
Blog
Cómo configurar los modelos de codificador-decodificador para la traducción automática
La arquitectura codificador-decodificador para redes neuronales recurrentes está logrando resultados de última generación en los estándares de traducción automática y se está utilizando en el corazón de los servicios de traducción industrial. El modelo es simple, pero dada la gran cantidad de datos requeridos para entrenarlo, ajustar el foco de decisiones de diseño en el modelo para obtener el máximo rendimiento en su problema puede ser prácticamente imposible. Afortunadamente, los científicos de investigación han utilizado hardware a escala de Google para hacer este trabajo para nosotros, y proporcionar un conjunto de heurísticas sobre cómo configurar el modelo codificador-decodificador para la traducción neuronal automática y para la predicción de secuencias en general.
En este capítulo, tú descubrirás los detalles de cómo configurar mejor una red neuronal recurrente codificador-decodificador para la traducción neuronal automática y otras tareas de procesamiento de lenguaje natural. Después de leer este capítulo, tú sabrás:
- El estudio de Google que investigó cada decisión de diseño de modelo en el modelo codificador-decodificador para aislar sus efectos.
- Los resultados y recomendaciones para las decisiones de diseño como la inserción de palabras, la profundidad del codificador y del decodificador, y los mecanismos de atención.
- Un conjunto de decisiones de diseño de modelos base que pueden ser utilizadas como punto de partida en sus propios proyectos de secuenciación a secuencia.
Vamos a empezar.
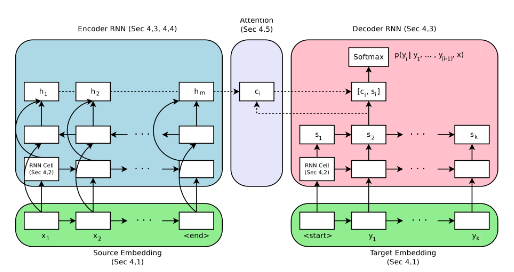
Modelo de codificador-decodificador para traducción automática neural
La arquitectura de codificador-decodificador para redes neuronales recurrentes está desplazando a los sistemas clásicos de traducción automática estadística basada en frases para obtener resultados de última generación. Como prueba, por su artículo de 2016 Neural Machine Translation System de Google: Para salvar la brecha entre la traducción humana y la traducción automática, Google utiliza ahora este enfoque en el núcleo de su servicio Google Translate.
Modelo de baseline
Podemos empezar describiendo el modelo de baseline utilizado como punto de partida para todos los experimentos.
Se eligió una configuración de baseline para que el modelo funcionara razonablemente bien en la tarea de traducción.
- Incrustación: 512-dimensiones.
- Célula RNN: Unidad de Recurrencia Gated o GRU.
- Codificador: Bidireccional.
- Profundidad del codificador: 2 capas (1 capa en cada dirección).
- Profundidad del decodificador: 2 capas.
- Atención: Al estilo Bahdanau.
- Optimizador: Adam
- Desconexión: 20% en la entrada.
Cada experimento comenzó con el modelo de baseline y varió un elemento en un intento de aislar el impacto de la decisión de diseño sobre la habilidad del modelo, en este caso, las puntuaciones BLEU.
Tamaño de incrustación de palabras
Se utiliza un incrustación de palabras para representar las palabras introducidas en el codificador. Esta es una representación distribuida donde cada palabra es mapeada a un vector de tamaño fijo de valores continuos. El beneficio de este enfoque es que diferentes palabras con un significado similar tendrán una representación similar. Esta representación distribuida se aprende a menudo al ajustar el modelo a los datos de la capacitación. El tamaño de incrustación define la longitud de los vectores utilizados para representar palabras. Generalmente se cree que una mayor dimensionalidad resultará en una representación más expresiva y, a su vez, en una mejor habilidad. Curiosamente, los resultados muestran que el tamaño más grande probado logró los mejores resultados, pero el beneficio de aumentar el tamaño fue menor en general.
Recomendación: Empieza con una pequeña incrustación, como 128, tal vez aumentes el tamaño más tarde para lograr una elevación menor de la habilidad.
Célula RNN Tipo
Generalmente hay tres tipos de células recurrentes de la red neural que se utilizan comúnmente:
- Simple RNN.
- Memoria Larga de Corto Plazo o LSTM.
- Unidad de Recurrencia Gated o GRU.
El LSTM fue desarrollado para abordar el problema del gradiente de desaparición de la RNN simple que limitaba el entrenamiento de las RNN profundas. El GRU fue desarrollado en un intento de simplificar el LSTM. Los resultados mostraron que tanto el GRU como el LSTM fueron significativamente mejores que el RNN Simple, pero el LSTM fue generalmente mejor en general.
Recomendación: Utiliza unidades LSTM RNN en tu modelo.
