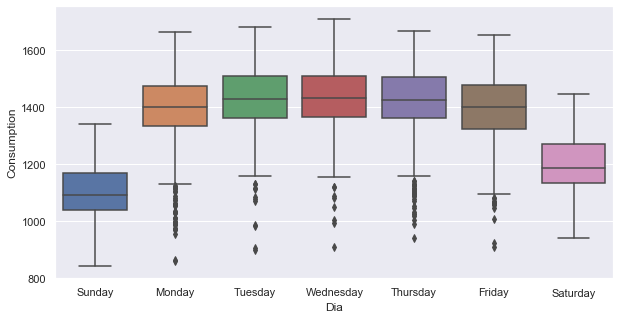
Como se esperaba, el consumo de electricidad es significativamente mayor en los días de semana que en los fines de semana. Los valores atípicos bajos en los días de semana son presumiblemente durante los días festivos.
Esta sección ha proporcionado una breve introducción a la estacionalidad de las series temporales. Como se verá más adelante, la aplicación de una ventana deslizante a los datos también puede ayudar a visualizar la estacionalidad en diferentes escalas de tiempo. Otras técnicas para analizar la estacionalidad incluyen diagramas de autocorrelación, que trazan los coeficientes de correlación de las series temporales consigo mismas en diferentes intervalos de tiempo.
Las series temporales con una fuerte estacionalidad a menudo se pueden representar bien con modelos que descomponen la señal en estacionalidad y en una tendencia a largo plazo, y estos modelos se pueden usar para pronosticar los valores futuros de las series temporales. Un ejemplo simple de tal modelo es la descomposición estacional clásica. Un ejemplo más sofisticado es el modelo Prophet de Facebook, que utiliza el ajuste de curvas para descomponer las series de tiempo, teniendo en cuenta la estacionalidad en múltiples escalas de tiempo, efectos de vacaciones, puntos de cambio abruptos y tendencias a largo plazo.
El código final de los gráficos de esta parte es:
1er Gráfico de estacionalidad
import pandas as pnd
import matplotlib.pyplot as mplt
import seaborn as sbn
opsd_dia = pnd.read_csv('opsd_germany_daily.csv', index_col=0, parse_dates=True)
opsd_dia['Mes'] = opsd_dia.index.month
sbn.set(rc={'figure.figsize':(10, 5)})
# 1er Gráfico
fig, ejes = mplt.subplots(3, 1, figsize=(11, 10), sharex=True)
for nombre, eje in zip(['Consumption','Solar','Wind'], ejes):
sbn.boxplot(data=opsd_dia,x='Mes',y=nombre,ax=eje)
eje.set_title(nombre)
if eje != ejes[-1]:
eje.set_xlabel('')
2do Gráfico de estacionalidad
import pandas as pnd
import matplotlib.pyplot as mplt
import seaborn as sbn
opsd_dia = pnd.read_csv('opsd_germany_daily.csv', index_col=0, parse_dates=True)
opsd_dia['Dia'] = opsd_dia.index.weekday_name
sbn.set(rc={'figure.figsize':(10, 5)})
# 2do Gráfico
sbn.boxplot(data=opsd_dia, x='Dia', y='Consumption')
Frecuencias
Cuando los datos de una serie temporal están distanciados en el tiempo de forma uniforme (por ejemplo, cada semana hay una baja en el consumo de corriente eléctrica en una localidad determinada.), la serie puede asociarse con una frecuencia en pandas. Por ejemplo, con la función date_range() se creará una secuencia de fechas espaciadas uniformemente desde 2015-09-15 hasta 2015-09-20 a una frecuencia diaria.
>>> pnd.date_range('2015-09-15','2015-09-20',freq='D')
DatetimeIndex(['2015-09-15', '2015-09-16', '2015-09-17', '2015-09-18',
'2015-09-19', '2015-09-20'], dtype='datetime64[ns]', freq='D')
El DatetimeIndex resultante tiene un atributo de frecuencia (freq) con un valor de ‘D’, que indica la frecuencia diaria. Las frecuencias disponibles de pandas incluyen cada hora (‘H’), calendario diario (‘D’), diario de negocios (‘B’), semanal (‘W’), mensual (‘M’), trimestral (‘Q’), anual (‘A’), y muchos otros. Las frecuencias también se pueden especificar como múltiplos de cualquiera de las frecuencias base, por ejemplo, ‘5D’ por cada cinco días.
Como ejemplo secundario, se creara otro rango de fechas con frecuencia de una hora, especificando la fecha de inicio y el numero de periodos en lugar de la fecha de inicio y fecha de finalización.
>>> pnd.date_range('2005-10-15', periods=8, freq='H')
DatetimeIndex(['2005-10-15 00:00:00', '2005-10-15 01:00:00',
'2005-10-15 02:00:00', '2005-10-15 03:00:00',
'2005-10-15 04:00:00', '2005-10-15 05:00:00',
'2005-10-15 06:00:00', '2005-10-15 07:00:00'],
dtype='datetime64[ns]', freq='H')
A continuación, se revisará el DatatimeIndex de la serie de tiempo opsd_dia.
>>> opsd_dia.index
DatetimeIndex(['2006-01-01', '2006-01-02', '2006-01-03', '2006-01-04',
'2006-01-05', '2006-01-06', '2006-01-07', '2006-01-08',
'2006-01-09', '2006-01-10',
...
'2017-12-22', '2017-12-23', '2017-12-24', '2017-12-25',
'2017-12-26', '2017-12-27', '2017-12-28', '2017-12-29',
'2017-12-30', '2017-12-31'],
dtype='datetime64[ns]', name='Date', length=4383, freq=None)
Se puede ver que no tiene frecuencia (freq=None). Esto tiene sentido, ya que el índice se creó a partir de una secuencia de fechas en el archivo CSV, sin especificar frecuencia para la serie temporal.
Si se sabe que los datos deben estar en una frecuencia específica, se puede usar el método asfreq() de DataFrame para asignar una frecuencia. Si falta alguna fecha/hora en los datos, se agregarán nuevas filas para esas fechas/horas, que están vacías (NaN) o se llenan de acuerdo con un método de llenado de datos específico, como el llenado hacia adelante o la interpolación.
Para conocer el funcionamiento de esto, se creará un nuevo DataFrame que contenga solo los datos de Consumo del 2, 4 y 6 de marzo de 2010.
>>> muestra_tiempo = pnd.to_datetime(['2010-03-02','2010-03-04','2010-03-06'])
>>> muestra_consumo = opsd_dia.loc[muestra_tiempo,['Consumption']].copy()
>>> muestra_consumo
Consumption
2010-03-02 1572.645
2010-03-04 1548.184
2010-03-06 1310.888
Ahora con el método asfreq() se convertirá el DataFrame a una frecuencia diaria, con una columna con datos incompletos y una columna con los datos luego de ser ingresados con forward fill (ffill).
>>> frec_consumo = muestra_consumo.asfreq('D')
>>> frec_consumo['Consumption - Datos llenos'] = muestra_consumo.asfreq('D', method='ffill')
>>> frec_consumo
Consumption Consumption - Datos llenos
2010-03-02 1572.645 1572.645
2010-03-03 NaN 1572.645
2010-03-04 1548.184 1548.184
2010-03-05 NaN 1548.184
2010-03-06 1310.888 1310.888
En la columna de consumo, “Consumption”, se encuentran los datos originales, con un valor de NaN para cualquier fecha que faltaba en el DataFrame de muestra (muestra_consumo). En la última columna (Consumption – Datos llenos), los datos faltantes se han “rellenado hacia adelante”, lo que significa que el último valor se repite en las filas faltantes hasta que se produce el siguiente valor no faltante.
Si se está realizando algún análisis de series temporales que requiera datos espaciados uniformemente sin faltas, es recomendable utilizar asfreq() para convertir series temporales a la frecuencia especificada y completar los datos que falten con el método apropiado.
Remuestreo
A menudo es útil aplicar el remuestreo en datos de series temporales a una frecuencia más baja o más alta. El remuestreo a una frecuencia más baja (submuestreo) generalmente implica una operación de recolección o sumatoria, por ejemplo, calcular la distancia recorrida por un autobús en un mes, tomando las distancias que recorrió cada día de dicho mes. El remuestreo a una frecuencia más alta (sobremuestreo) es menos común y, a menudo, implica la interpolación, aproximación u otro método de llenado de datos.
Esta sección estará centrada en el submuestreo, y cómo puede ayudar en el análisis de los datos de OPSD en varias escalas de tiempo. Se utilizará el método resample() del DataFrame, que divide el DatetimeIndex en intervalos de tiempo y agrupa los datos por intervalo de tiempo. El método resample() devuelve un objeto Resampler, similar al objeto de pandas GroupBy. Luego se puede aplicar un método de agregación como mean() (calcula la media), median() (calcula la mediana), sum() (calcula la suma), entre otros, al grupo de datos para cada intervalo de tiempo.
Se aplicará remuestreo a los datos para la media semanal de una serie temporal.
>>> columnas = ['Consumption','Wind','Solar','Wind+Solar']
>>> media_opsd_semanal = opsd_dia[columnas].resample('W').mean()
>>> media_opsd_semanal.head(3)
Consumption Wind Solar Wind+Solar
Date
2006-01-01 1069.184000 NaN NaN NaN
2006-01-08 1381.300143 NaN NaN NaN
2006-01-15 1486.730286 NaN NaN NaN
La primera, etiquetada 2006-01-01, contiene la media de todos los datos contenidos en el intervalo de tiempo 2006-01-01 hasta 2006-01-07. La segunda fila, etiquetada 2006-01-08, contiene los datos promedio para el intervalo de tiempo 2006-01-08 hasta 2006-01-14, y así sucesivamente. De forma predeterminada, cada fila de la serie temporal submuestreada se etiqueta con el borde izquierdo del intervalo de tiempo.
Por construcción, la serie de tiempo semanal tiene 1/7 tantos puntos de datos como las series temporales diarias. Se puede confirmar esto comparando el número de filas de los dos DataFrames.
>>> opsd_dia.shape[0] 4383 >>> media_opsd_semanal.shape[0] 627
Se trazarán las series temporales diarias y semanales para la energía solar (Solar) juntas en un solo período de seis meses para compararlas.
inicio, final = '2015-06','2015-12'
fig,eje = mplt.subplots()
eje.plot(opsd_dia.loc[inicio:final,'Solar'],marker='.',linestyle='-',linewidth=0.5,label='Diario')
eje.plot(media_opsd_semanal.loc[inicio:final,'Solar'],marker='o',markersize=5,label='Semanal')
eje.set_ylabel('Producción Solar (GWh)')
eje.legend()
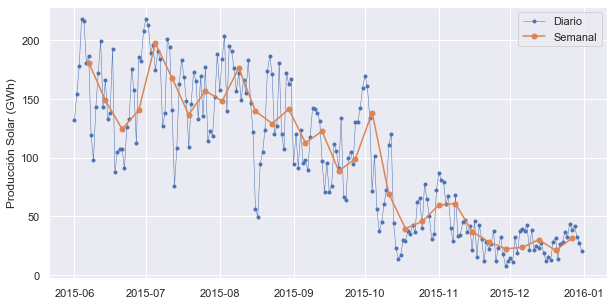
Se puede observar que las medias para las series temporales semanales son más suaves que para las series temporales diarias porque se ha promediado una variabilidad de frecuencia más alta en el remuestreo.
Ahora se hará nuevamente un remuestreo a los datos a una frecuencia mensual, agregando sumas totales en lugar de la media. A diferencia de la agregación con mean(), que establece la salida en NaN para cualquier período con todos los datos faltantes, el comportamiento predeterminado de sum() devolverá la salida de 0 como la suma de los datos faltantes. Se utilizará el parámetro min_count para cambiar este comportamiento.
>>> opsd_mensual = opsd_dia[columnas].resample('M').sum(min_count=28)
>>> opsd_mensual.head(4)
Consumption Wind Solar Wind+Solar
Date
2006-01-31 45304.704 NaN NaN NaN
2006-02-28 41078.993 NaN NaN NaN
2006-03-31 43978.124 NaN NaN NaN
2006-04-30 38251.767 NaN NaN NaN
Se puede notar que los datos remuestreados mensualmente están etiquetados con el final de cada mes (el limite derecho del intervalo), mientras que los datos remuestreados semanalmente están etiquetados con el inicio de cada semana. De forma predeterminada, los datos remuestreados se etiquetan con el límite derecho para las frecuencias mensuales, trimestrales y anuales, y con el límite izquierdo para todas las demás frecuencias. Este comportamiento y otras opciones se pueden ajustar utilizando los parámetros enumerados en la documentación de resample().
Ahora se explorarán las series temporales mensuales trazando el consumo de electricidad como un diagrama de línea, y la producción de energía eólica y solar juntas como un gráfico de área apilada.
fig,eje = mplt.subplots()
eje.plot(opsd_mensual['Consumption'],color='black',label='Consumo')
opsd_mensual[['Wind','Solar']].plot.area(ax=eje,linewidth=0)
eje.legend()
eje.set_ylabel('Total Mensual (GWh)')
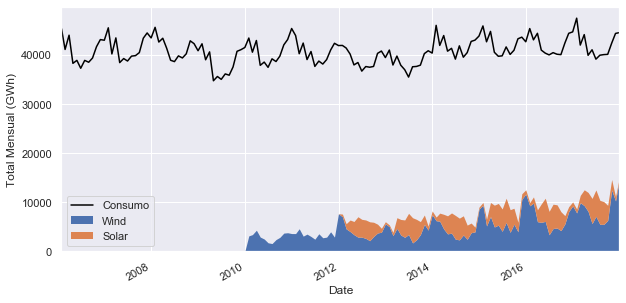
En esta escala de tiempo mensual, se observa claramente la estacionalidad anual en cada serie, y también es evidente que el consumo de electricidad se ha mantenido bastante estable a lo largo del tiempo, mientras que la producción de energía eólica ha crecido constantemente, con la suma de energía eólica y solar (Wind+Solar) que comprende una parte cada vez mayor de la electricidad consumida.
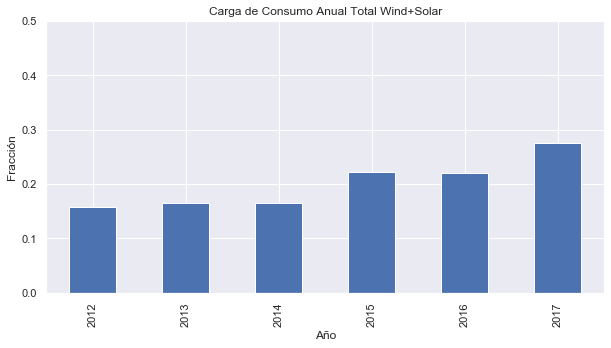
Haciendo un remuestreo a la frecuencia anual y calculando la relación de la producción de energía eólica y energía solar (Wind+Solar) con consumo (Consumption) para cada año se profundizará en este tema.
>>> opsd_anual = opsd_dia[columnas].resample('A').sum(min_count=360)
>>> opsd_anual = opsd_anual.set_index(opsd_anual.index.year)
>>> opsd_anual.index.name='Año'
>>> opsd_anual['Wind+Solar/Consumo'] = opsd_anual['Wind+Solar'] / opsd_anual['Consumption']
>>> opsd_anual.tail(4)
Consumption Wind Solar Wind+Solar Wind+Solar/Consumo
Año
2014 504164.82100 51107.672 32498.307 83370.502 0.165364
2015 505264.56300 77468.994 34907.138 112376.132 0.222410
2016 505927.35400 77008.126 34562.824 111570.950 0.220528
2017 504736.36939 102667.365 35882.643 138550.008 0.274500
Finalmente, se trazará la carga de la producción de energía eólica y solar (Wind+Solar) del consumo anual de electricidad en un gráfico de barras.
# El gráfico comienza en 2012, ya que antes de 2012 no
# había producción de energía solar
eje = opsd_anual.loc[2012:,'Wind+Solar/Consumo'].plot.bar()
eje.set_ylabel('Fracción')
eje.set_ylim(0,0.5)
eje.set_title('Carga de Consumo Anual Total Wind+Solar')
El código final de los gráficos de esta parte es:
1er y 2do Gráfico de Remuestreo
import pandas as pnd
import matplotlib.pyplot as mplt
import seaborn as sbn
sbn.set(rc={'figure.figsize':(10, 5)})
opsd_dia = pnd.read_csv('opsd_germany_daily.csv', index_col=0, parse_dates=True)
columnas = ['Consumption','Wind','Solar','Wind+Solar']
media_opsd_semanal = opsd_dia[columnas].resample('W').mean()
opsd_mensual = opsd_dia[columnas].resample('M').sum(min_count=28)
# 1er Gráfico
inicio, final = '2015-06','2015-12'
fig,eje = mplt.subplots()
eje.plot(opsd_dia.loc[inicio:final,'Solar'],marker='.',linestyle='-',linewidth=0.5,label='Diario')
eje.plot(media_opsd_semanal.loc[inicio:final,'Solar'],marker='o',markersize=5,label='Semanal')
eje.set_ylabel('Producción Solar (GWh)')
eje.legend()
# 2do Gráfico
fig,eje = mplt.subplots()
eje.plot(opsd_mensual['Consumption'],color='black',label='Consumo')
opsd_mensual[['Wind','Solar']].plot.area(ax=eje,linewidth=0)
eje.legend()
eje.set_ylabel('Total Mensual (GWh)')
3er Gráfico de Remuestreo
import pandas as pnd
import matplotlib.pyplot as mplt
import seaborn as sbn
sbn.set(rc={'figure.figsize':(10, 5)})
opsd_dia = pnd.read_csv('opsd_germany_daily.csv', index_col=0, parse_dates=True)
# 3er Gráfico
opsd_anual = opsd_dia[columnas].resample('A').sum(min_count=360)
opsd_anual = opsd_anual.set_index(opsd_anual.index.year)
opsd_anual.index.name='Año'
opsd_anual['Wind+Solar/Consumo'] = opsd_anual['Wind+Solar'] / opsd_anual['Consumption']
eje = opsd_anual.loc[2012:,'Wind+Solar/Consumo'].plot.bar()
eje.set_ylabel('Fracción')
eje.set_ylim(0,0.5)
eje.set_title('Carga de Consumo Anual Total Wind+Solar')
Ventanas Deslizantes
Las operaciones de ventanas deslizantes son otra transformación importante para los datos de series temporales. De manera similar al submuestreo, las ventanas deslizantes dividen los datos en ventanas de tiempo y los datos de cada ventana se agregan con una función como mean(), median(), sum(), entre otras. Sin embargo, a diferencia del submuestreo, donde los intervalos de tiempo no se superponen y la salida se encuentra a una frecuencia más baja que la entrada, las ventanas deslizantes se superponen y “deslizan” a la misma frecuencia que los datos, por lo que las series temporales transformadas tienen la misma frecuencia que las series temporales originales.
De forma predeterminada, todos los datos dentro de una ventana tienen la misma ponderación en la sumatoria, pero esto se puede cambiar especificando tipos de ventana como Gaussiana, triangular y otras. Nos quedaremos con la ventana de ponderación estándar aquí.
Con el método rolling() se calcula la media deslizante de 7 días de datos diarios. Usando el argumento center=True, se etiqueta cada ventana en su punto medio, por lo que las ventanas deslizantes serán:
- 2006-01-01 a 2006-01-07 – etiquetado como 2006-01-04
- 2006-01-02 a 2006-01-08 – etiquetado como 2006-01-05
- 2006-01-03 a 2006-01-09 – etiquetado como 2006-01-06
- y así sucesivamente.
>>> opsd_7d = opsd_dia[columnas].rolling(7, center=True).mean()
>>> opsd_7d.head(5)
Consumption Wind Solar Wind+Solar
Date
2006-01-01 NaN NaN NaN NaN
2006-01-02 NaN NaN NaN NaN
2006-01-03 NaN NaN NaN NaN
2006-01-04 1361.471429 NaN NaN NaN
2006-01-05 1381.300143 NaN NaN NaN
Para visualizar las diferencias entre la media deslizante y el remuestreo, se actualiza el gráfico anterior de la producción de energía solar de junio a diciembre de 2015 para incluir la media deslizante de 7 días junto con las series de tiempo remuestreadas medias semanales y los datos diarios originales.
import pandas as pnd
import matplotlib.pyplot as mplt
import seaborn as sbn
sbn.set(rc={'figure.figsize':(10, 5)})
opsd_dia = pnd.read_csv('opsd_germany_daily.csv', index_col=0, parse_dates=True)
opsd_7d = opsd_dia[columnas].rolling(7, center=True).mean()
inicio, final='2015-06','2015-12'
fig, eje = mplt.subplots()
eje.plot(opsd_dia.loc[inicio:final, 'Solar'],marker='.',linestyle='-', linewidth=0.5,label='Diario')
eje.plot(media_opsd_semanal.loc[inicio:final,'Solar'],marker='o',linestyle='-', linewidth=0.5,label='Semanal')
eje.plot(opsd_7d.loc[inicio:final,'Solar'],marker='.',linestyle='-', linewidth=0.5,label='Media Deslizante de 7 Dias')
eje.set_ylabel('Producción Solar (GWh)')
eje.legend()
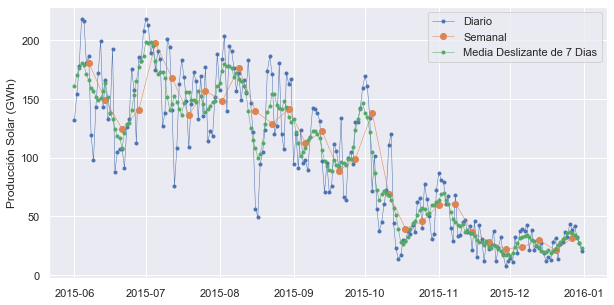
Se puede ver que los puntos de datos en la serie temporal de la media deslizante tienen el mismo espacio que los datos diarios, pero la curva es más suave porque se ha promediado una mayor variabilidad de frecuencia. En las series temporales de media deslizante, los picos y valles tienden a alinearse estrechamente con los picos y valles de las series temporales diarias. En contraste, los picos y valles en las series de tiempo remuestreadas semanalmente se alinean menos estrechamente con las series temporales diarias, ya que las series remuestreadas tienen una granularidad más gruesa.
Tendencias
Los datos de series temporales a menudo muestran una variabilidad lenta y gradual, además de una variabilidad de frecuencia más alta, como la estacionalidad y el ruido. Una forma fácil de visualizar estas tendencias es con medias deslizantes en diferentes escalas de tiempo.
Una media deslizante tiende a suavizar una serie temporal promediando las variaciones en frecuencias mucho más altas que el tamaño de la ventana y promediando cualquier estacionalidad en una escala de tiempo igual al tamaño de la ventana. Esto permite explorar variaciones de baja frecuencia en los datos. Dado que la serie temporal que está siendo utilizada tiene estacionalidad semanal y anual, se verán las medias deslizantes en esas dos escalas de tiempo.
Ya se han calculado las medias deslizantes de 7 días, por lo que ahora se calculará la media deslizante de 365 días de los datos de OPSD.
# El argumento min_periods=360 toma en cuenta # algunos dias faltantes en las medidas de energía solar # y eólica opsd_365d = opsd_dia[columnas].rolling(window=365,center=True,min_periods=360).mean()
El gráfico de esto sería:
import pandas as pnd
import matplotlib.pyplot as mplt
import seaborn as sbn
sbn.set(rc={'figure.figsize':(10, 5)})
opsd_dia = pnd.read_csv('opsd_germany_daily.csv', index_col=0, parse_dates=True)
opsd_365d = opsd_dia[columnas].rolling(window=365,center=True,min_periods=360).mean()
opsd_7d = opsd_dia[columnas].rolling(7, center=True).mean()
fig, eje = mplt.subplots()
eje.plot(opsd_dia['Consumption'], marker='.', markersize=2, color='0.6',
linestyle='None', label='Diario')
eje.plot(opsd_7d['Consumption'], linewidth=2, label='Media deslizante semanal')
eje.plot(opsd_365d['Consumption'], color='0.2', linewidth=3,
label='Tendencia (Media deslizante anual)')
eje.legend()
eje.set_xlabel('Año')
eje.set_ylabel('Consumo (GWh)')
eje.set_title('Tendencias en el Consumo Electrico')
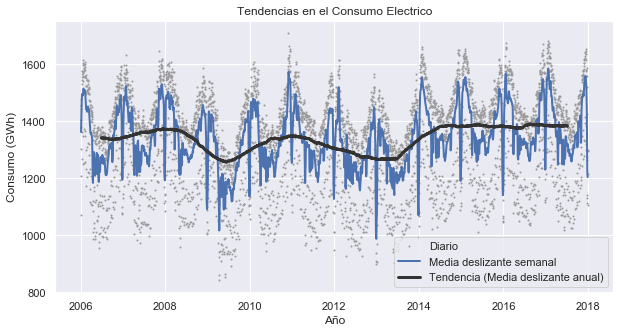
Se puede notar que la media deslizante de 7 días ha suavizado toda la estacionalidad semanal, al tiempo que conserva la estacionalidad anual. La media deslizante de 7 días revela que, si bien el consumo de electricidad suele ser mayor en invierno y en verano, hay una disminución dramática durante algunas semanas cada invierno a fines de diciembre y principios de enero, durante las vacaciones.
Si se observan las series temporales de media deslizante de 365 días, es notable que la tendencia a largo plazo en el consumo de electricidad es bastante plana, con un par de períodos de consumo anormalmente bajos entre 2009 y 2012-2013.
Se observarán las tendencias en la producción eólica y solar.
fig,eje= mplt.subplots()
for i in ['Wind','Solar','Wind+Solar']:
eje.plot(opsd_365d[i],label=i)
eje.set_ylim(0,500)
eje.legend()
eje.set_ylabel('Producción (GWh)')
eje.set_title('Tendencias en la Producción de electricidad')
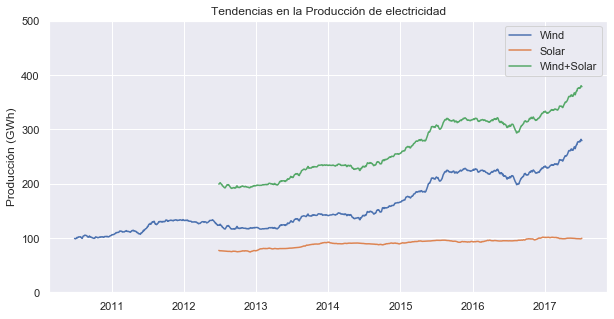
Se puede ver una pequeña tendencia creciente en la producción de energía solar y una gran tendencia creciente en la producción de energía eólica, a medida que Alemania continúa expandiendo su capacidad en ambos sectores.
El código del apartado de Tendencias sería:
import pandas as pnd
import matplotlib.pyplot as mplt
import seaborn as sbn
sbn.set(rc={'figure.figsize':(10, 5)})
opsd_dia = pnd.read_csv('opsd_germany_daily.csv', index_col=0, parse_dates=True)
opsd_365d = opsd_dia[columnas].rolling(window=365,center=True,min_periods=360).mean()
opsd_7d = opsd_dia[columnas].rolling(7, center=True).mean()
# 1er Gráfico
fig, eje = mplt.subplots()
eje.plot(opsd_dia['Consumption'], marker='.', markersize=2, color='0.6',
linestyle='None', label='Diario')
eje.plot(opsd_7d['Consumption'], linewidth=2, label='Media deslizante semanal')
eje.plot(opsd_365d['Consumption'], color='0.2', linewidth=3,
label='Tendencia (Media deslizante anual)')
eje.legend()
eje.set_xlabel('Año')
eje.set_ylabel('Consumo (GWh)')
eje.set_title('Tendencias en el Consumo Electrico')
# 2do Gráfico
fig,eje= mplt.subplots()
for i in ['Wind','Solar','Wind+Solar']:
eje.plot(opsd_365d[i],label=i)
eje.set_ylim(0,500)
eje.legend()
eje.set_ylabel('Producción (GWh)')
eje.set_title('Tendencias en la Producción de electricidad')
Excelente aporte!