
Blog
Muy buenas, hoy os traigo un análisis de datos con la libreria Pandas !
Dar una introducción a la librería para análisis de datos con Python: Pandas
Usar la librería Pandas para el análisis de los datos del Brexit del Reino Unido
¿Que es Pandas?
Pandas es una biblioteca de software escrita en Python para la manipulación y análisis de datos. En particular, ofrece estructuras de datos y operaciones para manipular tablas numéricas y series temporales. Pandas es un software libre y gratis ?. El nombre se deriva del término “datos de panel”, de ahi Pandas ?
Análisis de datos del Brexit de UK
Para analizar datos necesitamos datos, muuuuuchos datos… y que mejor que los datos de un gobierno ya que son fiables y normalmente siempre estan muy bien organizados, asi que vamos a analizar los datos de Brexit de UK ocurridos el dia 23 de Junio de 2016, empezamos!
*Si no sabes lo que es el Brexit de UK te invito a leer este artículo
Datos del Brexit de UK
- Descárgate todos los datos que vamos a usar desde aqui.
Fuente de los datos
Estos datos son públicos y han sido descargados desde las siguientes fuentes (gobierno UK):
- https://www.electoralcommission.org.uk/find-information-by-subject/elections-and-referendums/upcoming-elections-and-referendums/eu-referendum/electorate-and-count-information
- http://webarchive.nationalarchives.gov.uk/20160105160709/http://www.ons.gov.uk/ons/publications/re-reference-tables.html?edition=tcm%3A77-286262
Análisis de datos del Brexit de UK parte I
import pandas as pd
#importamos los datos yo me lo he bajado de esta web:
#https://www.electoralcommission.org.uk/find-information-by-subject/elections-and-referendums/upcoming-elections-and-referendums/eu-referendum/electorate-and-count-information
df = pd.read_csv("C:/Users/Desktop/Curso de AprednerPython/Ejercicio-Brexit/EU-referendum-result-data.csv")
# vamos a sumar quien esta a favor de la UE y quien no
noUE = df["Leave"].sum()
siUE = df["Remain"].sum()
print("no UE: {} votantes | si UE {} votantes".format(noUE, siUE))
#calculamos los porcentajes
porcennoUE=noUE / (siUE + noUE) *100
porcensiUE=siUE / (noUE + siUE) *100
print("Porcentage del no a UE: {} y del si a UE {}".format(porcennoUE, porcensiUE))
#calculamos el censo, porcentage de votantes y rechazados
censo = df['Electorate'].sum();
porcenvotantes = (noUE + siUE) / censo * 100;
rechazados = df.Rejected_Ballots.sum();
print("El censo es: {}, el procentage de votantes es {} y el numero de rechazados es {}".format(censo, porcenvotantes, rechazados))
Comparacion de resultados
Antes de seguir vamos a comparar nuestros resultados para ver que son cocherentes. Nuestros resultados son:
“Porcentage del no a UE: 51.891841981441154 y del si a UE 48.108158018558846”
y si comparamos este artículo podemos corroborar que los datos son correctos, asi que seguimos con el análisis!
¿Cual serán los condados mas a favor la UE y cuales serán lo menos?
Vamos a graficar estos resultados:
#con matplotlib vamos hacer 3 graficas
# la primera son las 8 Areas al no UE
dfa = df.groupby("Area").sum()
dfa.head()
dfa["Perc_noUE"] = dfa["Leave"] / (dfa["Remain"] + dfa["Leave"]) * 100
dfa["Perc_siUE"] = dfa["Remain"] / (dfa["Remain"] + dfa["Leave"]) * 100
dfa.head(3)
top5_noUE = dfa[["Perc_noUE", "Perc_siUE"]].sort_values(by="Perc_noUE", ascending=False)[0:8]
top5_noUE.head()
plt1 = top5_noUE.plot(kind="bar")
plt1.legend(loc='center left', bbox_to_anchor=(1, 0.5))
# la segunda son las 8 Areas al si UE
top5_siUE = dfa[["Perc_noUE", "Perc_siUE"]].sort_values(by="Perc_noUE", ascending=False)[-8:]
top5_siUE.head()
plt2 = top5_siUE.plot(kind="bar")
plt2.legend(loc='center left', bbox_to_anchor=(1, 0.5))
# la tercera son las 8 Areas al si UE y las 8 areas al no UE
dfr = df.groupby("Region").sum()
dfr["Perc_noUE"] = dfr["Leave"] / (dfr["Remain"] + dfr["Leave"]) * 100
dfr["Perc_siUE"] = dfr["Remain"] / (dfr["Remain"] + dfr["Leave"]) * 100
dfr[["Perc_noUE", "Perc_siUE"]].sort_values(by="Perc_noUE", ascending=False).plot(kind="bar")
Resultados Análisis de datos del Brexit de UK parte I
Estos son los resultados de nuestro análisis:

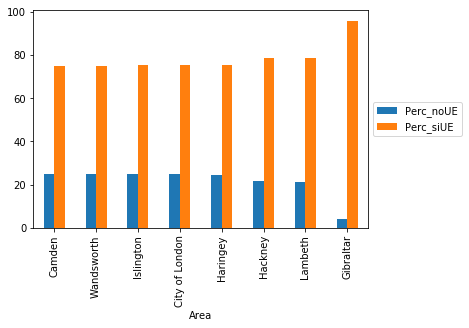

En este primer análisis hemos podido analizar por áreas y regiones mas a favor de la UE y los menos, también hemos comprobado que nuestros datos son correctos si los comparamos con los datos publicados en la wikipedia sobre el Brexit. Hemos visto áreas como Gibraltar o regiones tan importantes como Londres o Escocia que si quieren pertenerce a la UE . Por otro lado Boston y la región de Midlands Occidentales vemos una clara predilección por salir de la UE.
Análisis de datos del Brexit de UK parte II
Ahora vamos a dar un paso más y vamos a ver otras variables que también han influido en ese voto como puede ser:
- Edad
- Nivel de educacion
- Gente de UK que no vive en UK
- Ingresos salariales
- Gente sin trabajo
Con estas variables el análisis se vuelve mas interesante porque podemos saber:
- si los jóvenes o mayores quieren quedarse o salir de la UE
- si el nivel de educación es importante la hora de si UE o no UE
- que piensa la población acerca del Brexit si tienes un salario alto o en cambio no tienes empleo
La mayoría de estos factores son determinates para conocer a la población y pensar un poco mas allá del resultado final.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.ticker as ticker
#matplotlib inline
census_data = {
"age" : "r21ewrttableks102ewladv1_tcm77-290566.xls",
"unemployment" : "r21ewrttableks601ewladv1_tcm77-290745.xls",
"education" : "r21ewrttableks501ewladv1_tcm77-290734.xls",
"outside_uk" : "r21ewrttableqs203ewladv1_tcm77-290919.xls",
}
votes_org = pd.read_csv("C:/Users/Desktop/Curso de AprednerPython/Ejercicio-Brexit/EU-referendum-result-data.csv", usecols=["Area_Code", "Region", "Remain", "Leave"] ) #no olvides poner donde tienes el #archivo
votes_org.rename(index=str, inplace=True, columns={"Area_Code": "Area code", }) # same col name for merge
votes_org["votes"] = votes_org["Remain"] - votes_org["Leave"]
votes = votes_org[["Area code", "votes"]]
votes.head(2)
edad = pd.read_excel(io=census_data["age"], sheetname="KS102EW_Numbers", header=10, parse_cols=("A,W"), skiprows=[11,12,13])
edad.dropna(how='all', inplace=True)
edad.rename(index=str, inplace=True, columns={"Median age": "median_age", })
edad = edad[["Area code", "median_age"]]
edad.head(2)
desempleo = pd.read_excel(io=census_data["unemployment"], sheetname="KS601EW_Numbers", header=10, parse_cols=("A,E,I"), skiprows=[11,12,13])
desempleo.dropna(how='all', inplace=True)
desempleo["perc_unemployed"] = desempleo[desempleo.columns[2]] / desempleo[desempleo.columns[1]]
desempleo = desempleo[["Area code", "perc_unemployed"]]
desempleo.head(2)
educacion = pd.read_excel(io=census_data["education"], sheetname="KS501EW_Numbers", header=10, parse_cols=("A,E,J,K"), skiprows=[11,12,13])
educacion.dropna(how='all', inplace=True)
educacion["perc_high_education"] = (educacion[educacion.columns[2]] + educacion[educacion.columns[3]]) / educacion[educacion.columns[1]]
educacion = educacion[["Area code", "perc_high_education"]]
educacion.head(2)
fuera_uk = pd.read_excel(io=census_data["outside_uk"], sheetname="QS203EW_Numbers", header=10, parse_cols=("A,E,G"), skiprows=[11,12,13])
fuera_uk.dropna(how='all', inplace=True)
fuera_uk.columns[2]
fuera_uk["perc_born_outside_uk"] = (fuera_uk[fuera_uk.columns[1]] - fuera_uk[fuera_uk.columns[2]]) / fuera_uk[fuera_uk.columns[1]]
fuera_uk = fuera_uk[["Area code", "perc_born_outside_uk"]]
fuera_uk.head(2)
data = votes.merge(edad, on='Area code').merge(desempleo, on='Area code').merge(educacion, on='Area code').merge(fuera_uk, on='Area code')
data.head(5)
100 - ((len(votes) - len(data)) / len(votes)*100)
#hacemos una funcion para plotear
def showplot(data, factor,factor2):
fig = plt.figure(figsize=(6, 6))
ax = fig.add_subplot(1,1,1)
ax.scatter(data["votes"], data[factor], s=20, c='r', marker="o", label=factor2)
plt.legend(loc='upper left');
plt.xlabel("votos (< 0 = noUE / > 0 = siUE)")
plt.ylabel(factor2)
plt.axvline(x=0)
plt.axhline(y=data[factor].mean())# linea horizontal en la media de los datos
plt.show()
fig.savefig(factor+".png")
showplot(data, "median_age", "media_edad")
showplot(data, "perc_unemployed", "%_desempleados")
showplot(data, "perc_high_education", "%_alta_educacion")
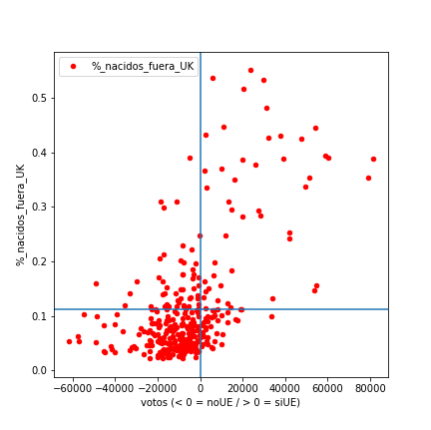
showplot(data, "perc_born_outside_uk","%_nacidos_fuera_UK" )
votes_region = votes_org.groupby("Region").sum()
votes_region.head(2)
len(votes_region)
Resultados Análisis de datos del Brexit de UK parte II
 Podemos decir que la gente mayor prefiere salir de UE
Podemos decir que la gente mayor prefiere salir de UE 
Esta gráfica es una de las mas claras, personas con menos estudios o peor nivel cultural prefieren salir de UE
Mientras mas desempleo hay, más quieren estar fuera de la UE. 
Esta gráfica es muy clara también y nos dice que hay un alto porcentage de que si has nacido en UK prefieres salir de la UE
# Obtenemos el ingreso medio por área / condado (están en la misma columna, pero la fusión posterior lo arreglará)
salarios_archivo = "C:/Users/Desktop/Curso de AprednerPython/Ejercicio-Brexit/Table_3_13_14.xlsx" #no olvides poner donde tienes el #archivo
salarios = pd.read_excel(io=salarios_archivo, sheetname="Table_3_13_14", header=10, parse_cols=("A,U"), skiprows=[11,12,13], )
salarios.dropna(how='all', inplace=True)
salarios.rename(index=str, columns={salarios.columns[0]: "Region", salarios.columns[1]: "median_income"}, inplace=True)
salarios.set_index("Region", inplace=True)
salarios.head(5)
# Los datos de ingresos tienen espacios en blanco para combinar no coincide, limpiamos los espacios en blanco
salarios.index = salarios.index.str.strip()
# Perdemos 2 regiones, aceptando que por ahora
[i for i in votes_region.index if i not in salarios.index]
# Combinar los conjuntos de datos de votos e ingresos en los índices de su condado
votes_and_income = votes_region.merge(salarios, left_index=True, right_index=True, how='left')
votes_and_income.drop_duplicates(subset="Remain", keep="first", inplace=True)
votes_and_income = votes_and_income[votes_and_income["median_income"] > 0] # clean 2 NANs
votes_and_income
# No se puede reutilizar el método anterior de showplot, así que ajustaremos el código aquí
# Tuve que agregar FuncFormatter también porque el eje x tiene valores de voto mucho mayores, porque medimos
# Regiones (= más grande) en lugar de áreas (= más pequeñas) aquí
factor = "median_income"
fig = plt.figure(figsize=(10, 10))
ax = fig.add_subplot(1,1,1)
ax.scatter(votes_and_income["votes"], votes_and_income[factor], s=100, c='r', marker="o", label="media_ingresos_salariales")
ax.xaxis.set_major_formatter(ticker.FuncFormatter(lambda y, pos: ('%2d')%(y*1e-3)))
# muestra un punto y el nombre del condado
for i, txt in enumerate(votes_and_income.index):
ax.annotate(txt, (votes_and_income["votes"][i], votes_and_income[factor][i]),
horizontalalignment='right', verticalalignment='top',
bbox=dict(facecolor='none', edgecolor='black', boxstyle='round,pad=0.2'))
plt.legend(loc='upper left');
plt.xlabel("votos en 1000s (< 0 = noUE / > 0 = siUE)")
plt.ylabel("media_ingresos_salariales")
plt.axvline(x=0)
plt.axhline(y=votes_and_income[factor].mean()) # linea horizontal en la media de los datos
plt.show()
fig.savefig(factor+".png")

En conclusión podemos definir el perfil del votante de salir de la UE: ➡ Si has llegado hasta aquí enhorabuena. La librería Pandas es una de las herramientas principales en el análisis de datos con Python. Inicia tu camino como analista de datos con nuestro curso Python de análisis de datos:
Muy interesante, estoy empezando en este cautivador campo, la verdad me ha sorprendido la facilidad con la que se sacan los datos, el utilizar la librería Pandas, veo que facilita las cosas