Profundidad del codificador-decodificador
Generalmente, se cree que las redes más profundas logran un mejor rendimiento que las redes poco profundas. La clave es encontrar un equilibrio entre la profundidad de la red, la habilidad del modelo y el tiempo de entrenamiento. Esto se debe a que generalmente no tenemos recursos infinitos para entrenar redes muy profundas si el beneficio de la habilidad es menor. Los autores exploran la profundidad de los modelos de codificador y decodificador y el impacto en la habilidad del modelo.
Cuando se trata de codificadores, se descubrió que la profundidad no tenía un impacto dramático en la habilidad y, lo que es más sorprendente, un modelo bidireccional de una capa sólo funciona ligeramente mejor que una configuración bidireccional de cuatro capas. Un codificador bidireccional de dos capas funcionó ligeramente mejor que otras configuraciones probadas.
Recomendación: Utiliza un codificador bidireccional de 1 capa y extiéndelo a 2 capas bidireccionales para un pequeño aumento de la habilidad.
Una historia similar se vio cuando se trataba de decodificadores. La habilidad entre los decodificadores con 1, 2 y 4 capas era diferente en una pequeña cantidad donde un decodificador de 4 capas era ligeramente mejor. Un decodificador de 8 capas no convergió bajo las condiciones de prueba.
Recomendación: Utiliza un decodificador de 1 capa como punto de partida y utiliza un decodificador de 4 capas para obtener mejores resultados.
Dirección de la entrada del codificador
El orden de la secuencia del texto fuente se puede proporcionar al codificador de varias maneras:
- Adelante o como de costumbre.
- Invertido.
- Tanto hacia adelante como hacia atrás al mismo tiempo.
Los autores exploraron el impacto del orden de la secuencia de entrada en la habilidad del modelo comparando varias configuraciones unidireccionales y bidireccionales. En general, confirmaron hallazgos anteriores de que una secuencia inversa es mejor que una secuencia hacia adelante y que una bidireccional es ligeramente mejor que una secuencia inversa.
Recomendación: Utiliza una secuencia de entrada de orden inverso o muévete a bidireccional para un pequeño aumento en la habilidad del modelo.
Mecanismo de atención
Un problema con el modelo ingenuo de codificador-decodificador es que el codificador asigna la entrada a una representación interna de longitud fija a partir de la cual el decodificador debe producir la secuencia de salida completa. La atención es una mejora del modelo que permite al decodificador prestar atención a las diferentes palabras de la secuencia de entrada a medida que sale cada palabra de la secuencia de salida. Los autores examinan algunas variaciones de los mecanismos de atención simples. Los resultados muestran que tener atención resulta en un rendimiento dramáticamente mejor que no tener atención.
La atención de estilo promedio ponderado simple descrita por Bahdanau, en su traducción automática neural de papel de 2015, aprendiendo a alinear y traducir conjuntamente, se encontró que era la que mejor funcionaba.
Recomendación: Usar la atención y preferir la atención de estilo Bahdanau ponderada de estilo promedio.
Inferencia
Es común en los sistemas de traducción automática neural utilizar una búsqueda por haz para muestrear las probabilidades de las palabras en la secuencia que el modelo produce. Cuanto mayor sea el ancho del haz, más exhaustiva será la búsqueda y, según se cree, mejores serán los resultados. Los resultados mostraron que un ancho de manga modesto de 3-5 rindió lo mejor, lo que sólo se pudo mejorar ligeramente mediante el uso de penalizaciones por longitud. Los autores generalmente recomiendan ajustar el ancho del haz a cada problema específico.
Recomendación: Comienza con una búsqueda codiciosa (beam=1) y sintoniza según tu problema.
Modelo Final
Los autores reúnen sus hallazgos en un solo modelo y comparan los resultados de este modelo con otros modelos de buen desempeño y resultados de vanguardia. Las configuraciones específicas de este modelo se resumen en la siguiente tabla, tomada del documento. Estos parámetros pueden ser tomados como un buen o mejor punto de partida cuando desarrolle su propio modelo de codificador-decodificador para una aplicación de PNL.
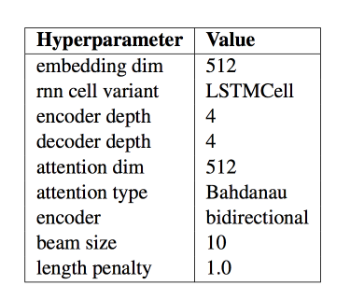
Es importante destacar que los autores proporcionan todo su código como un proyecto de código abierto llamado tf-seq2seq. Debido a que dos de los autores eran miembros del programa de residencia de Google Brain, su trabajo fue anunciado en el blog de Google Research con el título Introducing tf-seq2seq: An OpeSource Sequence-to-Sequence Framework in TensorFlow, 2017 (Presentación de tf-seq2seq: Un marco de trabajo de secuencia a secuencia de OpeSource en TensorFlow, 2017).
➡ Aprende mucho mas con nuestro curso de Procesamiento de Lenguaje Natural: